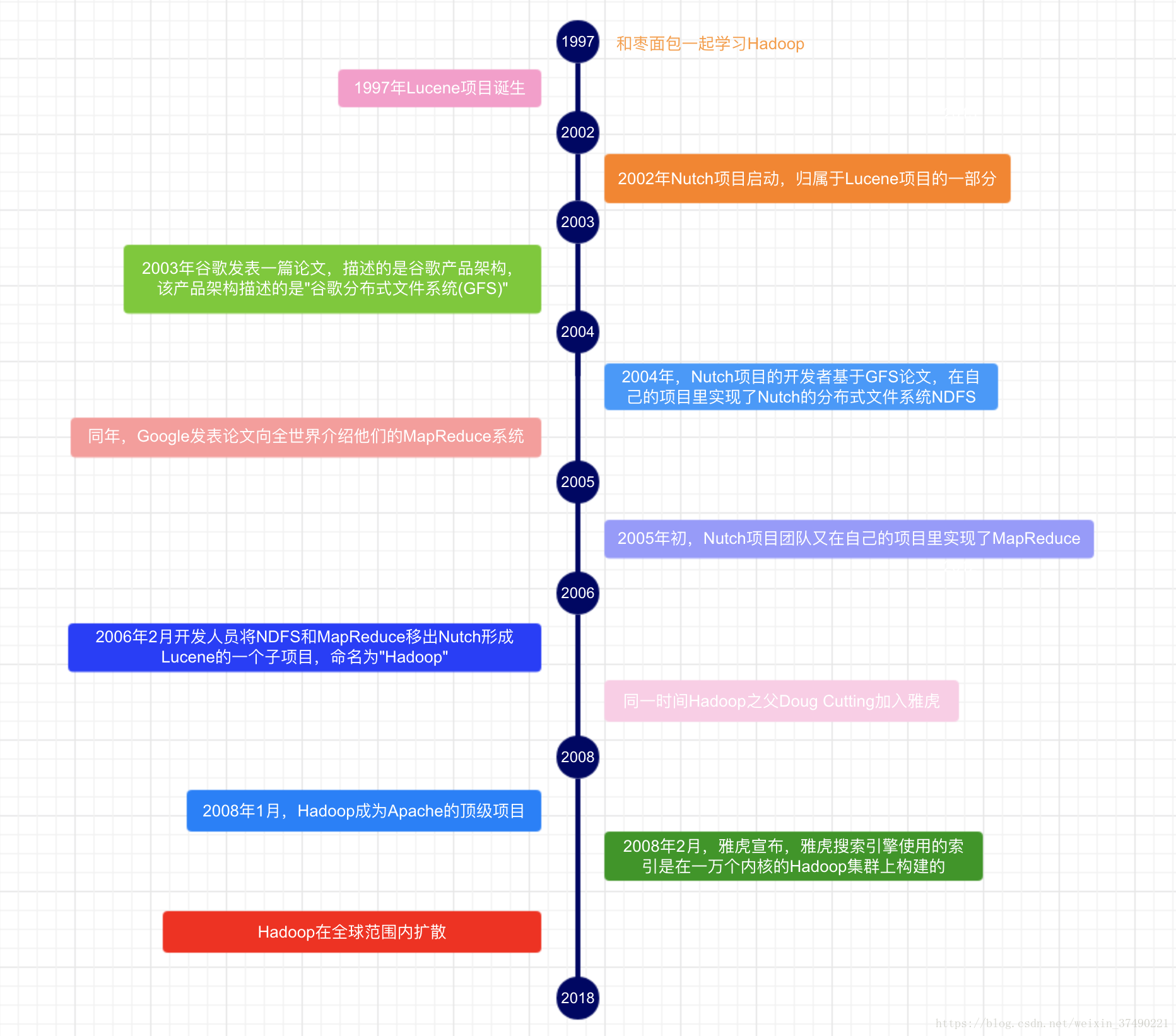
Hadoop起源于Nutch项目。我们几个人有一段时间一直在尝试构建一个开源的Web搜索引擎,但始终无法有效地将计算任务分配到多台计算机上,几十就只是屈指可数的几台。知道谷歌发表了GFS和MapReduce的相关论文之后我们的思路才清晰起来。他们设计的系统已经可以精准地解决我们在Nutch项目中面临的困境。于是,我们开始尝试重建这些系统,并将其作为Nutch的一部分。后台,我们终于让Nutch可以在20台机器上平稳运行了,但很快又意识到一点:要想应对大规模的Web数据计算,还必须得让Nutch能在几千台机器上运行,不过这个工作远远不是两个半天工作制的开发人员能搞定的。差不多就在这个时候,雅虎也对这项技术产生了浓厚的兴趣并迅速组建了一个开发团队。我有幸成为其中一员。我们剥离出Nutch的分布式计算模块,将其称为”Hadoop”。在雅虎的帮助下,Hadoop很快就能够真正处理海量的Web数据了 ———— Doug Cutting
hadoop发展历程
hadoop版本更迭

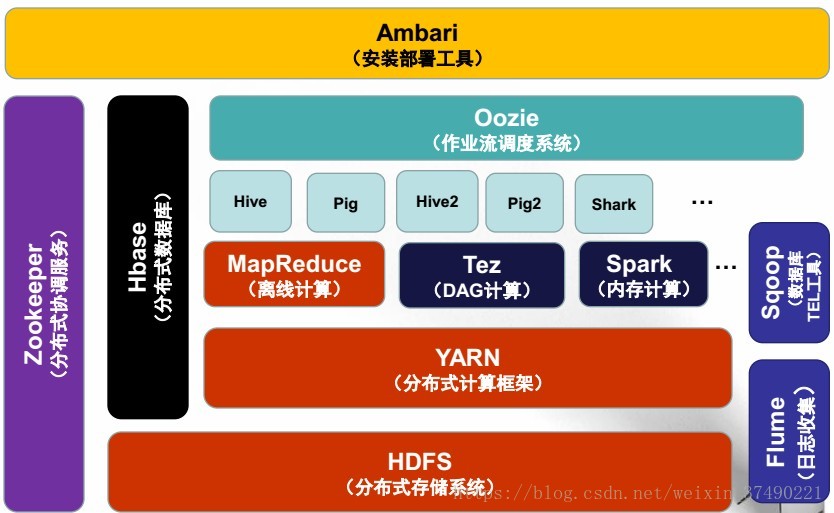
hadoop基本模块
| 模块 | 解释 |
|---|---|
| HDFS | Hadoop的分布式文件系统 |
| MapReduce | Hadoop的数据处理编程模型 |
| YARN | Hadoop的集群资源管理系统 |