1 Hadoop 简介与安装
1.1Hadoop 简介
1.1.1 Hadoop 的诞生
Hadoop 是由 Apache Lucene 创始人 Doug Cutting 创建的。它起源于开源搜索引擎 Apache Nutch。Nutch 项目开始于 2002 年,是一个可以运行的网页爬取工具和搜索引擎系统,但是这个系统无法解决数十亿的搜索问题。
1.1.2 Hadoop 的诞生
Hadoop 是由 Apache Lucene 创始人 Doug Cutting 创建的。它起源于开源搜索引擎 Apache Nutch。Nutch 项目开始于 2002 年,是一个可以运行的网页爬取工具和搜索引擎系统,但是这个系统无法解决数十亿的搜索问题。
三篇划时代论文的诞生对 Hadoop 的诞生起到了决定性作用。
第一篇论文:GFS
2003 年谷歌发表了 “The Google File System(谷歌文件系统,简称 GFS)”的论文,GFS 的架构能够满足在网页爬取和索引过程中产生的超大文件的存储需求。于是,在 2004 年 Nutch 团队开始做 GFS 的开源版本实现,也就是 Nutch 分布式文件系统(NDFS)。
第二篇论文:MapReduce
2004 年谷歌发表了“MapReduce:Simplified Data Processing on Large Cluster(大型集群的数据简化处理)”的论文。2005 年,Nutch 团队在 Nutch 上实现了 MapReduce。
2006 年 2 月,Nutch 开发人员将 NDFS 和 MapReduce 移除 Nutch 形成一个独立的项目,命名为 Hadoop。这个名字不是缩写,是生造出来的。
第三篇:BigTable
2006 年谷歌发表了“BigTable:A Distributed Storage System for Structured Data(一个结构化数据的分布式存储系统)”的论文。Powerset 公司根据 BigTable 的思想,发起了 HBase,即 Hadoop Database。
1.1.3Hadoop 重要里程碑
2008 年 1 月,Hadoop 成为 Apache 的顶级项目。背后主要的公司为雅虎,主要用 Hadoop 来支撑雅虎的搜索引擎系统。
2013 年 Hadoop 2.0 发布
2017 年 Hadoop 3.0 发布
1.1.4 Hadoop 主要发行版本
- Apache Hadoop 原始版本
- Cloudera 版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”)
- Hortonworks 版本(Hortonworks Data Platform,简称“HDP”)
- MapR
此外,还有一些其他的发行版,如华为、Intel 等。
1.2Hadoop 生态系统
- Hadoop 从最开始的 HDFS 和 MapReduce 发展至今,已经形成一个庞大的生态系统。主要包括:
- HDFS:分布式文件系统
- YARN:资源管理与调度系统
- MapReduce:分布式处理框架
- Pig、Hive:类 SQL 的数据查询
- Mahout、Spark MLib:机器学习库
- HBase:分布式列数据库
- Zookeeper:集群管理
- Oozie:任务调度
- Flume、Sqoop:数据导入导出
- Solr&Lucene:搜索与索引
- Ambari:集群监控与维护

1.3 Hadoop主要模块
1.3.1Hadoop Common
为其他 Hadoop 模块提供基础支持,可以看做是一个公共库。
1.3.2 HDFS
高吞吐量、高可用的分布式文件系统。

图片来源:http://hadoop.apache.org/docs/r2.7.6/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
HDSF 集群有两类节点,以管理节点(NameNode)-工作节点(DataNode)模式运行。
管理文件系统的命名空间,维护着文件系统树上及整棵树内所有的文件和目录。
文件系统的工作节点,负责存储和检索数据,并将存储的块的列表定期发送给 NameNode 管理节点。
也叫辅助 NameNode,主要作用就是定期合并编辑日志与命名空间镜像,以防止编辑日志过大。
1.3.3 YARN
集群资源管理与任务调度框架
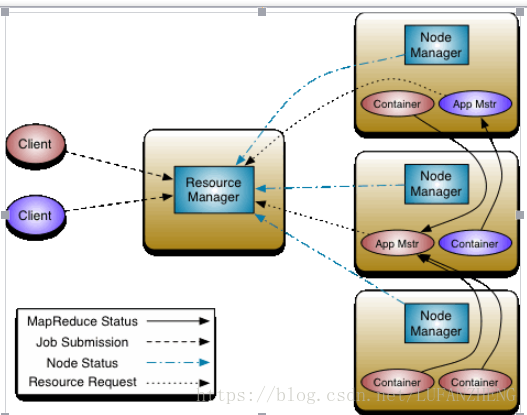
图片来源:http://hadoop.apache.org/docs/r2.7.6/hadoop-yarn/hadoop-yarn-site/YARN.html
YARN 也包含两个核心服务:资源管理器(ResourceManager)和节点管理器(NodeManager)。
管理集群上资源的使用
运行在集群中所有节点上并启动和监控容器。
1.3.4 MapReduce
大数据并行处理框架
