问题1:当int+int > MAX_INT && (int + int)/2 <= MAX_INT时,int = (int + int)/2是否合适?
这个问题的意思是当两个int型数据相加后的结果大于int所能表示的最大值,并且这两个数的和除2小于int所能表示的最大值时,执行int = (int + int)/2的表达式是否可行?
答案是:不可行,看下面代码:

解析:要想了解这个问题,就需要知道整型数据在内存中的存储。先来看看为什么预期结果与实际结果不同

结论:整型数据在内存中以补码的形式存储,如果运算过程中超出整型所能表示的范围,就会出现错误,在整型计算过程中要避免此类问题。
扩展:整型数据在内存中的存储
整型数据在内存中以补码的形式存储,整型数据在计算时也会按照补码的形式进行计算。例如,上面问题中2122222222+2122222222在内存中的存储和运算过程如下:

问题2:short类型的使用
判断下面两个程序那个更好?
程序1
void test1()
{
long long a = 2122222222;
long long b = 2122222222;
long long c;
c = (a+b)/2;
}
程序2
void test2()
{
unsigned int a = 2122222222;
unsigned int b = 2122222222;
unsigned int c;
c = (a + b) / 2;
}
上面两个程序的运行结果都没有任何问题,程序1中long long类型占8个字节而程序2中unsigned int 占4个字节。相比之下,显然程序2更好一些(这里如果使用int结果会出错),同时我们还会发现上面程序中的所有值都为正数。
结论:当正数在进行运算时,int型无法表示我们优先考虑使用unsigned int类型。例如:二分查找中,有些极端情况下使用int就会超出范围,这时我们就可以考虑使用unsigned int类型。当然,如果不是非常追究空间问题,直接使用long long也是没任何问题的。
例如:二分查找中,unsigned的使用
leetcode---第一个错误的版本
int firstBadVersion(int n) {
//版本号应该从1开始到n结束
unsigned int start,end,mid;
start = 1;
end = n;
mid = (start + end)/2;
while(!(isBadVersion(mid)&&!(isBadVersion(mid-1))))
{
if(isBadVersion(mid))
{
end = mid - 1;
mid = (start + end)/2;
}
else
{
start = mid + 1;
mid = (start + end)/2;
}
}
return mid;
}问题3:尽量避免int 、 unsigned int转换成float类型以及long long转换成float、double类型(与浮点数在内存中的存储有关)
我们知道在强制类型转换时,如果将一个较大数据类型转换成较小数据类型时可能会出现数据丢失问题。但是,要注意的是有些数据在转换成浮点型数据时也可能会出现数据丢失问题。
int、unsigned int和float在vs中都占四个字节,但在某些极端情况下也会出现数据丢失,例如:
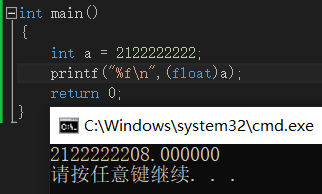
解析:任何一个浮点数都可以表示成(-1)^S*M*2^E的形式,其中S为1表示负数为0表示正数,M为有效数字(大于等于1小于2),2^E表示指数位。

double类型在内存中的存储与float类似,只是double类型的指数位为11位,数值位为52位。
结论:在一些极端情况下不要将int unsigned int转换成float类型,以及long long转换成double。