HDFS 机架感知
客户端向 Namenode 发送写请求时,Namenode 为这些数据分配 Datanode 地址,HDFS 数据块副本的放置对于系统整体的可靠性和性能有关键性影响。一个简单但非优化的副本放置策略是,把副本分别放在不同机架,甚至不同IDC,这样可以防止整个机架,甚至整个IDC崩溃带来的数据丢失,但是这样文件写必须在多个机架之间、甚至IDC之间传输,增加了副本写的代价,是否有较优的方案来解决这个问题呢?
机架感知是什么
告诉 Hadoop 集群中哪台机器属于哪个机架。
那通过什么方式告知呢?答案是人工配置。因为Hadoop 对机架的感知并非是自适应的,亦即,hadoop 集群分辨某台 slave 机器是属于哪个 rack 并非是智能感知的,而是需要 hadoop 的管理者人为的告知 hadoop 哪台机器属于哪个 rack,这样在 hadoop 的 namenode 启动初始化时,会将这些机器与 rack 的对应信息保存在内存中,用来作为对接下来所有的 HDFS 的写块操作分配 datanode 列表时(比如 3 个 block 对应三台 datanode)的选择 datanode 策略,尽量将三个副本分布到不同的 rack。
机架感知使用场景
在 Hadoop 集群规模很大的情况下,就需要用到机架感知。
机架感知需要考虑的情况
- 不同节点之间的通信能够尽量发生在同一个机架之内,而不是跨机架。
- 为了提高容错能力,名称节点会尽可能把数据块的副本放到多个机架上。
机架感知配置步骤
默认情况下,hadoop 的机架感知是没有被启用的。所以,在通常情况下,hadoop 集群的 HDFS 在选机器的时候,是随机选择的,也就是说,很有可能在写数据时,hadoop 将第一块数据 block1 写到了 rack1 上,然后随机的选择下将 block2 写入到了 rack2 下,此时两个 rack 之间产生了数据传输的流量,再接下来,在随机的情况下,又将 block3 重新又写回了 rack1,此时,两个 rack 之间又产生了一次数据流量。在 job 处理的数据量非常的大,或者往 hadoop 推送的数据量非常大的时候,这种情况会造成 rack 之间的网络流量成倍的上升,成为性能的瓶颈,进而影响作业的性能以至于整个集群的服务。
要将 hadoop 机架感知的功能启用,配置非常简单,在 namenode 所在机器的 hadoop-site.xml 配置文件中配置一个选项:
<property><name>topology.script.file.name</name><value>/path/to/RackAware.py</value></property>
这个配置选项的 value 指定为一个可执行程序,通常为一个脚本,该脚本接受一个参数,输出一个值。接受的参数通常为某台 datanode 机器的 ip 地址,而输出的值通常为该 ip 地址对应的 datanode 所在的 rack,例如”/rack1”。Namenode 启动时,会判断该配置选项是否为空,如果非空,则表示已经用机架感知的配置,此时 namenode 会根据配置寻找该脚本,并在接收到每一个 datanode 的心跳时,将该 datanode 的 ip 地址作为参数传给该脚本运行,并将得到的输出作为该 datanode 所属的机架,保存到内存的一个 map 中。
至于脚本的编写就需要将真实的网络拓朴和机架信息了解清楚后,通过该脚本能够将机器的 ip 地址正确的映射到相应的机架上去。可以参考Hadoop官方给出的**脚本**。
官方给的是利用 shell 写的,下面是用 Python 代码来实现的:
#!/usr/bin/python #-*-coding:UTF-8 -*-import sysrack = { "hadoopnode-176.tj":"rack1", "hadoopnode-178.tj":"rack1", "hadoopnode-179.tj":"rack1", "hadoopnode-180.tj":"rack1", "hadoopnode-186.tj":"rack2", "hadoopnode-187.tj":"rack2", "hadoopnode-188.tj":"rack2", "hadoopnode-190.tj":"rack2", "192.168.1.15":"rack1", "192.168.1.17":"rack1", "192.168.1.18":"rack1", "192.168.1.19":"rack1", "192.168.1.25":"rack2", "192.168.1.26":"rack2", "192.168.1.27":"rack2", "192.168.1.29":"rack2",}if __name__=="__main__": print "/" + rack.get(sys.argv[1],"rack0")
由于没有确切的文档说明到底是主机名还是 ip 地址会被传入到脚本,所以在脚本中最好兼容主机名和 ip 地址,如果机房架构比较复杂的话,脚本可以返回如:/dc1/rack1 类似的字符串。
执行命令:
chmod +x RackAware.py
重启 namenode,如果配置成功,namenode 启动日志中会输出:
INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/192.168.1.15:50010
网络拓扑机器之间的距离
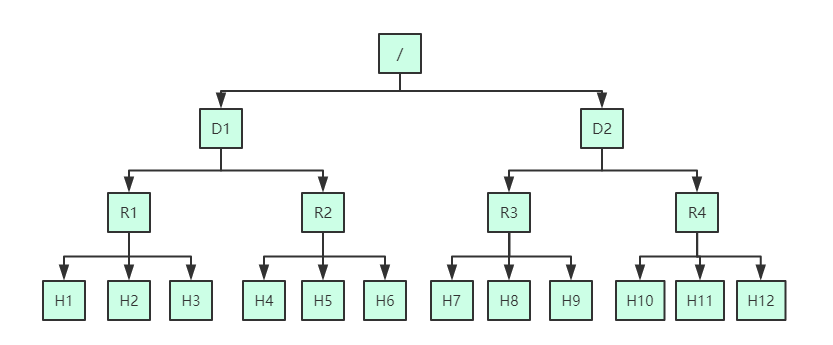
这里基于一个网络拓扑案例,介绍在复杂的网络拓扑中 hadoop 集群每台机器之间的距离。有了机架感知,NameNode 就可以画出上图所示的 datanode 网络拓扑图了。
D1,R1 都是交换机,最底层是 datanode。则 H1 的 rackid=/D1/R1/H1,H1 的 parent 是 R1,R1 的是 D1。这些 rackid信息可以通过 topology.script.file.name 配置。有了这些 rackid 信息就可以计算出任意两台 datanode 之间的距离。
- distance(/D1/R1/H1,/D1/R1/H1)=0 相同的 datanode
- distance(/D1/R1/H1,/D1/R1/H2)=2 同一 rack 下的不同 datanode
- distance(/D1/R1/H1,/D1/R1/H4)=4 同一 IDC(互联网数据中心、机房)下的不同 datanode
- distance(/D1/R1/H1,/D2/R3/H7)=6 不同 IDC 下的 datanode