1. Hadoop 起源
1.1 Hadoop的身世
首先我们介绍一下Nutch的发展情况,Nutch是一个以Lucene为基础实现的搜索引擎系统,Lucene为Nutch提供了文本检索和索引的API,Nutch不仅仅有检索的功能,还有网页数据采集的功能。
1.2 Hadopop简介
Hadoop本质上起源于Google的集群系统,Google的数据中心使用廉价的Linux PC机组成集群,用其运行各种应用。即使是分布式开发的新手也可以迅速使用Google的基础设施Google采集系统的核心的组件有两个:
- 第一个就是GFS(Google FileSystem ,一个分布式文件系统,隐藏下层负载均衡,冗余复制等细节,对上层程序提供一个统一的文件系统API接口;
- 第二个是MapReduce计算模型,Google发现大多数分布式运算可以抽象为MapReduce操作。
Map是把输入Input分解成中间的Key/Value对,Reduce把Key/Value合成最终输出Output。这两个函数由程序员提供给系统,下层设施把Map和Reduce操作分布在集群上运行,并把结果存储在GFS上。
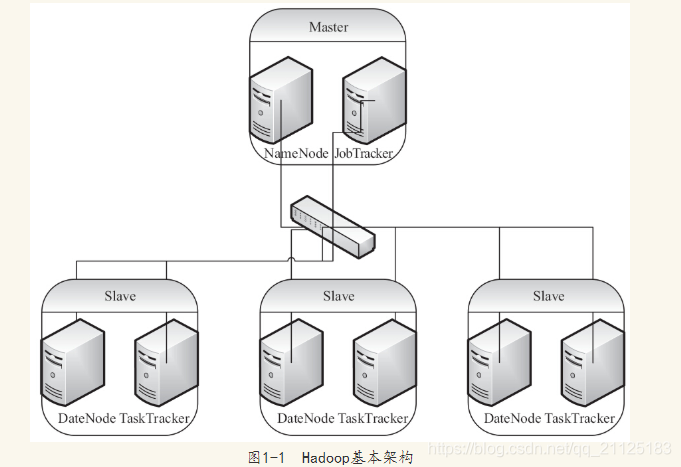
典型的Hadoop由一个Master逻辑节点和多个Slave逻辑节点构成,Master逻辑节点由NameNode和ResourceManager组成,NameNode是HDFS的Master,主要负责Hadoop分布式文件系统元数据的管理工作;ResourceManager是MapReduce的Master,其主要职责就是启动、跟踪、调度各个NodeManager的任务执行,每一个Slave逻辑节点通常同时具有DataNode以及NodeManager的功能。
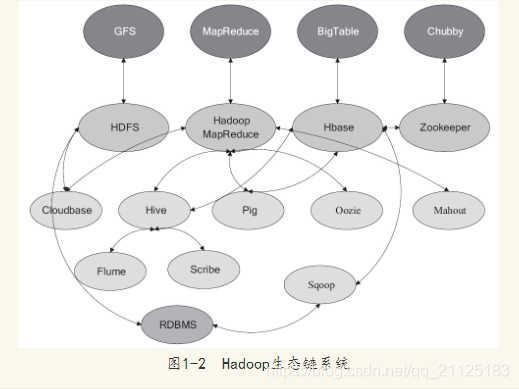
下面我们介绍一下Hadoop整个生态系统:
- HDFS——Hadoop分布式文件系统,GFS的Java开源实现,运行于大型商用机器集
群,可实现分布式存储。 - MapReduce——一种并行计算框架,Google MapReduce模型的Java开源实现,基于其写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理T级别及以上的数据集。
- Zookeeper——分布式协调系统,Google Chubby的Java开源实现,是高可用的和可靠的分布式协同(coordination)系统,提供分布式锁之类的基本服务,用于构建分布式应用。
- Hbase——基于Hadoop的分布式数据库,Google BigTable的开源实现 是一个有
序、稀疏、多维度的映射表,有良好的伸缩性和高可用性,用来将数据存储到各个计算节点上。 - Hive——是为提供简单的数据操作而设计的分布式数据仓库,它提供了简单的类似
SQL语法的HiveQL语言进行数据查询。 - Cloudbase——基于Hadoop的数据仓库,支持标准的SQL语法进行数据查询。
- Pig——大数据流处理系统,建立于Hadoop之上为并行计算环境提供了一套数据工
作流语言和执行框架。 - Mahout——基于HadoopMapReduce的大规模数据挖掘与机器学习算法库
- Oozie——MapReduce工作流管理系统。
- Sqoop——数据转移系统,是一个用来将Hadoop和关系型数据库中的数据相互转
移的工具,可以将一个关系型数据库中的数据导入Hadoop的HDFS中,也可以将HDFS
的数据导入关系型数据库中。 - Flume——一个可用的、可靠的、分布式的海量日志采集、聚合和传输系统
- Scribe——Facebook开源的日志收集聚合框架系统。
2. 大数据、Hadoop和云计算
2.1 大数据
大数据一般是指的是这样的数据:数据量大,需要运用新处理模式才能更具有更强大的决策力、洞察力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据的特征有四个层面:第一,数据量巨大,从TB级别,跃升到PB级别;第二,数据类型繁多,包括网络日志、视频、图片、地理位置信息等;第三,价值密度低,商业价值高,以视频为例,在连续不间断的监控过程中,可能有用的数据仅仅只有一两秒;第四,处理速度快。最后这一点也和传统的数据挖掘技术有着本质的不同。业界将其归纳为4V——Volume、Variety、Value和Velocity
上面我们介绍了大数据的基本概念以及显著的特征,下面我们将从不同的维度来阐述大数据的很细问题:
- 数据态的多样性问题
- 维度复杂性问题
- 大数据存储问题
- 大数据计算分析问题
- 大数据价值挖掘问题
2.2 大数据、Hadoop和云计算的关系
分布式存储架构不仅需要scale up的可扩展性,也需要scale out式的可扩展性,因此大数据处理离不开云计算技术,云计算也为大数据提供弹性可扩展的基础设施支撑环境以及数据服务的高效模式,大数据则为云计算提供了新的商业价值,大数据技术和云计算技术必将有更完美的结合。

3. 设计思想和架构
从计算的角度,再超级的计算机也很难一下处理海量的数据,因而需要分而为之,Hadoop就能将大数据进行分而处理,然后进行归约。
3.1 数据存储和切分
HDFS式Hadoop分布式计算的存储基石,简单总结下来有如下基本特征:
- 对于整个集群有单一的命名空间。
- 数据一致性。适合一次写入多次读取的模型,客户端在文件没有被成功创建之前无
法看到文件存在。 - 文件会被分割成多个文件块,每个文件块被分配存储到数据节点上,而且根据配置
会有复制文件块来保证数据的安全性。
在Hadoop中数据存储涉及HDFS的三个重要角色,分别为:名称节点
(NameNode)、数据节点(DataNode)、客户端。
NameNode可以看做是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息、存储块的复制。NameNode会存储文件系统的Metadata在内存中,这些信息主要包括文件信息,即每一个文件对应的文件块的信息,以及每一个块在DataNode的信息。
DataNode是文件存储的基本单元。它将Block存储在本地文件系统中,保存了Block的Metadata,同时周期性地发送所有存在的Block的报告给NameNodeClient就是需要获取分布式文件系统文件的应用程序。
数据存储中的读取和写入过程,如下:
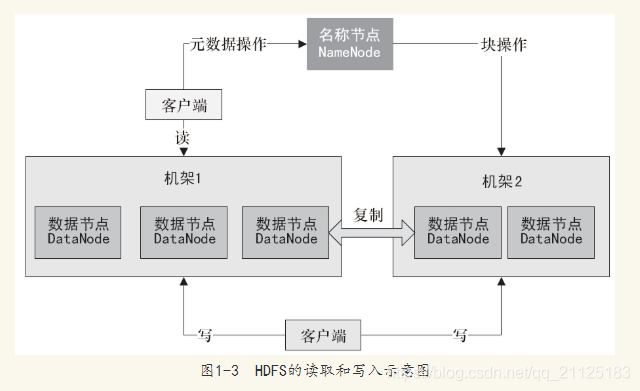
文件写入HDFS的基本流程如下:
- Client向NameNode发起文件写入请求
- NameNode根据文件大小和文件块配置的情况,向Client返回它锁管理的DataNode信息。
- Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入每个DataNode中。
文件读取HDFS的基本流程如下:
- Client向NameNode发起文件读取的请求。
- NameNode返回文件存储的DataNode的信息。
- Client读取文件信息。
在HDFS中复制文件块的基本流程如下:
- NameNode发现部分文件的Block不符合最小复制数或部分DataNode失效。
- 通知DataNode相互复制Block。
- DataNode开始相互复制。
3.2 MapReduce模型
Hadoop向用户提供了一个规范的MapReduce编程接口,用户只需要编写Map和Reduce函数,这两个函数都是运行在键-值基础上,整数的切分,节点之间的通信调度等全部由Hadoop框架本身来负责。
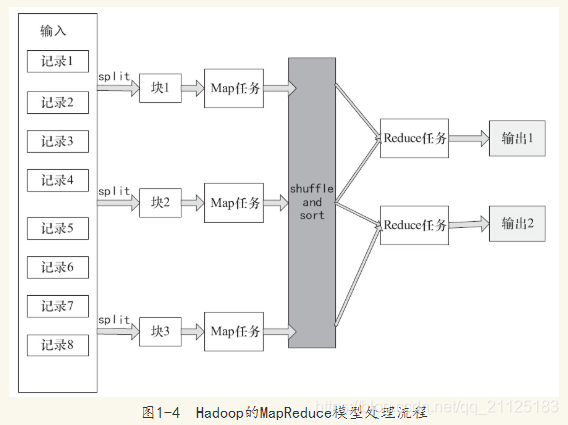
在Map之前会对输入的数据有split的过程,默认split就是写入数据时的逻辑块,每一个块对应一个split,一个split就对应一个Map进程,正是split保证了任务的并行效率。在Map之后还会有shuffle和sort的过程,shuffle简单描述就是一个Map的输出应该映射到哪个Reduce作为输入,sort就是指在Map运行完输出后会根据输出的键进行排序。这两个处理步骤对于提高Reduce的效率及减小数据传输的压力有很大的帮助。
MapReduce基本思想
从本质上讲MapReduce借鉴了函数式程序设计语言的设计思想,其软件实现是指定一个Map函数,把键值对(key/value)映射成新的键值对(key/value)形成一系列中间结果形式的键值对(key/value),然后把它们传给Reduce(归约函数,把具有相同中间形式key的value合并在一起。Map和Reduce函数具有一定的关联性。其算法描述为:
Map(k,v)-> list(k1,v1)
Reduce(k1,list(v1))->list(v1)
在Map过程中将数据并行,即把数据用映射函数规则分开,而Reduce则把分开的数据用归约函数规则合在一起,即Map是个分的过程,Reduce则对应着合。
3.3 MPI和MapReduce
利用MapReduce,程序员能够轻松地编写紧耦合的程序,在运行时能高效地调度和执行任务,在实现时,在Map函数中指定对各分块数据的处理过程,在Reduce函数中指定如何对分块数据处理的中间结果进行归约。用户只需要指定Map和Reduce函数来编写分布式的并行程序不需要关心如何将输入的数据分块、分配和调度,同时系统还将处理集群内节点失败及节点间通信的管理等。
4.Hadoop发行版
4.1 Apache Hadoop
Apache Hadoop是Hadoop最权威的官方版本,就像Linux的内核与Linux的发行版的地位一样,Apache Hadoop版本是所有商业发行版之源,主要组件为HDFS和MapReduce。
4.2 Cloudera Hadoop
Cloudera成立于2008年,是最早将Hadoop用于商业化的公司,为其合作伙伴提供Hadoop的商用解决方案,主要包括支持、咨询服务、培训。
Cloudera的Hadoop发行版在商用中算是最成功的,Cloudera的CDH版本集成了Hadoop、Pig、Flume、HBase、Hcatalog、Hive、Hue、Mahout、Oozie、Sqoop、Whirr以及Zookeeper版本,并且也是开源的,最新版本为CDH4.2.0
