Hadoop - HDFS
简介
Hadoop Distributed File System,分布式文件系统
结构
block:
1.数据存储的基本单位,一般情况为64M
2.大文件会被拆分成块,存储于不同机器,如果文件大小低于block大小,那么block大小为实际文件大小
3.读写操作,每次读写一个block
3.block会被复制到多个机器上(Replication)
NameNode:
1.存储文件的元数据信息(metadata),比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的。。整个HDFS可以存储的文件数目取决于NameNode内存的大小
2.每个block在NameNode中对应一条记录,大小一般为150字节,如果有大量小文件,那么会消耗大量内存。同时MapReduce处理大量小文件会产生大量的map task,线程管理开销将会增加作业时间。所以建议存储大文件
3.定时持久化到磁盘上,但是不会保存block的位置信息,DataNode注册时上报和运行时维护
4.如果NameNode失效,整个HDFS都失效
Secondary NameNode:
听起来像是NameNode的备份,实则不然。
看图:
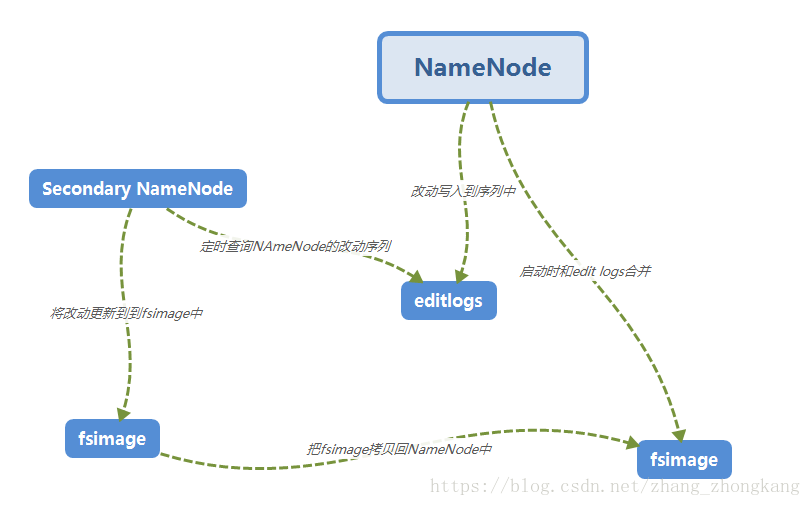
fsimage - 它是在NameNode启动时对整个文件系统的快照
edit logs - 它是在NameNode启动后,对文件系统的改动序列
如图,当NameNode启动时,会把改动序列edit logs 合并进fsimage中,从而得到一个最新的文件系统快照,但是实际上NameNode很少重启,那么一旦NameNode崩溃,所有改动都会丢失。这时候secondary NameNode作用体现了,你可以把它当做一个NameNode的监听器,会定时读取NameNode的edit logs 一旦有更新,他会更新fsImage(secondary NameNode自己的fsimage),一旦发现改动,他会把改动拷贝到NameNode中
DataNode:
-
保存具体的block数据
-
负责数据的读写操作和复制操作
-
DataNode启动时会向NameNode报告当前存储的数据块信息,后续也会定时报告修改信息
- DataNode之间会进行通信,复制数据块,保证数据的冗余性