Hadoop系列之-MapReduce
MapReduce在Hadoop1.x中直接运行在HDFS上,由JobTracker和TaskTracker负责调度。在Hadoop2.x中运行在YARN上。面对大量数据的离线计算,MR无非是很好的选择,但如果需要高及时性的大数据计算,Spark、Storm是更合适的选择。MapReduce的核心设计理念是分布式计算,简单说就是移动计算而不移动数据。
-
基本功能模块
YARN : 负责资源管理和调度
MapReduceApplicationMaster : 负责切分、任务调度、任务监控和容错等
MapTask/ReduceTask : 任务驱动引擎
-
每个MapReduce作业对应一个MapReduceApplicationMaster,MRAppMaster负责整体任务调度,YARN将资源分配给MRAppMaster,MRAppMaster再将任务分配给MapTask/ReduceTask
-
MapReduceApplicationMaster容错
失败后,由YARN重新启动
任务失败后,MRAppMaster重新申请资源
概念
-
MapReduce
-
MR整体框架
MR的整个过程由以下构成:
-
Split
将数据按配置好的大小(如一个block是64M将其切分为3份,也就是25M+25M+14M)切分,并传给不同的MapTask。
-
Map
Map对文件逐行读出并解析,解析完毕后以K,V的格式输出。
-
Shuffle
在交付ReduceTask之前,输出的过程中可以配置Shuffle,Shuffle可对数据先Sort再Combiner,以减小Reduce的工作量。在ReduceTask端,Shuffle会对数据先进行聚合,相同Key的所有Value会被整合为一个以Key为首的Value数组
-
Reduce
ReduceTask可根据不同需求对shuffle后的Value数组进行整合统计。如果一次MR计算不够,可执行多次计算。

-
-
假设有一个文件存储这Deer Bear River等word,我们要计算这个文件中各word的总数,那么MR的整套过程是这样的
-
将文件按大小Split为多份
-
Map阶段按行读入,按K,V的结果集输出
-
Shuffle对Map后的数据进行Sort、聚合
-
Reduce对Shuffle后的结果进行统计并输出
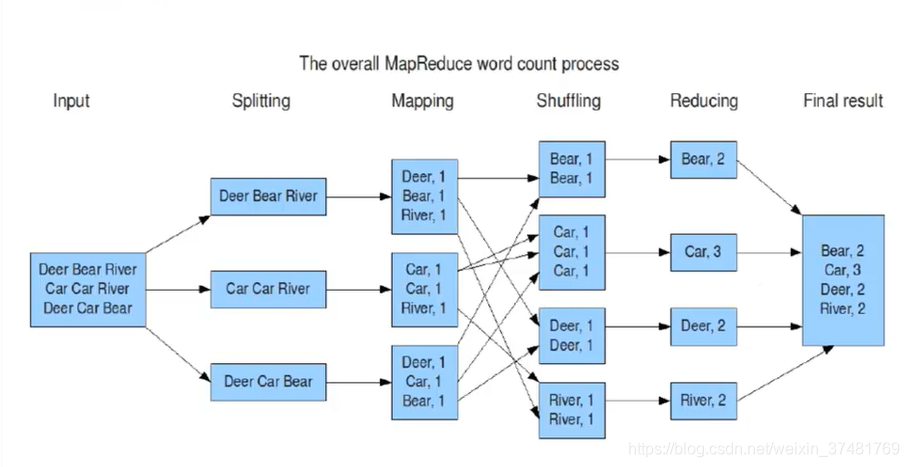
-
-
-
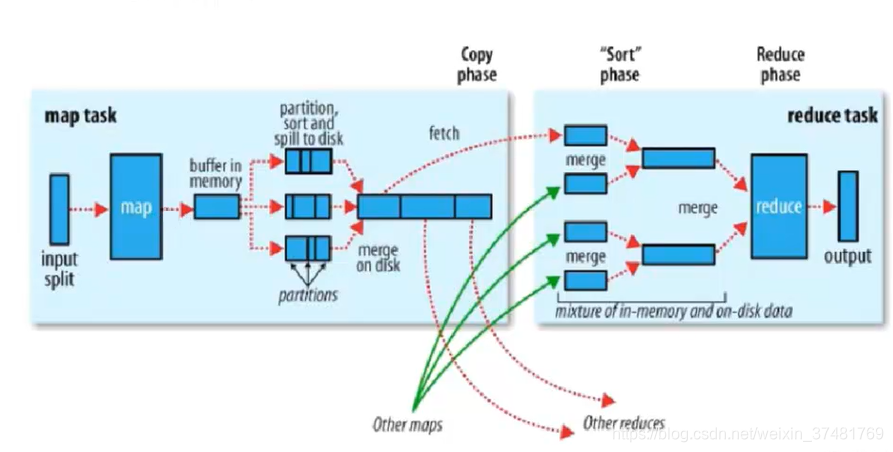
Shuffler
每个MapTask都有一个内存缓冲区(默认是100M),存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,溢写是由单独线程完成,不影响往缓冲区写map结果的线程(split.percent,默认是0.8)。当溢写线程启动后,需要对这80M空间内的key做排序(Sort。)
假如client设置过Combiner,那么现在就是使用Combinerd的时候了。将由相同key的key/value对的value加起来,减少溢写到磁盘的数据量。
当整个map task结束后在对磁盘中这个map task产生的所有临时文件做合并(Merge),对于“word1”就是这样的:{word1:[5,8,2,…]},假如有Combiner,{word1[15]},最终产生一个文件。
reduce从tasktracker copy数据,copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置。merge有三种形式:内存到内存,内存到磁盘,磁盘到磁盘。merge从不同的task tracker上拿到的数据。
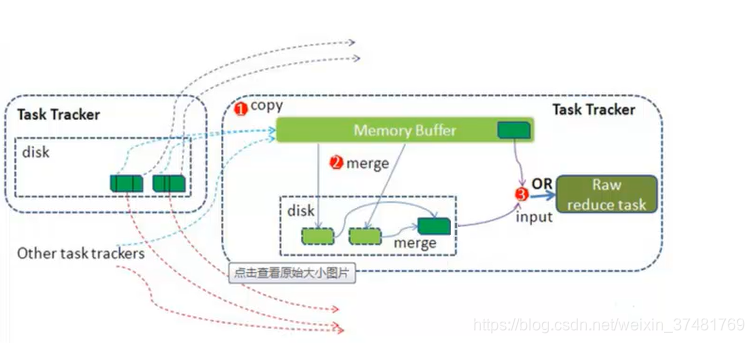
-
Combiner
每一个map可能会产生大量的输出。combiner的作用就是在map端对输出先做一次合并,以减少传输到reducer的数据量。combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能。如果不用combiner,那么,所有的结果都由reduce完成,效率会相对地下,如果使用combiner,先完成的map会在本地聚合,提升速度。
配置
配置笔者就不在此赘述,有需要可以去读官网 http://hadoop.apache.org/docs/
MR执行时Hadoop各进程之间的交互
-
客户端提交一个mr的jar包给JobClient(提交方式:hadoop jar <jar在unix的url> <main方法所在的类的全类名> <参数>)
-
JobClient通过RPC和JobTracker进行通信,返回一个存放jar包的地址(HDFS)和jobId
-
client将jar包写入到HDFS当中(path = hdfs上的地址 + jobId)
-
开始提交任务(任务的描述信息,不是jar, 包括jobid,jar存放的位置,配置信息等等)
-
JobTracker进行初始化任务
-
读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask
-
TaskTracker通过心跳机制领取任务(任务的描述信息)
-
下载所需的jar,配置文件等
-
TaskTracker启动一个java child子进程,用来执行具体的任务(MapperTask或ReducerTask)
-
将结果写入到HDFS当中
小试牛刀
我们做一个简单的MapReduce,现在有三个文件a.txt、b.txt、c.txt,每个文件中有大量单词,通过MR计算后,我们要得出的结果是:wordname a.txt->28 b.txt->11 c.txt->22,并将其存储在一个文件中
a.txt
name age sex flower
name flower sex age
name flower sex age
name flower sex age
name flower sex age
b.txt
name sex age
name flower sex age
name flower age
flower sex age
name flower sex
c.txt
name flower sex age
name flower sex age
name flower sex age
pom.xml
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.2</version>
<exclusions>
<exclusion>
<artifactId>jdk.tools</artifactId>
<groupId>jdk.tools</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.5.2</version>
<exclusions>
<exclusion>
<artifactId>jdk.tools</artifactId>
<groupId>jdk.tools</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>2.5.2</version>
</dependency>
</dependencies>
Java代码
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* map+reducce
* 实现倒序索引(计算各个单词在不同文件中的个数)
* 输出结果: word a.txt->28 b.txt->11 c.txt->22
*
* 将 a.txt、b.txt、c.txt传到 hdfs://host:port/words
* 执行 hadoop jar ./NormalInverseIndex.jar cn.hadoop.Inverse hdfs://host:port/words hdfs://host:port/result
*
*/
public class NormalInverseIndex {
private static Text k = new Text();
private static Text v = new Text();
//
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 设置jar
job.setJarByClass(NormalInverseIndex.class);
// 设置Mapper相关的属性
job.setMapperClass(IndexMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 设置Reducer相关属性
job.setReducerClass(IndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// job.setCombinerClass(IndexCombiner.class);
// 提交任务
job.waitForCompletion(true);
}
/**
* output:
* key:word
* value:fileName
*/
public static class IndexMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
StringTokenizer st = new StringTokenizer(value.toString());
String fileName = ((FileSplit) context.getInputSplit()).getPath().getName();
while (st.hasMoreTokens()) {
k.set(st.nextToken());
v.set(fileName);
context.write(k, v);
}
}
}
/**
* output:
* key:word
* value:a.txt->28 b.txt->11 c.txt->22
*/
public static class IndexReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
Map<String, Integer> fileNameMap = new HashMap<String, Integer>();
for (Text fileName : values) {
if (fileNameMap.get(fileName.toString()) == null) {
fileNameMap.put(fileName.toString(), 1);
} else {
fileNameMap.put(fileName.toString(), fileNameMap.get(fileName.toString())+1);
}
}
k.set(key.toString());
String vVal = "";
Set<Entry<String, Integer>> set = fileNameMap.entrySet();
for (Iterator<Entry<String, Integer>> iterator = set.iterator(); iterator.hasNext();) {
Map.Entry<String, Integer> en = iterator.next();
vVal += " "+en.getKey()+"->"+en.getValue().toString();
}
v.set(vVal.substring(1));
context.write(k, v);
}
}
}