HDFS
HDFS是Hadoop整体架构的底层存储系统,从数据结构上来说,它适合存储半结构化、非结构化、多维的数据,如果实时性要求不高,那么它也可存储关系性很强数据的数据。从数据量来说,它的分布式体系和容错机制可容纳PB级别的数据。从统计角度来说,HDFS可通过MapReduce对数据进行无限次数有规律的统计分析,最后达到数据挖掘和预测的目的,而传统数据库没有这样的能力,或者达到同样目的需付出更大的资源代价。最关键的是HDFS的集群容错机制使得承载它的服务器可以是非常廉价的机器。
HDFS虽然支持大数据的处理,但它有一个难以消除的缺点,就是访问延迟高,及时性差,当然,如果只是单纯的存取数据,比如列式数据库Hbase,延迟的问题也不大。
概念
-
Hadoop 1.X
-
HDFS架构
- 架构
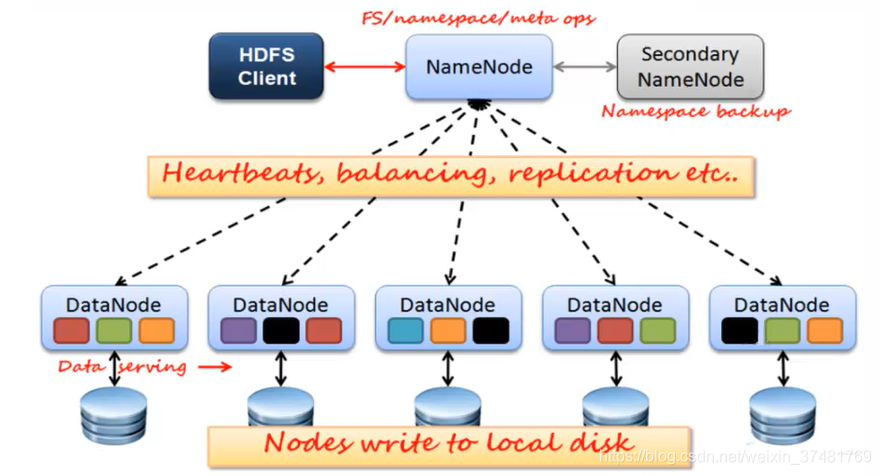
- 1.X的HDFS主要由NameNode、DataNode、SecondaryNameNode组成,其架构和分片后的ES、Mongo、Redis等数据库原理相同
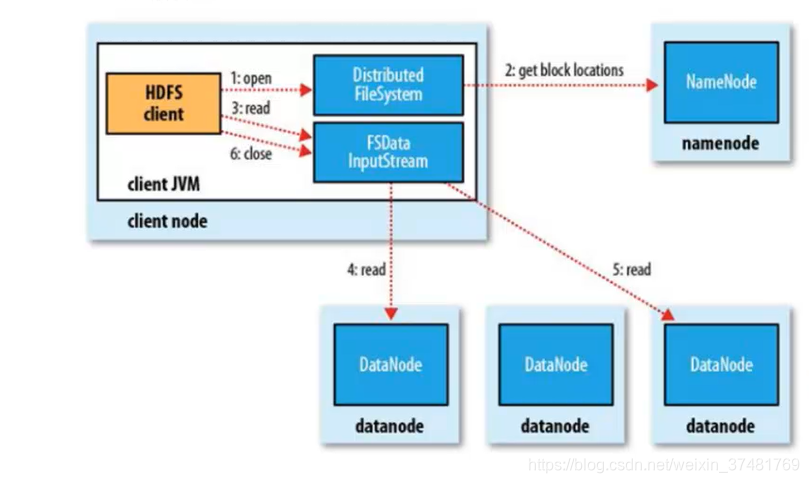
- 读流程
-
读取数据时,由客户端先去读NameNode,根据NameNode返回的元数据再去DataNode中找相应的block
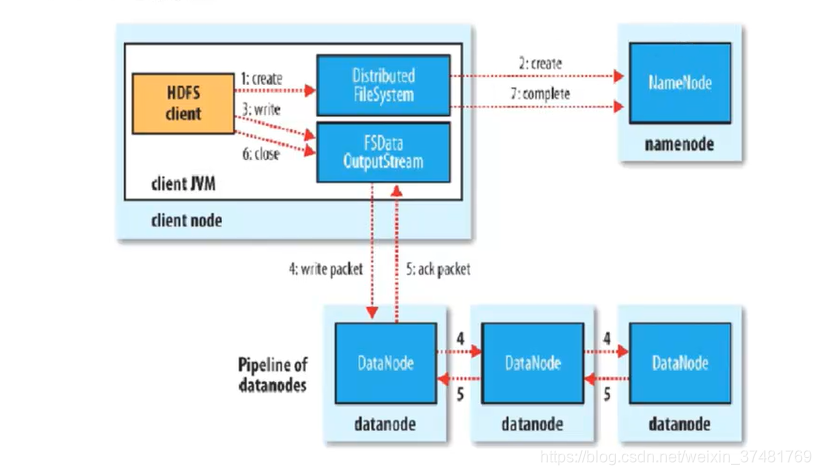
- 写流程
-
操作数据时,由客户端先去读取并更新NameNode,并根据NameNode返回的元数据再去操作DataNode中的数据。这里有一点需要注意,1.X的HDFS不能对库中的文件更新,只能先删除再添加,所以要尽可能减少更新操作
-
NameNode
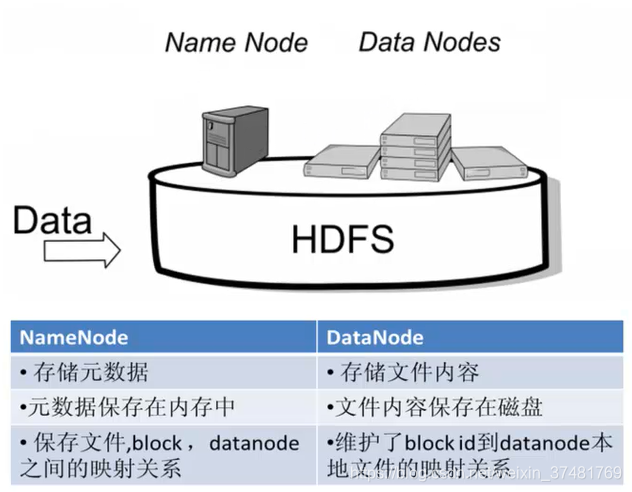
NameNode的主要功能接收客户端的读写服务,它保存着DataNode的元数据,元数据包含了文件的owership和permissions、文件包含哪些块、Block保存在哪个DataNode
NameNode的metadata信息在启动后会加载到内存,那么客户端访问时的速度会更快
-
DataNode
DataNode用来存储数据,每次启动DataNode线程时,会向NameNode汇报block信息,通过向NameNode发送心跳保持与其联系(默认3秒一次),如果NameNode 没有接收(默认10分钟)到DataNode的心跳,则认为其lost,并copy其上的block到其它DataNode
一张图说明NN和DN的区别
-
Block
在DataNode中,文件被切分为固定大小的数据块,默认大小为64M,可配置,若文件不到64M,也单独存成一个block。一个文件会按大小被切分成若干个block,存储到不同节点上,默认为3个。
Block大小和副本数在通过Client端上传时可设置,文件上传成功后副本数可变更,但Block Size不可变更

-
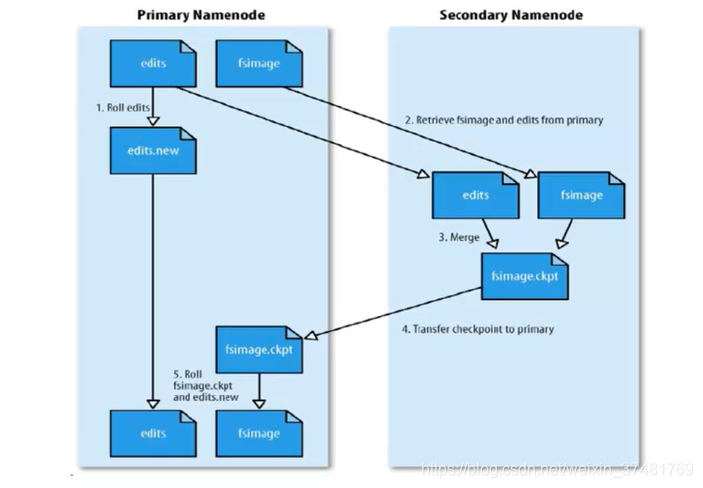
SecondaryNameNode
SecondaryNameNode的主要工作是帮助NameNode合并edits log,减少NN的启动时间。
- SecondaryNameNode执行的合并时机
-
a.根据配置文件设置的时间间隔fs.checkpoint.period默认3600秒
-
b.根据配置文件设置edits log大小fs.checkpoint.size规定edits文件的最大默认值是64MB
-
c.SecondaryNameNode的合并流程
-
Hadoop主要传输协议
Hadoop的主要传输协议是RPC,从配置上来看很容易能发现在启动时绑了很多个端口号。
-
-
Hadoop 2.X
-
产生背景
Hadoop1中HDFS和MapReduce在高可用、扩展性等方面存在问题,HDFS的NameNode单点故障,难以应用于在线场景,且单点的NameNode压力过大、内存受限,影响系统扩展性
Hadoop1中MapReduce JobTracker访问压力过大影响系统扩展性、无法支持出MapReduce以外的如Storm、Spark等计算框架

-
Hadoop2 解决的问题
Hadoop2.X由HDFS、YARN和MapReduce三个分支构成
-
解决了HDFS1.X中存在的单点故障和内存受限问题
-
解决了单点故障问题HDFS HA通过主备NameNode解决
-
解决了内存受限问题,可水平扩展NameNode,每个NameNode分管一部分目录,所有NameNode共享所有DataNode存储资源
-
-
YARN
YARN(Yet Another Resource Negotiator)是Hadoop的资源管理系统将MRV1中JobTracker的资源管理和任务调度狂歌功能分开,分别由ResourceManager和ApplicationMaster进程实现
ResourceManager:负责整个集群的资源管理和调度
ApplicationMaster:负责应用程序相关的事物,比如任务调度、任务监控和容错等。每个应用程序对应一个ApplicationMaster,所以多个计算框架可运行在YARN上,如Hadoop1不支持的Spark、Storm等
-
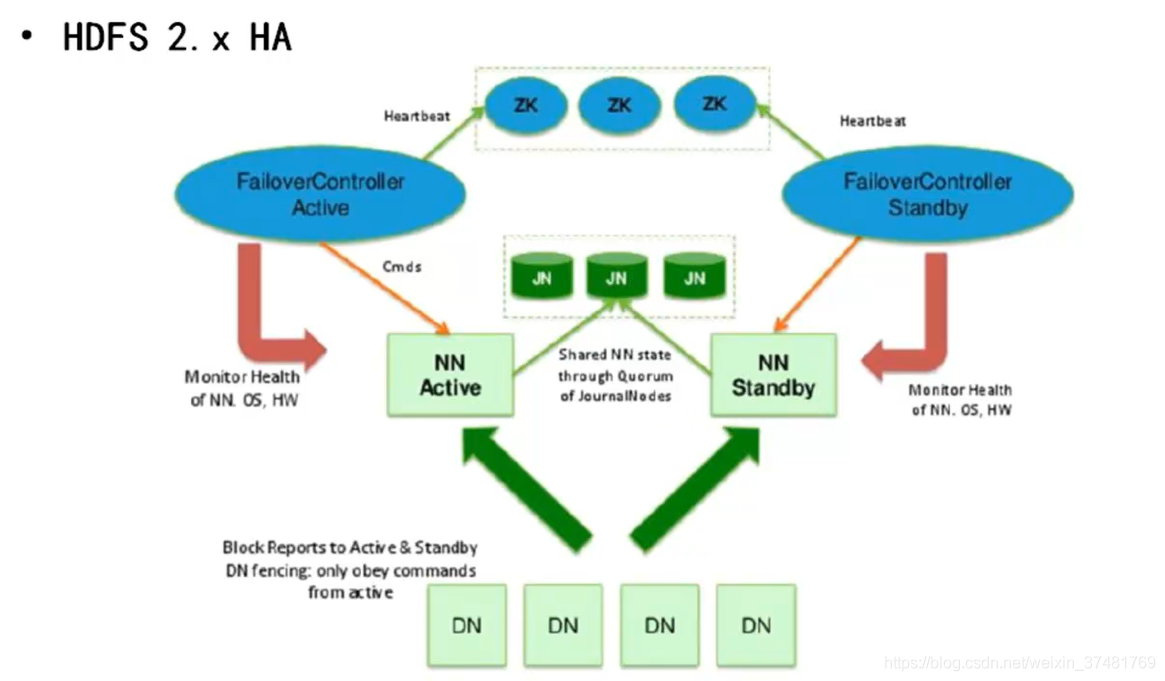
HDFS HA
- 解决单点故障问题
- 主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换
- 所有DataNode同时向两个NameNode汇报数据块信息
- 两种切换选择
- 手动切换:通过命令实现主备之间的切换,可以用HDFS升级等场合
- 自动切换:基于Zookeeper实现
- 基于Zookeeper自动切换方案
- Zookeeper Failover Controller主要用于监控NameNode健康状态,向Zookeeper注册NameNode,并启动心跳检测,NameNode挂调后ZKFC为NameNode竞争锁,获得ZKFC锁的NameNode变为active状态
-
配置
配置笔者就不在此赘述,有需要可以去读官网 http://hadoop.apache.org/docs/
常用shell
[yanfa]$ ./hadoop fs -rmr /usr/
[yanfa]$ ./hadoop fs -rm /usr/file
[yanfa]$ ./hadoop fs -mv /usr/file /usr/file2
[yanfa]$ ./hadoop fs -mkdir /usr/
[yanfa]$ ./hadoop fs -ls /usr/
[yanfa]$ ./hadoop fs -cp /usr/file /usr2/file
[yanfa]$ ./hdfs haadmin -transitionToActive --forcemanual nn1 强制namenode变为active状态
[yanfa]$ ./hdfs haadmin -transitionToStandby --forcemanual nn1 强制namenode变为standby状态
Java API的使用
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>hadoops</groupId>
<artifactId>hadoops</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.2</version>
<exclusions>
<exclusion>
<artifactId>jdk.tools</artifactId>
<groupId>jdk.tools</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.5.2</version>
</dependency>
</dependencies>
</project>
Java API
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HDFSDemo {
private static FileSystem fs = null;
static{
try {
fs = FileSystem.get(new URI("hdfs://host:port"), new Configuration(), "root");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
}
/**
* 删除文件|文件夹
*/
public static void rmr(String path) throws IllegalArgumentException, IOException {
boolean flag = fs.delete(new Path(path), true);
System.out.println(flag);
}
/**
* 创建文件|文件夹
*/
public static void mkdir(String path) throws IllegalArgumentException, IOException {
boolean flag = fs.mkdirs(new Path(path));
System.out.println(flag);
}
/**
* 上传
*/
public static void putFiles(String inputFile, String outputFile) throws IllegalArgumentException, IOException {
FileInputStream in = new FileInputStream(new File(inputFile));
FSDataOutputStream out = fs.create(new Path(outputFile));
IOUtils.copyBytes(in, out, 2048, true);
}
/**
* 下载
*/
public static void getFiles(String inputFile, String outputFile) throws IllegalArgumentException, IOException {
InputStream in = fs.open(new Path(inputFile));
FileOutputStream out = new FileOutputStream(new File(outputFile));
IOUtils.copyBytes(in, out, 2048, true);
}
/**
* 复制文件
*/
public static void cpFiles(String inputFile, String outputFile) throws IllegalArgumentException, IOException {
InputStream in = fs.open(new Path(inputFile));
FSDataOutputStream out = fs.create(new Path(outputFile));
IOUtils.copyBytes(in, out, 2048, true);
}
public static void main(String[] newArgs){
try {
// mkdir("/mapreduceFloders/beforejob/normalindex");
putFiles("C:\\Users\\tend\\Desktop\\tel_file", "/mapreduceFloders/beforejob/datacount/tel_file");
// getFiles( "/auto-hdfs/test.txt","C:\\Users\\tend\\Desktop\\testss.txt");
// rmr("/mapreduceFloders/afterjob");
// rmr("/mapreduceFloders/beforejob/tel_file");
} catch (Exception e) {
e.printStackTrace();
}
}
}