MapReduce1.0
MapReduce是Hadoop的一大核心,它是是一种编程模型,针对TB级别的海量数据并行完成数据的数据提取、分析和优化,它具有以下特征:
1 本身是一种编程模型框架,思想是分而治之
2 处理的对象是海量数据
3 在大规模集群,HDFS存储
4 并行计算
工作实体主要有4个
客户端:提交MapReduce作业
JobTracker:协调作业运行
TaskTarcker:协调任务运行
HDFS:存储文件
工作流程分6步:
1 提交作业 2 作业初始化 3 任务分配 4 任务执行 5 进程和状态更新 6 作业完成
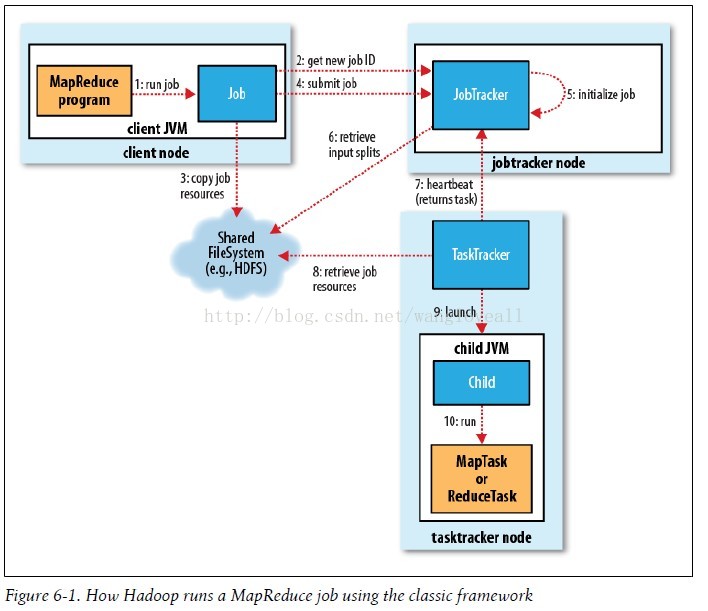
原始的Hadoop1.0整体框架:
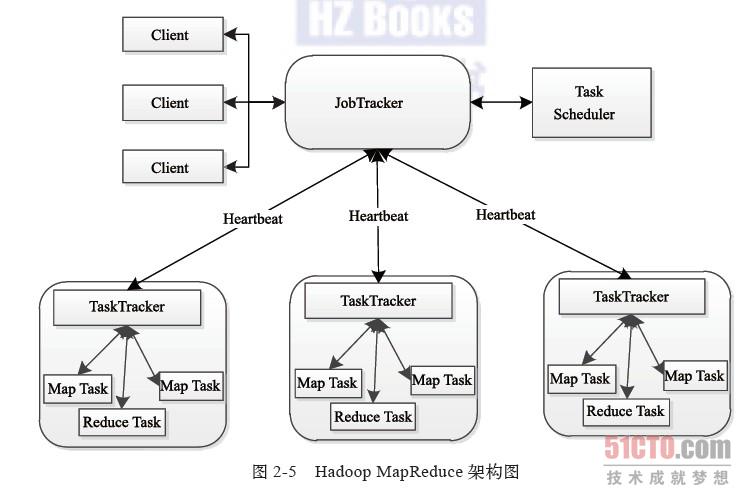
MapReduce2.0(YARN)
新的Hadoop MapReduce框架命名为MapReduceV2或者Yarn,其框架图:

思想是将JobTracker两个主要功能分离成两个单独实体即资源管理和任务调度、监管。新的资源管理器全局管理所有应用程序的资源的分配,针对每一个应用,ApplicationMaster负责调度。一个应用程序无非是一个单独的传统的 MapReduce 任务或者是一个 DAG( 有向无环图 ) 任务。ResourceManager 和每一台机器的节点管理服务器Node Manager能够管理用户在那台机器上的进程并能对计算进行组织。
事实上,每一个应用的 ApplicationMaster 是一个详细的框架库,它结合从 ResourceManager 获得的资源和NodeManager 协同工作来运行和监控任务。
上图中 ResourceManager 支持分层级的应用队列,这些队列享有集群一定比例的资源。从某种意义上讲它就是一个纯粹的调度器,它在执行过程中不对应用进行监控和状态跟踪。同样,它也不能重启因应用失败或者硬件错误而运行失败的任务。
ResourceManager 是基于应用程序对资源的需求进行调度的 ; 每一个应用程序需要不同类型的资源因此就需要不同的容器。资源包括:内存,CPU,磁盘,网络等等。可以看出,这同现 Mapreduce 固定类型的资源使用模型有显著区别,它给集群的使用带来负面的影响。资源管理器提供一个调度策略的插件,它负责将集群资源分配给多个队列和应用程序。调度插件可以基于现有的能力调度和公平调度模型。
上图中 NodeManager 是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况(CPU,内存,硬盘,网络 ) 并且向调度器汇报。
每一个应用的 ApplicationMaster 的职责有:向调度器索要适当的资源容器,运行任务,跟踪应用程序的状态和监控它们的进程,处理任务的失败原因。
工作实体主要有5个
1 客户端:用于提交作业
2 ResourcesManager:管理和协调集群中资源
3 NodeManager:监控本地计算机计算资源单位Container的利用情况
4 Application Master:用来协调MapReduce Job下的Task的运行。它和MapReduce Task 都运行在 Container中,这个Container由RM(ResourcesManager)调度并有NM(NodeManager)管理
5 HDFS:存储