HDFS 架构
Hadoop HDFS是一个主从(Master / Slave)架构,其中Master是Namenode节点,它主要用来存储元数据,Slave是Datanode节点,用来存储实际业务数据的节点。HDFS架构用一个Namenode和多个Datanode组成。
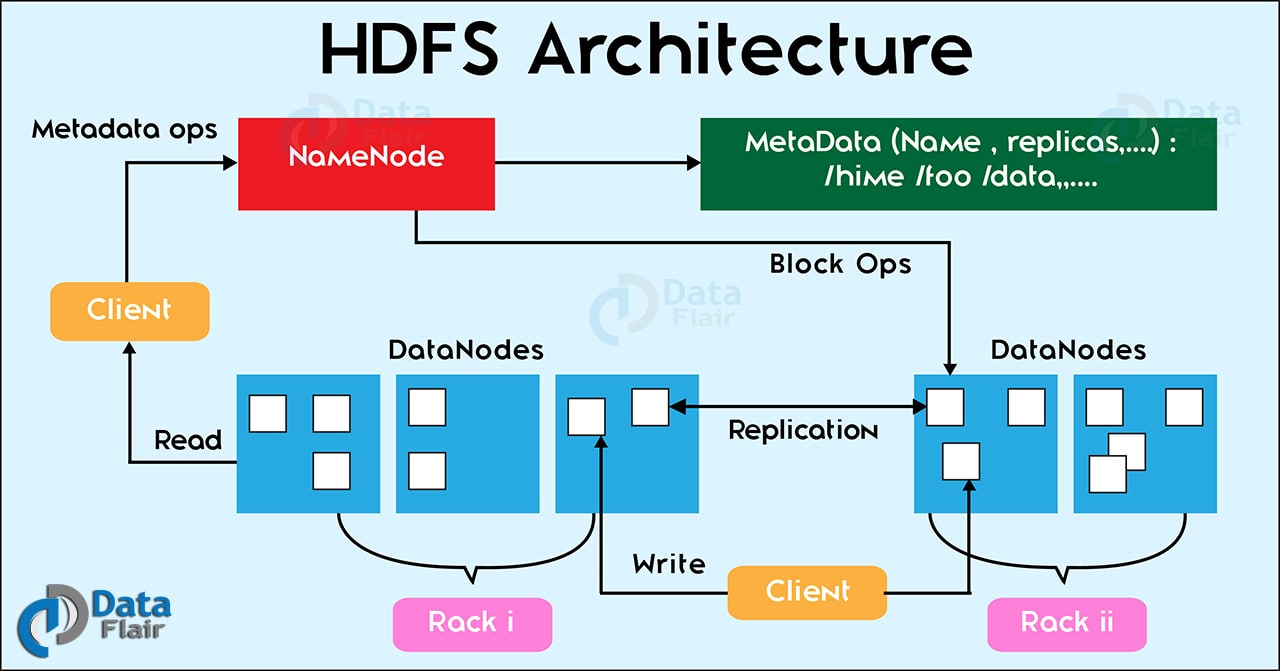
下面详细介绍HDFS里面的各个部分。
HDFS NameNode
Namenode其实就是Master节点,它主要用来存储元数据,比如数据块的数量,副本和其他细节。这些元数据是存储在Master节点的内存里面的,因为要保证元数据的快速查询。另外还会在磁盘(FsImage文件和Editlog文件)保存一份元数据镜像文件。Namenode维护和管理Slave节点,并且给他们分配任务。由于NameNode是整个HDFS集群的中心,所以最好把它部署在可靠的硬件机器上。
Namenode主要负责以下任务:
- 管理文件系统命名空间
- 规范客户端文件访问权限
- 执行文件系统相关的操作,如关闭,打开文件/目录,以及给文件/目录命名。
- 所有的datanode都会给Namenode发送心跳和块信息报告。心跳用来检测 Datanode是否处理正常状态。块信息报告是datanode上所有块信息的列表。
- Namenode还负责处理所有块的副本因子。
Namenode主要维护两个文件,一个是FSImage,一个是EditLog。
FsImage
FsImage是一个“镜像文件”。它保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。对于文件来说包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。
EditLog
EditLog主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。
HDFS DataNode
DataNode即Slave节点,它是实际存储业务数据的节点。它会按照客户端的请求执行数据读写操作。DataNode可以部署在商用硬件上。
Datanode主要负责以下工作:
- 根据Namenode指令创建、删除和复制数据块。
- Datanode管理系统的数据存储。
- Datanode定期给Namenode发送心跳告知自身的健康状态,默认3秒发送一次心跳。
SecondaryNameNode
SecondaryNameNode是一个辅助的NameNode,不能代替NameNode。它的主要作用是用于合并FsImage和editlog文件。在没有SecondaryNameNode守护进程的情况下,从namenode启动开始至namenode关闭期间所有的HDFS更改操作都将记录到editlog文件,这样会造成巨大的editlog文件,所带来的直接危害就是下次启动namenode过程会非常漫长。
在启动SecondaryNameNode守护进程后,每当满足一定的触发条件(每3600s、文件数量增加100w等),SecondaryNameNode都会拷贝namenode的fsimage和editlog文件到自己的目录下,首先将fsimage加载到内存中,然后加载editlog文件到内存中合并fsimage和editlog文件为一个新的fsimage文件,然后将新的fsimage文件拷贝回namenode目录下。并且声明新的editlog文件用于记录DFS的更改。
Checkpint Node和Backup Node
Checkpoint Node会通过单独线程,定时从Active NameNode拉取edit log文件拷贝到本地,并且将这些edit log在自己内存中进行重演。如果checkpoint条件具备,将进行checkpoint操作,文件存入本地,并通过HTTP PUT的方式将fsimage文件传输给Active NameNode。
Backup Node除了具有Checkpoint Node的上述所有功能外,还会通过RPC方式(属于stream的方式,区别于单独定时拷贝)实时接收Active NameNode的edit操作。因此,同Checkpoint Node相比,Backup Node的内存映象在时间差上几乎与Active NameNode一致。
注意:Checkpoint Node和Backup Node在某种程度上几乎替代了Standby NameNode的功能,因此,在HA模式下,无法启动Checkpoint Node和Backup Node。必须使用非HA模式才可以启动并使用Checkpoint Node。
HDFS 块概念
HDFS会把大文件分割成小的的数据块,它是Hadoop分布式文件系统最小的数据存储单位。数据块的存储位置由Namenode决定。默认的HDFS数据块大小是128MB,我们可以根据需要调整块大小。文件分割后所有的块大小都是一样的,除了最后一个块,默认情况下,它的大小可能小于等于128MB。如果文件的数据量比块小,那么块的容量将等于文件数据量大小。比如文件是129MB,那么HDFS会创建2个块,一个是128MB,一个将是1MB,而不是128MB。
副本管理
块副本给HDFS提供了很好的数据容错特性。如果一个副本损坏了,我们可以从其他节点读取到该副本。HDFS里面块的副本数量叫做副本因子,默认情况下,副本因子是3,可以在配置文件hdfs-site.xml修改这个值。所以每个块会被复制3次,并存储在不用的datanode磁盘上。如果需要把128M的文件存储在HDFS上,那么需要384MB的存储空间(128MB * 3)。
Namenode定期接收来自Datanode的块信息报告来维护副本因子。如果块副本数量比副本因子大,Namenode会删除多余的块副本,相反,Namenode将会新增块副本。
HDFS机架感知
在大型Hadoop集群,为了在读写文件的时候改善网络传输,Namenode会选择给同一个机架或者最近的机架上的Datanode发送读写请求。NameNode通过维护每个DataNode的机架id来获取机架信息。HDFS机架感知就是基于机架信息选择Datanode的过程。
在HDFS架构里面,Namenode需要确保所有的块副本不能存储在同一个机架上。它根据机架感知算法减少延迟时间和容错。我们知道默认副本因子是3,根据机架感知算法,第一个块副本将存储在本地机架,第二个副本存储在同一个机架的不同节点,第三个将存储在另一个机架上。
机架感知对以下几点的改善非常重要:
- 提升数据的高可用和可靠性。
- 改善集群性能。
- 改善网络带宽。
HDFS读写操作
写操作
当客户端想把文件写入到HDFS的时候,为了获取元数据,它必须先给namenode发送请求。Namenode会返回元数据信息(如块数量、块位置等数据块元数据),基于Namenode提供的信息,客户端把文件分割成若干个数据块。之后开始把数据块发送给第一个Datanode。
客户端先把block A发送给Datanode1,Datanode1接收到block A之后,它会把block A复制到同个机架的Datanode2,由于两个Datanode位于同一个机架,数据块需要通过机架交换机传输。然后Datanode2再把数据块复制到另外一个机架的Datanode3上。当Datanode接收来自客户端的数据块的时候,它会给Namenode发送写入确认。这个过程将在文件的其他数据块重复进行。
读操作
从HDFS读取文件,也需要先从namenode获取元数据,即数据块位置、数据块数量,副本和其他细节信息。拿到元数据之后再去相应的datanode读取数据。当客户端或者应用程序接收到文件的所有块之后,它会把这些合并成原始文件的形式。