HDFS 简介
本节我们开始介绍Hadoop生态里面的其中一个组件——HDFS,包括HDFS架构,数据是怎么在HDFS存储的,HDFS的特性,比如分布式存储、容错性,高可用,可靠性以及块概念等。另外还会涉及到HDFS的操作,比如如何从HDFS读写数据,还有HDFS的机架感知算法介绍。
HDFS(Hadoop Distribute File System)是大数据领域一种非常可靠的存储系统,它以分布式方式存储超大数据量文件,但它并不适合存储大量的小数据量文件。Hadoop HDFS是Hadoop和其他组件的数据存储层。HDFS是运行在由价格廉价的商用机器组成的集群上的,而价格低廉的机器发生故障的几率比较高,但是HDFS利用数据副本技术把数据存放在若干个机器上,保证数据的高可用性,使得数据不至于因为某几个机器发生故障发生丢失不可用的情况。HDFS以数据并发访问的方式达到高吞吐量的目的。下面开始详细介绍HDFS的各个关键点。
HDFS 节点
Hadoop是以主从结构的方式运行的,HDFS也是以同样的方式工作的,它也有有两种节点类型,分别是namenode节点和datanode节点。
HDFS Master 节点(Namenode)
Namenode会规范客户端对文件的访问,它维护和管理Slave节点,并把读写任务分配给Slave节点。Namenode执行文件系统的名字空间操作,比如打开,关闭,重命名文件和目录,应该把Namenode部署在高可靠的硬件上面。
HDFS Slave 节点(Datanode)
在HDFS集群,Datanode节点的数量可以扩展到1000。Datanode负责数据存储,它是真正干活的节点,比如响应客户端的数据读写请求,根据Namenode的指令创建和删除block。而且还会根据副本因子把block复制到其他节点。Datanode可以部署在价格低廉的商用机器上,没必要部署在昂贵的高可用机器上。
Hadoop HDFS 进程
HDFS有2个守护进程。如下:
Namenode:该进程运行在master节点上。Namenode节点存储元数据,比如文件名,块数量,块副本数量,块的存储位置,以及块ID等。为了元数据的快速查询,这些都是存储在master节点的内存里面的,并在本地磁盘存储这些元数据的副本。
Datanode:该进程运行在Slave节点,这些节点是真正对数据进行处理和存储的节点。
HDFS 的数据存储
把文件写入到HDFS的时候,HDFS会把文件分割成很多分片,也就是块(block)。默认情况下,HDFS块大小为128MB,块大小可以按需要修改。文件分割成块之后,HDFS会把他们以分布式方式存储在集群的不多节点上。这为MapReduce在集群并行化处理数据提供了很好的基础。

datanode根据副本因子把每个块的副本存放在集群的不用节点磁盘上,默认情况下副本因子为3,副本技术实现了数据的容错性、可靠性以及高可用特性。
HDFS 机架感知
Hadoop运行在由价格低廉的商用机器集群上,这些机器可能在不用的机架。为了数据容错,NameNode把块的副本放在多个机架上,NameNode尽量会在每个机架都存储至少一个块副本,这样如果其中一个机架发生故障,系统还是可用的。优化的副本位置使得HDFS和其他分布式文件系统拉开了差距。机架感知策略的目的是提升数据可用性、可靠性和网络带宽利用率。
HDFS 架构
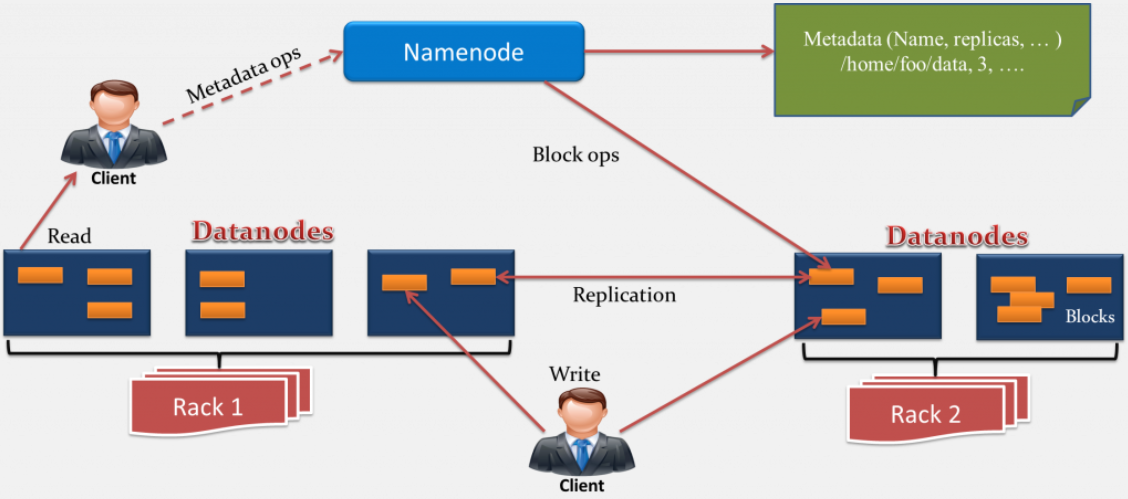
上面这个图清楚描述了HDFS的架构。一个用于存储元数据的Namenode和多个用于存储数据的Datanode。节点是在机架上的,而数据块的副本存储在不同机架上以达到容错的目的。在下面的会介绍HDFS是如何读写文件的,在读写文件的时候,客户端需要和Namenode交互。HDFS适合一次写入多次读取的场景,文件一旦被创建并写入数据后,就不能被编辑了。
Namenode负责存储元数据而Datanode负责存储实际的数据。执行任何任务,客户端都得和Namenode进行交互,因为Namenode是整个集群的中心。
Datanode是把数据存储在本地磁盘的,它会定期给Namenode发送心跳信息,以此来表明自己处在工作状态。另外,Datanode还会根据副本因子负责把block拷贝到其他Datanode。
Hadoop HDFS 特性
HDFS具有以下特点:
- 分布式存储
- 块
- 副本
- 高可用
- 数据可靠性
- 容错性
- 可扩展
- 高吞吐量
分布式存储
HDFS会把大数据文件分割成小block,并把这些block以分布式方式存储在集群。这样MapReduce才能并行的对这些数据进行计算处理。
块
在文件系统里面,块是文件的最小存储单位,我们不能对块做任何控制,比如修改块位置,因为这些由Namenode决定的。块的默认大小是128MB,可以根据实际需求修改该值,这个块大小默认值比操作系统的块要大得多,操作系统的块大小为4KB。
如果数据的大小比HDFS块大小还要小的话,那么块大小将等于数据的大小。比如,文件大小是129MB,那么HDFS将创建2个block,一个block的大小是默认值,即128MB,另外一个block就只有1MB,而不是128MB。
HDFS以块来存储数据的主要优势就是节省了磁盘寻道时间,另一个优势就是在mapper进程处理数据的时候,一次可以处理一个块的数据,这样一个mapper进程在同一时间可以处理大量的数据。
HDFS把文件分割成块,每个块会被存储在不同节点。默认情况下,每个块有3个副本,每个块的副本也是存储在不用节点的,这样可以达到数据容错的目的。这些块的存储位置是由Namenode决定的。
副本
HDFS会给每个块创建副本,块的副本是存储在集群的不用节点的。HDFS会在每个机架尽量存储至少一个副本。
机架是什么呢?即存放服务器的架子。Datanode是放在机架上的,机架上所有节点通过交换机连接,所以如果交换机发生故障了,那么整个机架就变成不可用的了。但数据可以从其他机架读取到。
我们知道HDFS的默认副本因子是3,但是可以根据实际需要在hdfs-site.xml配置文件修改这个值。
高可用
为了达到数据高可用目的,数据块的副本是存储在集群的不同节点的。默认副本因子是3,也就是说数据会在3个不同节点存储,3个节点全挂的概率比较小,所以其中某个节点或者网络挂了都不影响数据可用性。
数据可靠性
HDFS会把根据副本因子把数据存储在不同节点,这对数据的可靠性非常有帮助的。由于HDFS的块复制技术,即使存储块的某些节点挂了,可以从其他节点获取的块数据。如果一个节点挂了,存储在该节点的块就被复制,节点挂了之后又恢复了,存储在该节点的块会被过度复制,我们需要根据情况增加或者删除块副本。这种情况下,只需要运行很少的命令,副本因子就能达到预期的值。这就是数据如何被可靠存储和提供容错以及高可用的原因。
容错
HDFS给Hadoop和其他组件提供具有容错特性的存储层。HDFS是运行在商用硬件上的,而商用硬件奔溃率较高。因此,为了使整个系统具备较高容错性,HDFS把数据复制并存储到集群的不同机器上,默认情况下,数据会存储在3个不同的位置。这样,即使其中的某2个机器宕机了,数据仍然是可用的,进而达到不丢失数据的目的,即数据容错性。
可扩展性
可扩展性即集群可以根据需要扩充和缩小。Hadoop HDFS可以用下面2种方式来达到扩展性目的。
- 给集群的节点增加更多的磁盘。
我们需要编辑配置文件,并为新添加的磁盘创建相应的条目。这种方式需要停机处理,即使停机时间很少。所以人们通常更倾向于使用第二种扩展方式,即水平扩展。 - 给集群增加更多的节点。
这种方式不需要停机,把机器加进来,做一下配置和数据平衡即可,这种方式被称为集群的水平扩展。
高吞吐量
HDFS提供高吞吐量访问数据。吞吐量是单位时间内完成的工作量,它描述了从系统访问数据的速度,通常用它来衡量一个系统的性能。当我们执行一个任务或者一个操作的时候,这个任务会被分割成小任务并被分发到不同系统,系统将会并行且独立的执行这些分配给他们的任务。这样,一个大任务将会在非常短的时间内被执行完成。HDFS就是利用这种方式来提供高吞吐量能力的。通过并行读取数据,我们大大减少了实际读取数据的时间。
HDFS 读写操作
在Hadoop,我们需要通过程序或者命令行(CLI)和文件系统交互。
Hadoop分布式文件系统和Linux文件系统有很多相似之处。比如创建目录,拷贝文件,修改权限等。HDFS也提供不同的文件访问权限,如对用户、用户组或者其他用户的可读、可写、可执行权限。
我们可以通过浏览器查看HDFS文件目录,只需在浏览器输入下面的网址即可,你可以从该网址获取集群信息,例如已用容量、可用容量、可用节点数量,不可用节点数量等。
http://master-IP:50070
HDFS 读操作
客户端从HDFS读取文件时,必须要先和Namenode交互,因为Namenode是唯一存储数据节点元数据的地方。数据存储在哪个Slave节点由Namenode来决定。客户端将和Namenode指定的数据节点交互,并从该节点读取数据。为了安全和身份认证,namenode会给客户端提供token,在客户端从datanode读取数据之前,客户端会把它提供给datanode做身份认证,认证成功之后,才开始读取文件。
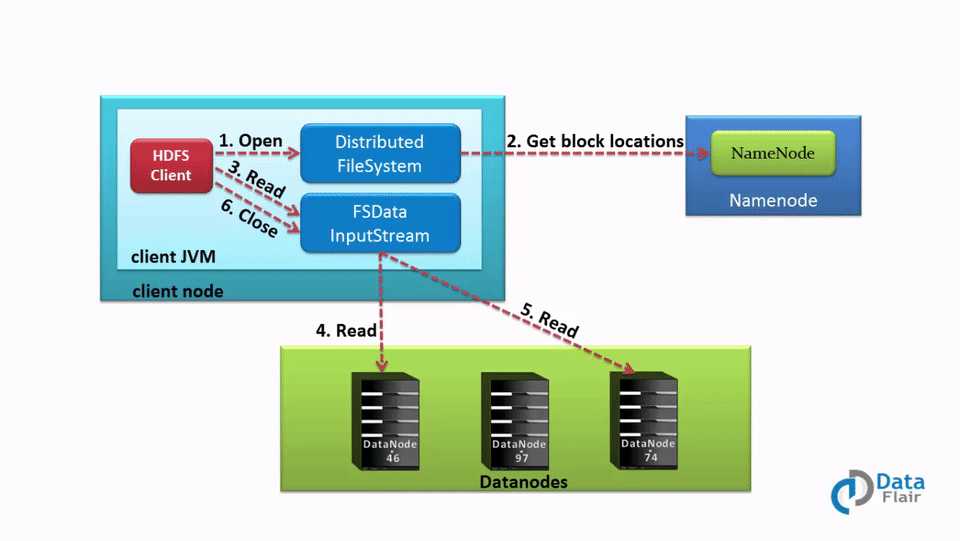
客户端如果想从HDFS读取数据,那么它首先必须和namenode交互,所以客户端通过分布式文件系统API给namenode发起请求,namenode会判断客户端是否有数据访问权限,如果有权限,namenode才会把数据块位置信息发送给客户端。
除了块位置信息,namenode还会给client提供一个安全token,在客户端读取数据之前,需要用它来做身份认证。
当客户端到datanode读取数据的时候,datanode会检查客户端提供的token,如果token没问题,datanode才允许客户端读取特定的数据。这时,客户端将会通过FSDataInputStream开始从datanode读取数据。客户端就是以这种方式直接从datanode读取数据的。
如果在读取数据期间datanode突然挂了,那么客户端会重新给namenode发送请求,namenode将会给它提供其他可用数据块的位置信息。
HDFS 写操作
我们知道,客户端在读文件的时候,需要先和Namenode交互,类似的,在写文件的时候,客户端也需要先和Namenode交互。因为,Namenode会提供slave节点的地址信息。
客户端一旦完成数据块的写入操作,slave节点就开始把它复制到另一个节点,这个节点会把块复制到第三个节点。因为默认的副本因子是3。副本创建完之后,slave节点会给客户端发送一个最终的确认信息。而身份认证和读操作是一样的。
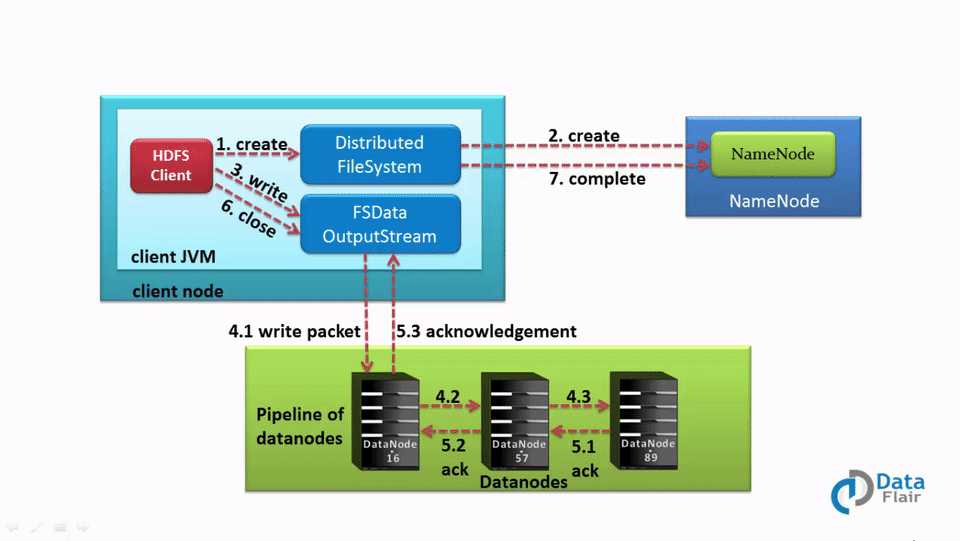
客户端想要把数据写入HDFS,它必须先和namenode交互。客户端通过DistributedFileSystem API给namenode发送请求。namenode接收到请求后,会把可以用于写入数据的datanode的位置信息返回给客户端,接着客户端会跟这些datanode交互,并开始通过FSDataOutputStream写入数据。数据写入和复制完成之后,datanode会给客户端发送一个确认信息通知它数据已经完成写入。
客户端一旦完成第一个块的写入,那么第一个datanode将会把写入的块复制到其他节点,该节点接收到块之后,开始把它复制到第三个节点。第三个节点会把数据已写入的确认信息发送给第二个datanode,而第二个datanode则会把数据已写入的确认信息发送给第一个datanode,然后第一个datanode会发送最终的确认信息(副本因子默认为3的情况下)。
当datanode复制数据块时,客户端只发送一个数据副本,而不考虑复制因子。因此,在Hadoop HDFS写入文件成本并不高,因为在多个datanode上并行地写入多个块。