Hadoop应该是当前大数据分布式处理最流行的软件框架,它可以使工作人员不充分了解分布式底层原理的情况下开发分布式程序。Hadoop集中解决了大数据处理的两个难点,大数据如何存储和大数据如何计算。
Hadoop的架构思想是怎么来的呢?一切艺术来源于生活,Hadoop也不例外。当年Google在做网页搜索业务时遇到如下两个问题。
(一) 大量的网页数据怎么存储?
(二)怎么给网页排名?
针对第一个问题,Google基于以下假设开发了分布式文件系统——Google File System(GFS)。
1)硬件故障是常态,充分考虑到大量结点的失效问题,需要通过软件将容错以及自动恢复功能集成在系统中。
2)支持大数据集,系统平台需要支持海量大文件的存储,文件大小通常以吉字节计,并包含大量小文件。
3)一次写入、多次读取的处理模式,充分考虑应用的特性,增加文件追加操作,优化顺序读写速度。
4)高并发性,系统平台需要支持多个客户端同时对某一个文件的追加写入操作,这些客户端可能分布在几百个不同的结点上,同时需要以最小的开销保证写入操作的原子性。
下图就是GFS的系统架构图。
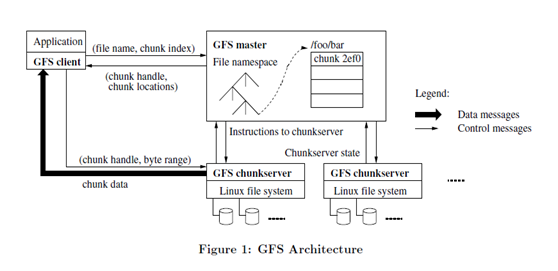
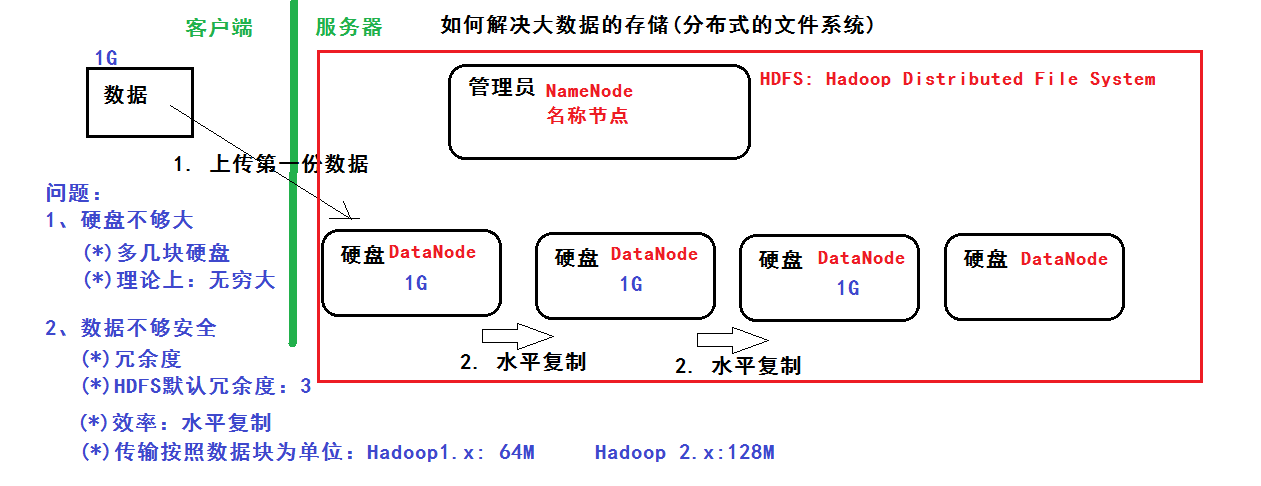
在2003-2004年间,Google公布了部分GFS的思想细节,受此启发的Doug Cutting等人创建了HDFS(Hadoop Distributed File System),这是Hadoop的核心组件之一,用于解决大数据的存储问题。下图为HDFS简化思想图解。
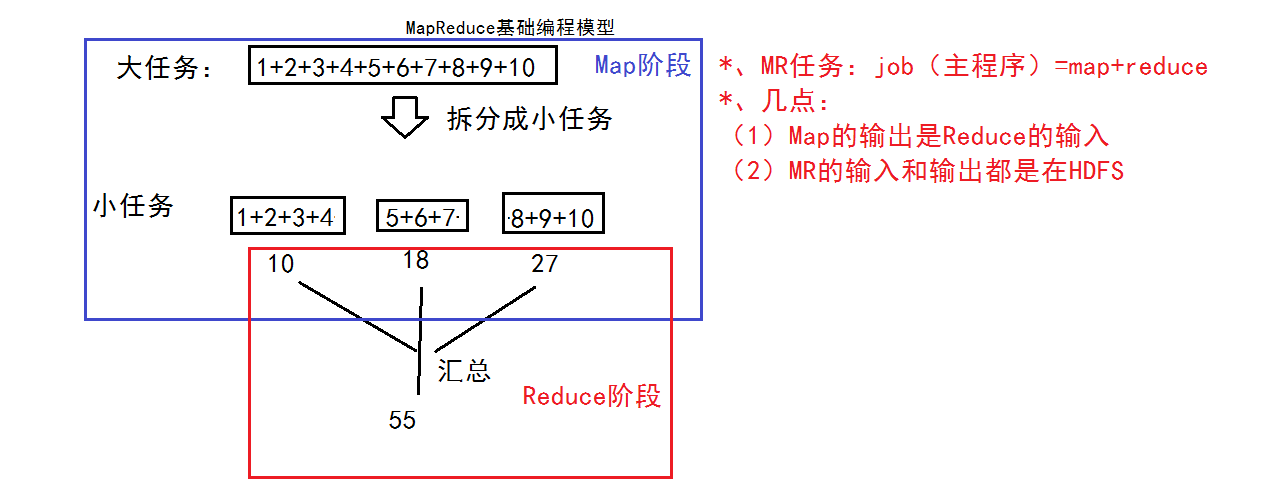
针对第二个问题,Google设计了一个新的抽象模型MapReduce,其简单思想可以理解为把一个大任务拆分成小任务,再进行汇总。下图是以1+2+...+10为例子来介绍MapReduce的思想。
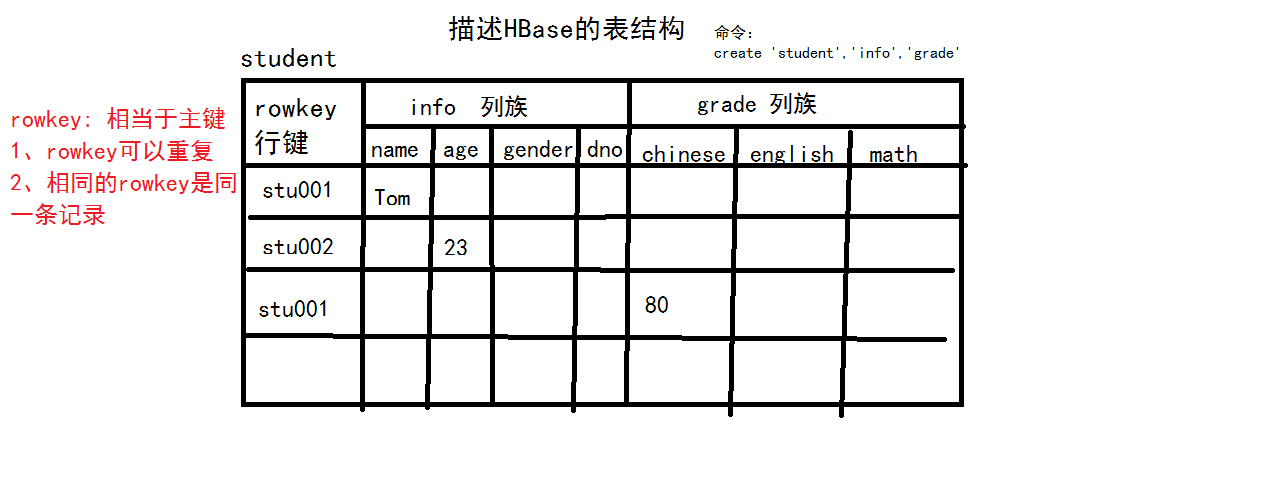
MapReduce也是Hadoop的核心组件之一,解决了大数据如何计算的难点。Google基于GFS设计了一种非关系型数据库BigTable,Hadoop基于HDFS设计了HBase数据库,这也是Hadoop的核心组件之一。下图为HBase数据库的表结构。
HDFS、MapReduce、HBase一起构成了Hadoop的主体。以上就是本篇的全部内容,敬请指教。
获取更多干货请关注微信公众号:追梦程序员。
