Hadoop之MapReduce概述
1.MapReduce定义
MapReduce是`一个分布式运算程序的编程框架`,是用户开发"基于Hadoop的数据分析应用"的核心框架.
MapReduce核心功能是将用户所编写的`业务逻辑代码`与`自带的默认组件`整合成一个完整的`分布式运算程序`,
`并发`运行在Hadoop集群上.
2.MapReduce优缺点
2.1优点
- 易于编程:
它简单的实现一些接口或继承一些类,就可以完成一个分布式程序,并且这个分布式程序可以发布到大量廉价的计算机上运行.开发人员编写时只要写一个简单的串行程序即可,MapReduce框架会帮你自动实现分布式的过程.这也是MapReduce编程变得流行的原因. - 良好的扩展性:
当你的计算资源将达到饱和时,你可以通过简单的增加机器来扩展它的计算能力. - 高容错性:
MapReduce设计的初衷,就是使程序能够部署在廉价的机器上,所以它必须有很高的容错性,当一台主机挂掉时,它可以把该主机上的任务发给另一台正在运行着的主机,这样就能保证任务的运行.而且这个过程不需要人工参与,是Hadoop自动为我们完成的. - 适合PB级以上海量数据的离线处理:
可以实现上千台服务器集群并发工作,提供数据处理能力.
2.2缺点
- 不擅长实时计算:
一个字慢,MapReduce无法像Sql语言一样,以毫秒级的速度返回结果. - 不擅长流式计算:
流式计算的数据输入是动态的,而MapReduce的输入数据集是静态的,不能动态变化. - 不擅长DAG(有向图)计算
多个应用程序存在依赖关系,一个应用程序的输入为前一个应用程序的输出,MapReduce并不是不能实现这种方式,而只是处理过程中的每一个MapReduce作业的结果都会输出到磁盘,会造成大量的磁盘IO,导致性能十分低下.
3.MapReduce核心编程思想
- MapReduce运算程序往往至少被划分成2个阶段:
Map阶段和Reduce阶段 - Map阶段的MapTask并发实例,完全并行,互不相干.
- Reduce阶段的ReduceTask并发实例,互不相干,但是Reduce的输入数据依赖于Map阶段所有MapTask并发实例的输出.
- MapReduce只包含一个Map阶段和一个Reduce阶段,如果用户的业务特别复杂,那么只能多个MapReduce串行运行.
4.MapReduce进程
一个完整的MapReduce程序在分布式运行时,有三类实例进程:
- MRAppMaster:负责整个程序的调度及状态协调.
- MapTask:负责Map阶段的数据处理流程.
- ReduceTask:负责Reduce阶段的数据处理流程.
5.MapReduce样例WordCount源码分析
分析后不难发现,WordCount类主要包含三部分:
- Map类
- Reduce类
- 驱动类
并且类中所使用的数据类型有很多Hadoop在Java数据类型基础上封装的可序列化数据类型.
5.1常用数据序列化类型
| Java数据类型 | HadoopWritable类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| FLoat | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
String |
Text |
| Map | MapWritable |
| Array | ArrayWritable |
熟悉Java的同学一定很好记,除了String对应的是Text之外,其他的就在后面加个Writable就ok了.
6.MapReduce编程规范
- Mapper部分
(1)用户自定义的Mapper需要继承Mapper类.
(2)Mapper的输入数据是K,V对的形式,K,V的类型可以自定义.
(3)Mapper的业务处理逻辑需要写在map方法中.
(4)Mapper的输出数据是K,V对的形式,K,V的类型可以自定义.
(5)map()方法(MapTask进程)对每一对<K,V>调用一次. - Reducer部分
(1)用户自定义的Reducer需要继承Reducer类.
(2)Reducer的输入数据类型也是K,V对,并且需要对应Mapper的输出数据类型.
(3)Reducer的业务处理逻辑需要写在reduce方法中.
(4)ReduceTask进程对每一组相同K的<K,V>调用一次reduce()方法. - Driver部分
相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的Job对象.
7.WordCount实操
- 需求:统计给定文本文件中,每一个单词出现的次数.
- 代码示例
Mapper
package wordcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WcMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private final LongWritable one = new LongWritable(1);
private Text val = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] lines = value.toString().split(" ");
for (String line : lines) {
val.set(line);
// val是代表每个单词的内容,one则是数值1.
// (K,V) ===>> ("test",1)
// 统计的时候只需要将K,V对中的V值累加即可达到统计目的
context.write(val, one);
}
}
}
Reducer
package wordcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WcReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable value = new LongWritable();
int sum;
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
sum = 0;
// 每组Key相同的数据会调用一次reduce方法
for(LongWritable val : values) {
sum += val.get();
}
value.set(sum);
context.write(key, value);
}
}
Driver
package wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WcDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 这里是本地环境做的测试
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 使用到的驱动类
job.setJarByClass(WcDriver.class);
// Mapper类
job.setMapperClass(WcMapper.class);
// Reducer类
job.setReducerClass(WcReducer.class);
// Mapper输出的Key的数据类型
job.setMapOutputKeyClass(Text.class);
// Mapper输出的Value的数据类型
job.setMapOutputValueClass(LongWritable.class);
// Reduce输出的Key的数据类型
job.setOutputKeyClass(Text.class);
// Reduce输出的Value的数据类型
job.setOutputValueClass(LongWritable.class);
// 输入源,为该目录下的所有文件
FileInputFormat.addInputPath(job, new Path("i:\\wc_input"));
// 输出目标目录
FileOutputFormat.setOutputPath(job, new Path("i:\\wc_output"));
boolean rtn = job.waitForCompletion(true);
System.exit(rtn ? 0 : 1);
}
}
本地运行成功后,我们可以通过maven将Driver打包成jar(并在jar包中添加依赖的类),放到Hadoop集群上运行.
需要配置maven的pom.xml,添加如下内容,版本的话看公司要求或个人喜好.
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>wordcount.WcDriver.java</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
如果和我一样,用的是Idea的社区版本
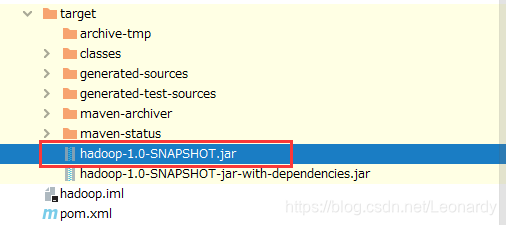
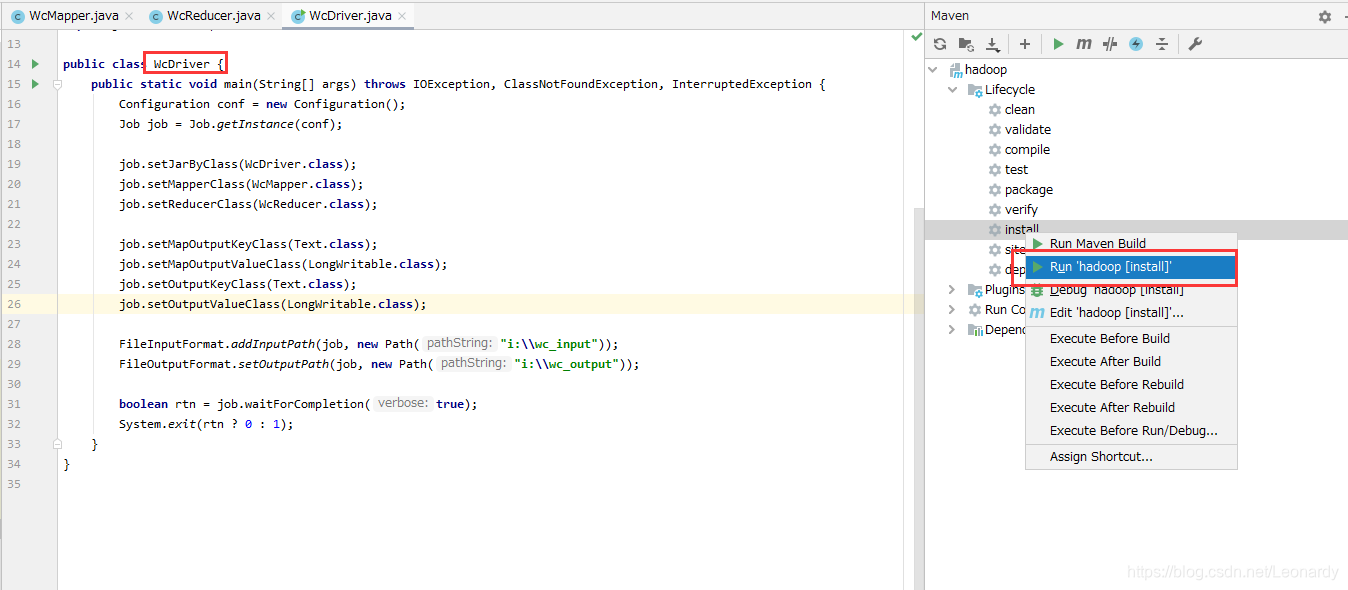 成功后会有2个jar文件,将名称中不含有
成功后会有2个jar文件,将名称中不含有jar-with-dependencies的jar文件改名为wc.jar然后上传到hadoop集群运行一下.
注意:
打包在集群上运行时,别忘了把输入和输出路径该为参数形式:
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
条件有限,我用的是腾讯云免费试用15天的服务器,1核,1G内存,1M带宽,50G硬盘,所以我是用docker搭的集群,如果有想了解的朋友,我后期会更新博客.或者如果有同样试用docker搭建集群的朋友可以用下面的命令将wc.jar包拷贝到docker容器中.
sudo docker cp wc.jar master:/opt/softwares/hadoop/
然后集群中验证下.
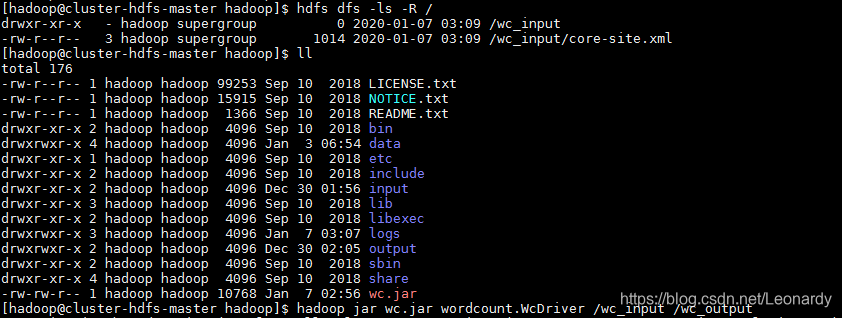
hadoop jar wc.jar wordcount.WcDriver /wc_input /wc_output

