BitSet
BitSet类实现了一个按需增长的位向量,实际是由“二进制位”构成的一个Vector。每一位都是一个表示true或者false 的boolean 值。如果我们希望高效地存储这样只有两种类型的数据,就可以使用BitSet。
首先需要说明的是,BitSet并不属于集合框架,没有实现List或Map或者Set接口,BitSet更多的表示一种开关信息,对于海量不重复数据,利用索引表示数据的方式,将会大大节省空间使用。
位图
vector of bits也就是位图,由于可以用非常紧凑的格式来表示给定范围的连续数据而经常出现在各种算法设计中,这里非常紧凑的格式指的就是数组。
基本原理是,在一个特定的位置上(往往是数组下标的位置上)的值(开关),0为没有出现过,1表示出现过,也就是说使用的时候可根据某一个位置是否为0表示此数(这个位置代表的数,往往是下标)是否出现过。
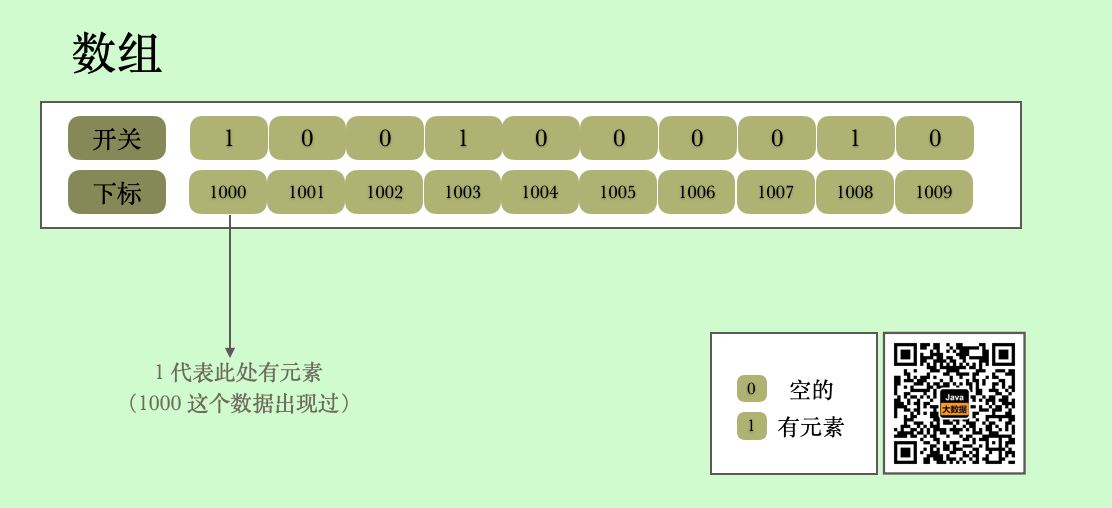
为了方便大家理解,我么可以对上图的数据解释一下,上图是我截取了一个位向量的一部分,也就是下标为1000-1009 的位置。这里开关为1(值为1)代表着此处的数据出现过,也就是说值为数组下标的数据,也就是1000出现过,同理1003 也出现过,然后就是1008 也出现过,其他的都没有出现过。
其实到这里我们就可以对位图有了一个基本的认识,说白了它就是用数组表示特定位置上的数据出现过没有,因为出现还是没有出现只会有两种结果,也就是true 和 false ,所以我们可以使用0 1 来表示,这里的0 1 指的是二进制中的0 1 ,这样我们用bit 来表示,而不是使用其他数据类型,例如Int 类型或者是String ,因为这种数据类型是比较耗空间的,这就是为什么我们使用这种数据结构的原因
位图为什么省空间
前面我们讲到为了位图主要是用来表示开关这样的信息的,我们使用位图主要是为了节省空间,但是我们并没有说是怎样节省空间的。假设我们有一个产品,每天有1亿的日活,用户总量的话大概是10亿,然后我们的用户ID 也是从0-到10亿之间的,现在我们想要计算一下UV和PV。需求就是这样简单的需求,PV 很简单我们主要是如何计算UV,为了计算UV 我们需要先将登录的用户信息存储下来。
SET 实现
我们可以将long 类型的用户ID 加到一个Set 里面去,然后我们计算一下空间消耗,假设1亿的日活的话,我们就有一亿个long 类型的整数,然后我们算一下占用空间大小 100000000*8/1024/1024=763M,也就是我们大概需要763M 的一个存储空间
vector of bits
我们需要的就是一个10亿大小的bit 数组,1000000000/8/1024/1024=119M ,我们使用位向量的话大概只需要119M,其实我们可以看到这之间的的差距还是比较大的
其实从上面我们就看出来了,为什么位图是比较省空间的,所以说位图的本质是选择了合适的数据类型来表示特定的含义,在这里就是有没有,这里我们使用boolean 看一个测试,假设我要表示一个1024 个开关这样的信息,那我们预期的一个内存占用也是1024bit,以为bit 可以表示我们想要表达的含义
@Test
public void test2(){
boolean[] bits = new boolean[1024];
System.out.println(ClassLayout.parseInstance(bits).toPrintable());
}
输出
[Z object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 00 00 f8 (00000101 00000000 00000000 11111000) (-134217723)
12 4 (object header) 00 04 00 00 (00000000 00000100 00000000 00000000) (1024)
16 1024 boolean [Z.<elements> N/A
Instance size: 1040 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
我们看到它的内存占用达到了1040 bytes,除去对象头之外依然高达1024bytes而不是1024bit。
其实这里我们可以总结一个公式,首先我们明确我们使用的数据类型是什么,如果是int 类型那就是4个字节,如果是long 类型那就是8个字节,然后我们就知道使用普通类型内存开销是使用bit的多少倍,例如使用int 类型是32倍,使用long 类型是64 倍,但是往往使用位图是有一定的空间浪费的开销,例如上面的uv 的例子,我们数组大小是10亿,而我们的set 大小是1亿,所以我们使用64/10 就是我们使用非bit 和使用bit 的内存开销的倍数了,大概就是6.4倍

位图的使用场景
前面我们也提到了主要用在判断有没有或者是不是 这样的场景中的,例如计算UV 就是判断这个用户有没有登陆,当然在这个基础上也衍生出了很对应用,主要是用来做过滤和好缓存,例如我们在查询DB 之前,可以先判断用户时候存在,如果不存在就不用走DB了,这种可以防止恶意登陆什么的从而减少对系统的压力,主要就是要学会这种思想,然后加以应用。
面试题中也常出现,比如:统计40亿个数据中没有出现的数据,将40亿个不同数据进行排序等。
又如:现在有1千万个随机数,随机数的范围在1到1亿之间。现在要求写出一种算法,将1到1亿之间没有在随机数中的数求出来(百度)。
programming pearls上也有一个关于使用bitset来查找电话号码的题目。
Bitmap的常见扩展,是用2位或者更多为来表示此数字的更多信息,比如出现了多少次等。
BitSet 初识
上面我们说了bit 的好处,但是java 里面并没有bit 这种类型,所以你不能直接创建一个bit 的数组,就像这样bit[] bits =new bit[1024]; 所以我们一定要就需要想其他的方式来实现这个效果,因为int 是32 个bit,long 是64 个bit,虽然java 没有提供bit 但是java 提供了int 提供了long ,所以我们可以将其看做是bit 的一个集合,但是这样的话我们的对bit 操作也会发生一些变化,也就是我们的操作是针对一个bit 集合而言的,可以称之为bit-wise 操作
Bitset这种结构虽然简单,实现的时候也有一些细节需要主要。其中的关键是一些位操作,比如如何将指定位进行反转、设置、查询指定位的状态(0或者1)等。
一. BitSet 说明书
按照国际惯例,我们还是先看一下BitSet 的说明书
/**
* This class implements a vector of bits that grows as needed. Each
* component of the bit set has a {@code boolean} value. The
* bits of a {@code BitSet} are indexed by nonnegative integers.
* Individual indexed bits can be examined, set, or cleared. One
* {@code BitSet} may be used to modify the contents of another
* {@code BitSet} through logical AND, logical inclusive OR, and
* logical exclusive OR operations.
* 这个类实现了一个按需增长的位向量,位向量的每一位都是一个布尔值,位向量的每一个位都是被非负的int 值索引的
* 每一个被索引的位,都可以被检查、设置或者清除
* 一个BitSet通过逻辑与或者逻辑或等运算可以用来改变另外一个BitSet的内容
* <p>By default, all bits in the set initially have the value {@code false}.
* 默认情况下,BitSet的每一位的默认值都是false
* <p>Every bit set has a current size, which is the number of bits
* of space currently in use by the bit set. Note that the size is
* related to the implementation of a bit set, so it may change with
* implementation. The length of a bit set relates to logical length
* of a bit set and is defined independently of implementation.
* BitSet 都有一个当前大小,即BitSet当前使用的位的数量,需要注意的是这个size 是和BitSet的实现有关的,所以它的变化可能会因为实现的不同发生变化
* BitSet的长度是BitSet的逻辑大小,它的定义和其实现有关
* <p>Unless otherwise noted, passing a null parameter to any of the methods in a {@code BitSet} will result in a {@code NullPointerException}.
* 除非另有说明,否则传一个null 值给BitSet的任何方法都会抛出NullPointerException
* <p>A {@code BitSet} is not safe for multithreaded use without external synchronization.
* 如果没有外部同步措施,BitSet在多线程中使用是不安全的
* @author Arthur van Hoff
* @author Michael McCloskey
* @author Martin Buchholz
* @since JDK1.0
*/
public class BitSet implements Cloneable, java.io.Serializable {
/*
* BitSets are packed into arrays of "words." Currently a word is
* a long, which consists of 64 bits, requiring 6 address bits.
* The choice of word size is determined purely by performance concerns.
*/
private final static int ADDRESS_BITS_PER_WORD = 6;
private final static int BITS_PER_WORD = 1 << ADDRESS_BITS_PER_WORD;
private final static int BIT_INDEX_MASK = BITS_PER_WORD - 1;
/* Used to shift left or right for a partial word mask */
private static final long WORD_MASK = 0xffffffffffffffffL;
/**
* @serialField bits long[]
*
* The bits in this BitSet. The ith bit is stored in bits[i/64] at
* bit position i % 64 (where bit position 0 refers to the least
* significant bit and 63 refers to the most significant bit).
*/
private static final ObjectStreamField[] serialPersistentFields = {
new ObjectStreamField("bits", long[].class),
};
/**
* The internal field corresponding to the serialField "bits".
* BitSet的底层实现是使用long数组作为内部存储结构的,所以BitSet的大小为long类型大小(64位)的整数倍。
*/
private long[] words;
/**
* The number of words in the logical size of this BitSet.
*/
private transient int wordsInUse = 0;
/**
* Whether the size of "words" is user-specified. If so, we assume
* the user knows what he's doing and try harder to preserve it.
*/
private transient boolean sizeIsSticky = false;
/* use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = 7997698588986878753L;
}
二. 构造方法
2.1 无参构造
第一个构造方法创建一个默认的对象,所有位初始化为0。
/**
* Creates a new bit set. All bits are initially {@code false}.
*/
public BitSet() {
// BITS_PER_WORD=64
initWords(BITS_PER_WORD);
sizeIsSticky = false;
}
2.2 有参构造
第二个方法允许用户指定初始大小,所有位初始化为0。
/**
* Creates a bit set whose initial size is large enough to explicitly
* represent bits with indices in the range {@code 0} through
* {@code nbits-1}. All bits are initially {@code false}.
*
* @param nbits the initial size of the bit set
* @throws NegativeArraySizeException if the specified initial size
* is negative
*/
public BitSet(int nbits) {
// nbits can't be negative; size 0 is OK
if (nbits < 0)
throw new NegativeArraySizeException("nbits < 0: " + nbits);
initWords(nbits);
sizeIsSticky = true;
}
上面两个构造方法,实际的空间是由initWords方法控制的,在这个方法里面,我们实例化了一个long型数组
private void initWords(int nbits) {
words = new long[wordIndex(nbits-1) + 1];
}
/**
* Given a bit index, return word index containing it.
*/
private static int wordIndex(int bitIndex) {
return bitIndex >> ADDRESS_BITS_PER_WORD;
}
这里引入了另外一个方法wordIndex,那么wordIndex又是干嘛的呢,这里涉及到一个常量ADDRESS_BITS_PER_WORD,先解释一下,源码中的定义如下:
private final static int ADDRESS_BITS_PER_WORD = 6;
很明显2^6=64(8个byte,对应long型)。所以,当我们传进129作为参数的时候,我们会申请一个long[(129-1)>>6+1]也就是long[3]的数组。BitSet是通过一个整数来表示一定的bit位。
我们知道BitSet虽然内部可以进行扩容,但是如果能提前预估出空间的大小,可以减少数组扩容的次数和元素的拷贝。
2.4 其他构造方法
当然我们也可以基于其他数据集合创建BitSet,例如 long[], byte[], LongBuffer, 和 ByteBuffer
BitSet bitSet = BitSet.valueOf(new long[] {
42, 12 });
三. BitSet 运作原理
3.1 set 方法
为了简化这个问题我们不使用int 或者long 来表示bit 的集合,而是使用byte 来表示bit 的集合,首先我们让所有的位置都初始化成0

现在如果我们想将第三个位置设置为1,我们则将1 左移3位
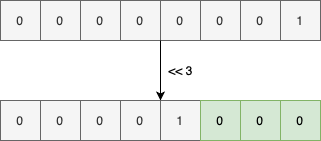
例如下面逻辑或的操作结果如下
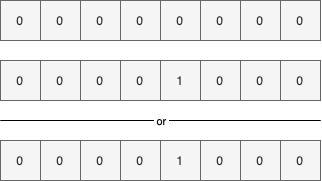
同样我们如果想将下标为7的位置设置为true
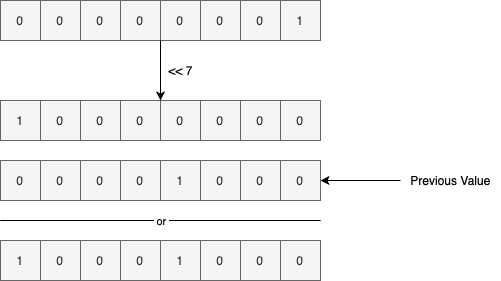
上图我们先将1右移7位,然后和前面的右移3位的结果进行了逻辑或操作
3.2 get方法
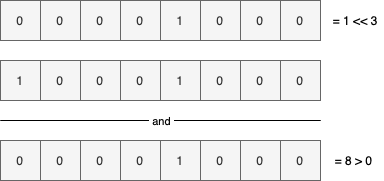
get 方法主要用来检测特定位置上是true 或者false(1 还是0),它的主要实现原理是先有移然后做逻辑与
例如下面:我们项检测3的位置是否是1
- 执行将1右移3位
- 将新值和原来的值做逻辑与
- 如果计算结果为正,则说明该位置的值是1
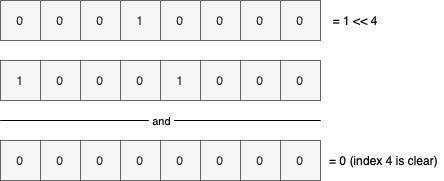
如果我们检测4的位置上的值,我们会发现结果等于0,然后就证明了4这个位置上的值是0
3.2 扩容方法
目前我们的只能存储一个8位的位向量,为了打破这个限制,我们只能使用一个使用一个byte 数组表示来代替单个的byte,就像下面这样

但是一旦我们使用byte 数组进行表示的时候,我们操作(set get clear)特定位置上的值的时候,首先需要定位到数组中特定的byte 上,例如上面我们想要对14的位置进行set 操作,我们找到的就是数组中第二个byte,当然如果你想要对超出15的位置进行设置,那就需要对数组进行扩容,这个过程在BitSet 中是自动发生的。
四. BitSet的实现
上面我们也提到了,为了简化操作我们使用了byte 代替了bit 集合,我们这样的设计也是为了简化BitSet的原理,但是BitSet的事项却是使用的是long 代替了bit 集合,到现在我们关于原理已经掌握了不少了,接下来我们看一下Java 中的实现,以及如何去使用它,首先我们验证一下BitSet到底优美与为我们节省空间
@Test
public void test2(){
boolean[] bits = new boolean[1024];
System.out.println(ClassLayout.parseInstance(bits).toPrintable());
BitSet bitSet = new BitSet(1024);
System.out.println(GraphLayout.parseInstance(bitSet).toPrintable());
}
输出
[Z object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 00 00 f8 (00000101 00000000 00000000 11111000) (-134217723)
12 4 (object header) 00 04 00 00 (00000000 00000100 00000000 00000000) (1024)
16 1024 boolean [Z.<elements> N/A
Instance size: 1040 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
java.util.BitSet@e50a6f6d object externals:
ADDRESS SIZE TYPE PATH VALUE
71821ef90 24 java.util.BitSet (object)
71821efa8 144 [J .words [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
我们看到同样的功能boolean[] 数组使用了1040个bytes,其中除过对象头的占用外内部数组是1204 个字节,然后我们注意到BitSet 的内部数组的大小是16,因为是long 类型的,所以可以表示的就是16*64=1024个bit,尽管总供给使用了168byte但是比起boolean[]的1040byte 还是少了很多的
/**
* Sets the bit at the specified index to {@code true}.
*
* @param bitIndex a bit index
* @throws IndexOutOfBoundsException if the specified index is negative
* @since JDK1.0
*/
public void set(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
// 确定在数组中哪一个位置上,这里的word 就是数组的下标,因为我们
int wordIndex = wordIndex(bitIndex);
// 判断是够需要扩容,如果需要则扩容
expandTo(wordIndex);
words[wordIndex] |= (1L << bitIndex); // Restores invariants
checkInvariants();
}
/**
* Given a bit index, return word index containing it.
*/
private static int wordIndex(int bitIndex) {
return bitIndex >> ADDRESS_BITS_PER_WORD;
}
/**
* Ensures that the BitSet can accommodate a given wordIndex, temporarily violating the invariants. The caller must
* restore the invariants before returning to the user,possibly using recalculateWordsInUse().
* @param wordIndex the index to be accommodated.
*/
private void expandTo(int wordIndex) {
int wordsRequired = wordIndex+1;
if (wordsInUse < wordsRequired) {
ensureCapacity(wordsRequired);
wordsInUse = wordsRequired;
}
}
总结
- 位图有很多使用场景,例如过滤或者数据缓存的场景,使用的好的可以很好的提高我们程序的性能
- 由于Java中没有bit 这种数据类型,所以java 的BitSet使用了long 代替了bit