概述
Hadoop是Apache提供的开源的海量数据离线处理框架,是最知名的大数据框架之一。
最初来源于Google的三篇论文,由Apache基于论文中的原理进行了开源的实现。
Google的集群系统:GFS、MapReduce、BigTable。
Hadoop的集群系统:HDFS、MapReduce、HBase。
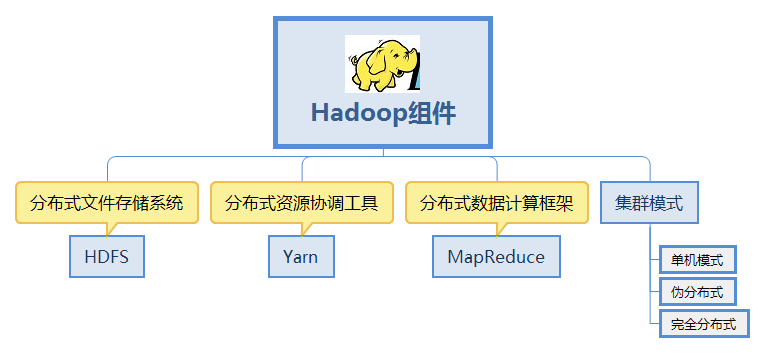
1、组件
其中HDFS和MapReduce组成了Hadoop,并后续在Hadoop2.0中引入了Yarn。所以目前的Hadoop由如下三个组件组成:
HDFS:Hadoop分布式文件存储系统。
MapReduce:Hadoop分布式数据计算框架。
Yarn:Hadoop分布式资源协调工具。
2、最初设计的目的
Hadoop设计的初衷是为了解决Nutch的海量数据存储和处理的需求,可以解决大数据场景下的数据存储和处理的问题。
3、名字的起源
Doug Cutting如此解释Hadoop的得名:“这个名字是我孩子给一头吃饱了的棕黄色大象命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义,并且不会被用于别处。小孩子是这方面的高手。Google就是由小孩命名的。”
二、Hadoop安装配置
1、下载
Hadoop工作需要JDK的支持,请注意下载时对JDK的版本要求。
下载地址:http://hadoop.apache.org/releases.html
2、版本信息
Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0,并且两个版本互不兼容。
第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x最后演化成1.0.x,变成了稳定版。而0.21.x和0.22.x则有NameNode HA等新的重大特性。
第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x、2.x增加了NameNode HA和Wire-compatibility两个重大特性。
3、集群模式
Hadoop的安装分为单机方式、伪分布式方式和完全分布式方式。
1.单机模式
单机模式是Hadoop的默认模式。解压即可使用单机模式。
单机模式不启动任何守护进程、无法使用hdfs和yarn,只能用来进行MapReduce的本地测试、不能用作生产环境。
2.伪分布模式
单机环境下启动所有的守护进程,具有hadoop的完整功能,可以使用hdfs,mapreudce和yarn,但是这些守护进程都运行在同一台机器上,并不能真正的提供性能上的提升,只能用来开发测试,不可以用在生产环境下。
以上是官方的说法,这里需要说一下,伪分布式也是可以用到生产环境的,在数据量不是很大,数据可靠性要求不是很强的时候,可以使用伪分布式,要不完全分布式的计算速度要快!
3.完全分布模式
启动所有的守护进程,具有hadoop完整的功能,可以使用hdfs、mapreduce和yarn,并且这些守护进程运行在集群中,可以真正的利用集群提供高性能,在生产环境下使用。
4、安装
1.单机安装
解压直接运行,就是单机模式。
2.伪分布式安装
参看:hadoop伪分布式安装配置。
3.完全分布式安装
参看:Hadoop完全分布式配置。