1.MapReduce基础概念
答:MapReduce作业时一种大规模数据的并行计算的便程模型。我们可以将HDFS中存储的海量数据,通过MapReduce作业进行计算,得到目标数据。
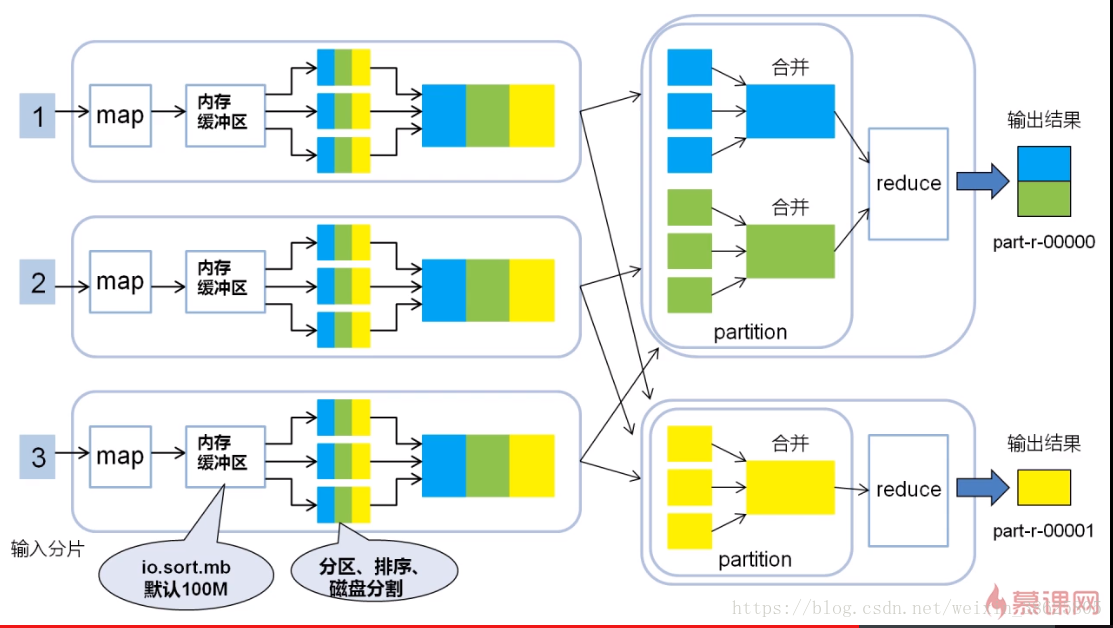
2.MapReduce的四个阶段
答:Split阶段、Map阶段(需要编码)、Shuffle阶段、Reduce阶段(需要编码),下面以WordCount为例。
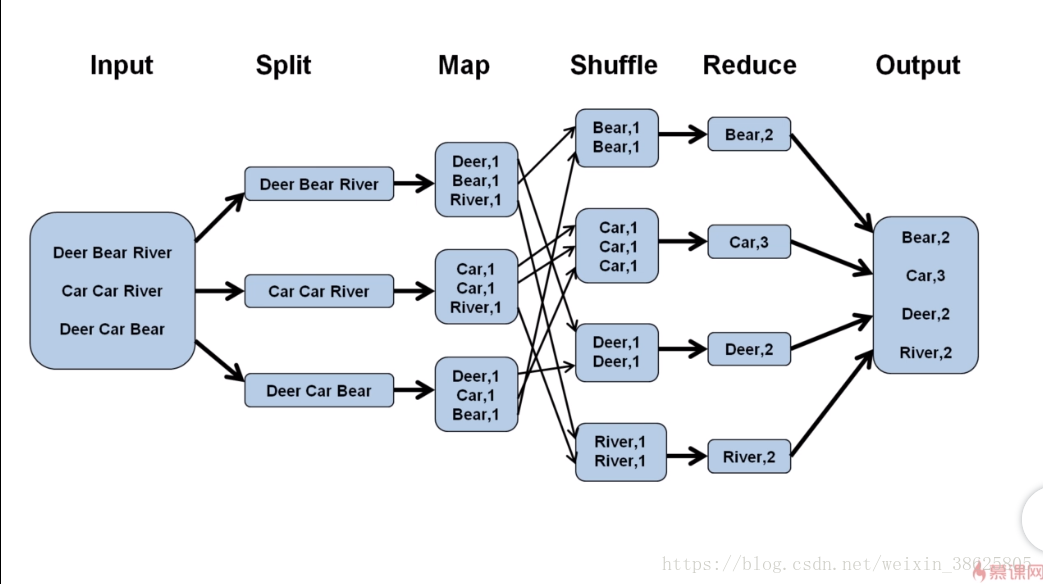
3.从分片到Map
答:我们知道输入的文件时存在DataNode的block之中,Hadoop1.0默认的block大小为64M,Hadoop2.0大小为128M,可以在hdfs-site.xml中设置参数:dfs.block.size。
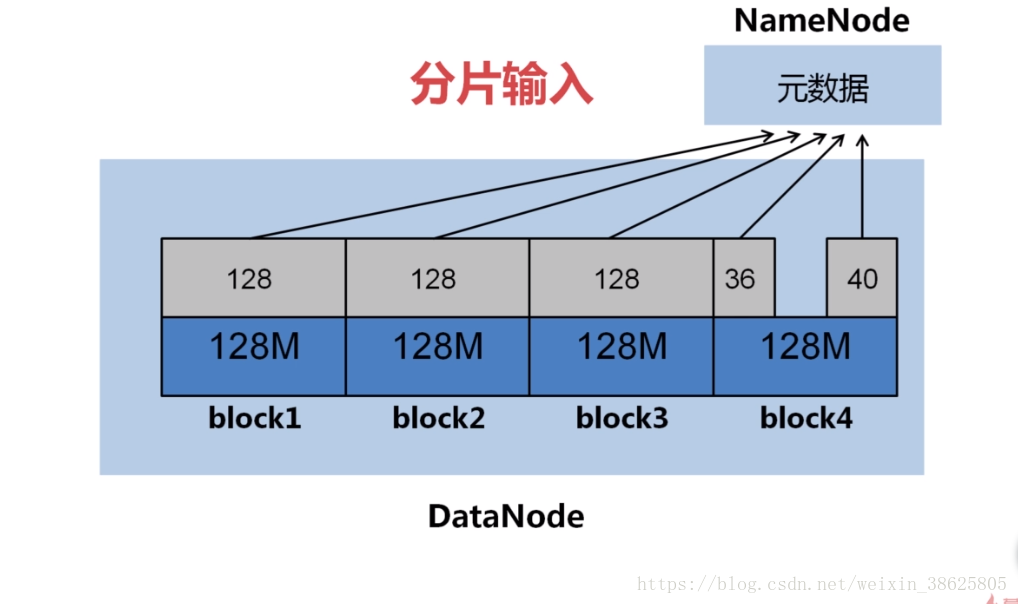

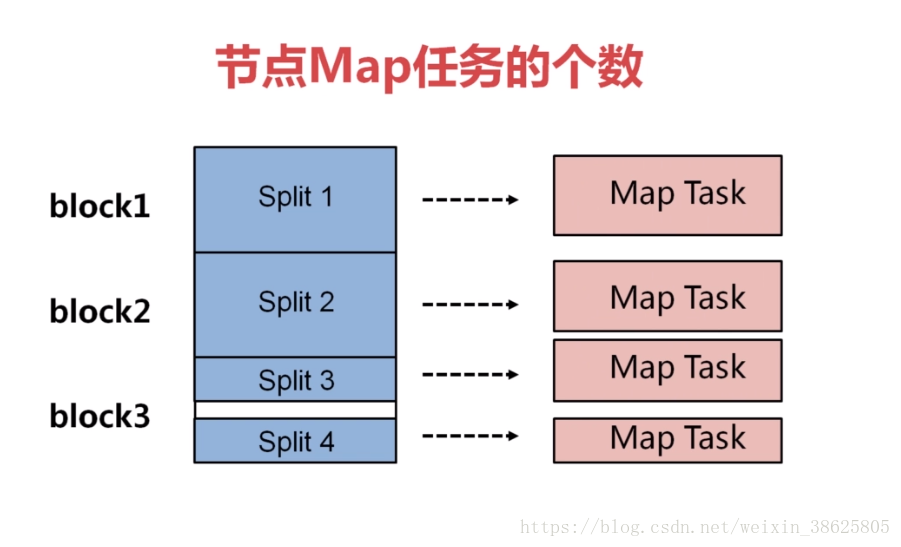

4.控制Map任务的个数在一个合理的范围之内

5.Map——Shuffle——Reduce