阅读本文之前,默认已经搭建好了Hadoop集群。
文章目录
前言
提示:以下是本篇文章正文内容,下面案例可供参考
一、HDFS
概述:
HDFS是hadoop的一个分布式文件系统,用于存储文件,通过目录树目录树来定位文件。因为HDFS是分布式的,那么就需要多台服务器配合来完成文件的存储。
HDFS适用于一次写入,多次读出的场景。一个文件一旦经过创建,写入,关闭之后就不需要改变。比如一个文件已经写入部分数据,后续如果想要修改原来的数据,是不支持的,但是可以继续往这个文件后边追加数据。
优点:
- 高容错性,数据会自动保存多个副本,从而通过增加副本的形式,提高容错性。当某一个副本丢失时,会自动恢复。
- 适用于大数据,当数据量达到GB,TB甚至PB的时候,使用HDFS能能够很好的处理。
- 适用于大量文件,当文件数量达到百万规模甚至更高,HDFS也能处理。
- 可以构建在廉价机器上。
缺点:
- 不适用于低延迟的数据访问。比如毫秒级别的数据存储以及访问,是无法做到的。
- 无法高效的处理大量小文件的存储。因为文件太小,存储在NameNode上的块信息就越多,会导致NameNode的内存大量的被占用。并且小文件贝多,占用的块信息就比较多,那么查找块信息的时间可能都要比读取文件的时间都要多。
- 不支持多线程写文件,一个文件只能由一个线程来写,不允许有多个线程同时写。
- 只支持文件的追加,但是不支持文件的修改。
HDFS组成:
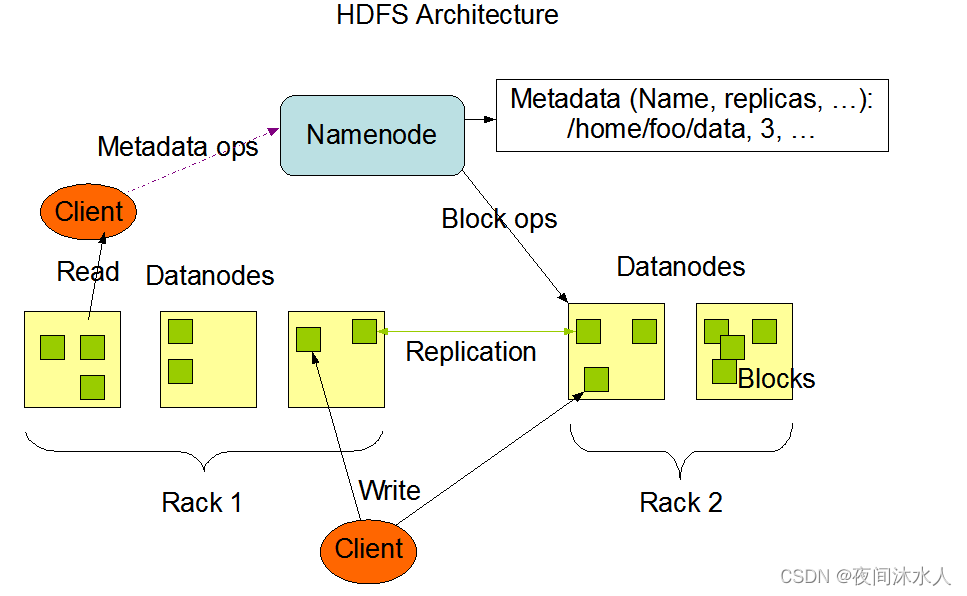
NameNode:
Master角色,就是一个管理者。监听DataNode的活动,NameNode每3秒会收到DataNode心跳检测,如果超过10分钟没有收到DataNode的心跳,那么会继续等待30秒,如果还是没有收到DataNode的心跳,那么此时才会判定该DataNode不可用。
- 管理HDFS的名称空间
- 管理副本策略,管理每一个文件块的副本数量,不同的文件块可以设定不同的副本数。
- 管理的文件块的存储信息,每一个文件块大小默认为128M。
- 处理客户端的读写请求,因为NameNode中存储了所有的文件块的信息。
DataNode:
Slave角色,NameNode下达读写命令,DataNode执行实际的操作。在DataNode启动后,会主动向NameNode注册,注册成功后,周期性(默认6小时)的上报自已所存放的所有的block块的信息,并且每3秒和NameNode进行心跳检测,同时带回NameNode给DataNode下达的命令。
- 储存实际是的数据。
- 执行实际的读写操作。
Client:
就是客户端。
- 文件切分,文件在上传的时候,根据NameNode的文件块的大小进行文件切分,文件块大小默认为128M,最常见的还有256M大小的文件块。
- 与NameNode进行交互,查找文件位置信息。
- 与DataNode进行交互,实际上读写文件。
- 提供API管理DataNode。
Secondary NameNode:
不属于NameNode的热备份,也就是说,当NameNode奔溃之后,不能立即取代NameNode,它只是分担NameNode的工作量,并且在紧急情况下,协助恢复NameNode。2NN会定期的对NN的数据进行合并处理。
HDFS工作机制:
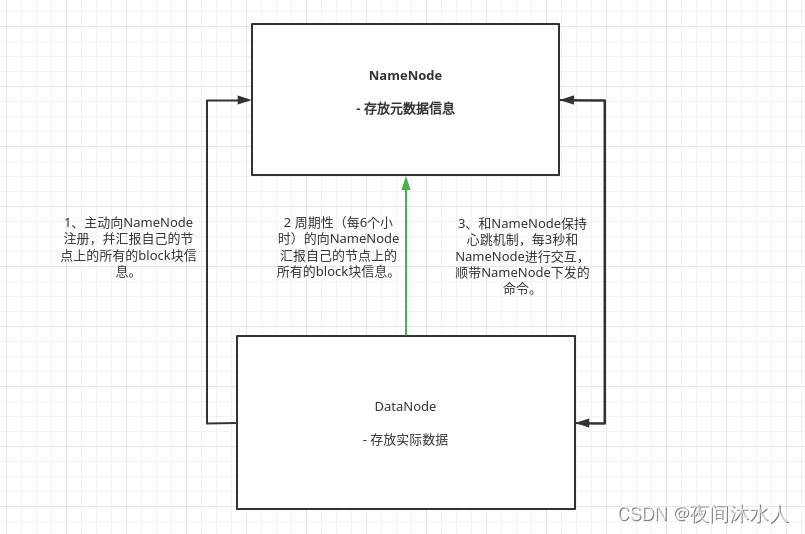
NN于DN工作机制:
-
NN启动后,会将fsimage和edits加载到内存,生成一份完成的元数据信息。
-
后续client端的操作,NN会先记录日志,追加到Edits中,再更新内存。
-
DN启动后,会立即主动向NN进行注册,幷且附带自己节点上的block信息,以后会周期性的向NN汇报自己的block信息(默认6小时,dfs.blockreport.intervalMsec,汇报前,DN会自查自己的block信息,默认6小时,dfs.datanode.directoryscan.interval)。
-
DN会周期性的和NN保持心跳(默认3秒,dfs.heartbeat.interval),过程中会附带NN下发给DN的命令,NN如果超过10分钟没有收到DN的心跳,在等待30秒后,认定该DN不可用,并将该DN从集群中剔除。计算公式:
TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval = 10分钟 + 30秒。
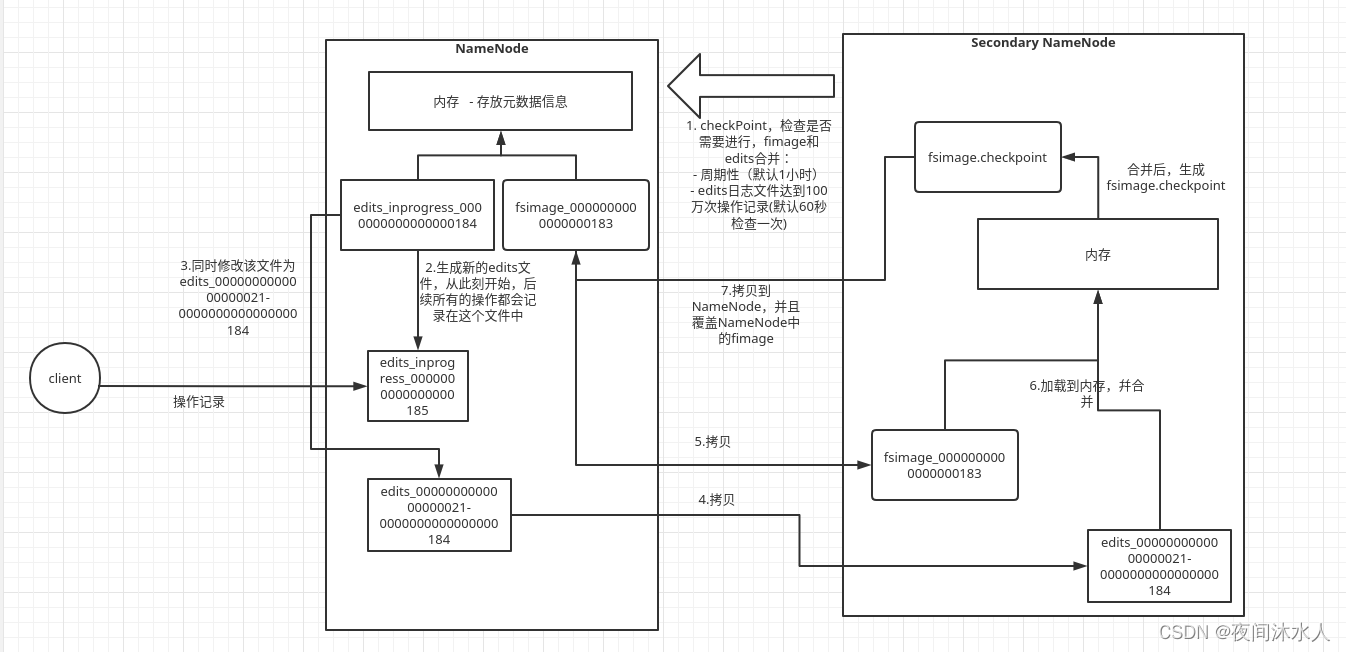
NN与2NN工作机制:
-
NN启动后,会将fsimage和edits加载到内存,生成一份完成的元数据信息。
-
后续client端的操作,NN会先记录日志,追加到Edits中,再更新内存。
-
2NN会周期性的访问NN(checkPoint):(1)定时任务时间到(默认1小时,dfs.namenode.checkpoint.period)。(2)Edits中日志写满了(一百万条记录,dfs.namenode.checkpoint.txns,也是周期性的去检查文件是否达到一百万条记录,(默认60秒,dfs.namenode.checkpoint.check.period))。访问期间,NN会先滚动edits_inprogress_0000000000000000184日志文件生成edits_inprogress_0000000000000000185,并同时将edits_inprogress_0000000000000000184文件修改成edits_0000000000000000021-0000000000000000184文件,那么从此刻开始,后续的的客户端的操作将会别记录到edits_inprogress_0000000000000000185文件中。
-
同时,2NN将拷贝fsimage_0000000000000000183和edits_inprogress_0000000000000000184到自己的服务器上并加载到内存,生成fsimage.checkpoint,那么此时的fsimage.checkpoint就是当前时点最新的元数据信息。并将fsimage.checkpoint拷贝到NN,幷修改名称覆盖原来NN上的最新的fimage。此时的fimage镜像和edits_inprogress_0000000000000000185组合起来将会是下一个时点最新的元数据,也是下一次2NN将要进行合并的文件。
拓展,NameNode被格式化后,会生成以下几个文件:
-
fimage文件:HDFS文件数据的一个永久性检查点,保存了HDFS文件系统的所有的目录信息以及文件inode的序列化信息。可使用hdfs oiv -p XML -i fsimage_0000000000000000183 -o /opt/fsimage_0000000000000000183.xml命令将fimage文件转化成xml文件查看(hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后的文件路径)。
-
edits文件:保存了对集群的中数据的操作记录,只能不断的追加操作。可使用hdfs oev -p XML -i edits_inprogress_0000000000000000273 -o /opt/edits_inprogress_0000000000000000273.xml命令将edits文件转化成xml文件查看(hdfs oev -p 文件类型 -i edits文件 -o 转换后的文件路径)。
-
seen_txid文件:保存的是一个数字,这个数据就是当前最新的fimage编号。
-
VERSION:保存了当前NameNode空间ID,集群ID等。NameNode就是通过jiqunID和DataNode进行交互的。
-
HDFS文件块:
HDFS在物理上是分块村存储数据,块的大小可以通过参数(dfs.blocksize)设置,Hadoop2.X/3.x中默认是128M,1.X默认是64M。
- 如果寻址时间为10ms,那么就是说从查找block1到目标block的时间为10ms。
- 寻址时间为传输时间的1%时为最佳状态,因此,传输时间=10ms/1%=1000ms=1s。
总结:文件块的大小设置应该取决与磁盘的读写速率。
HDFS的shell操作:
hadoop fs 或者hdfs dfs,用法都是一样的。
(1). -mkdir
创建一个测试文件夹:hadoop fs -mkdir /xiyouji
(2). -moveFromLocal
将本地文件sunwukong.txt剪贴上传到hdfs:hadoop fs -moveFromLocal ./sunwukong.txt /xiyouji

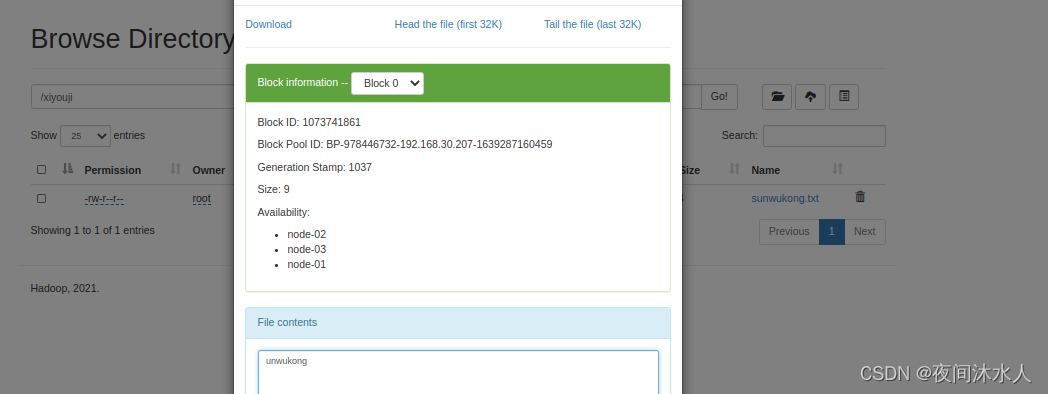
(3). -copyFromLocal
将本地文件sunwukong.txt复制上传到hdfs:hadoop fs -copyFromLocal ./shaseng.txt /xiyouji

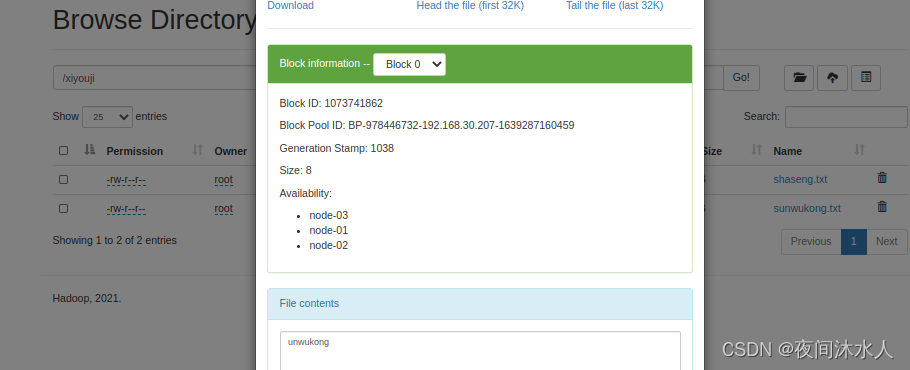
(4). -put (和-copyFromLocal效果是一样的)
将本地文件zhubajie.txt复制上传到hdfs:hadoop fs -put ./zhubajie.txt /xiyouji
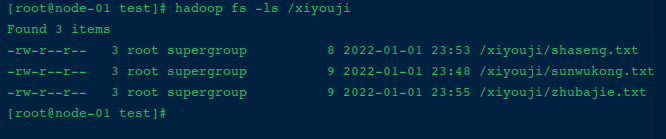
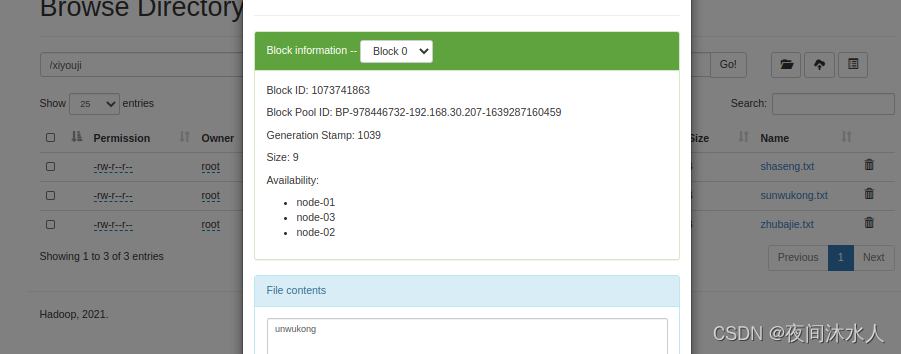
(5). -appendToFile
追加一个文件到已经存在的文件末尾,将jingunbang.txt追加到sunwukong.txt后边:hadoop fs -appendToFile ./jingunbang.txt /xiyouji/sunwukong.txt
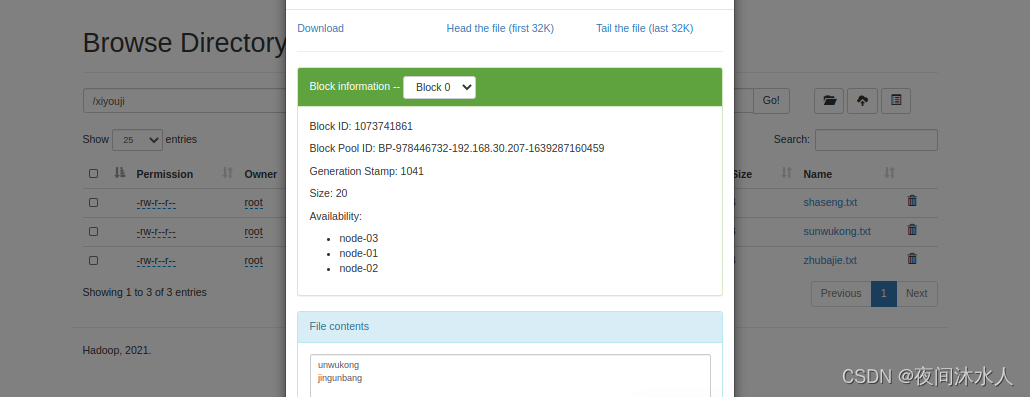
(6). -copyToLocal
从HDFS上拷贝文件到本地,可以更改文件名字。:hadoop fs -copyToLocal /xiyouji/sunwukong.txt ./sunwukong1.txt

(7). -get(用法和-copyToLocal一样)
从HDFS上拷贝文件到本地,可以更改文件名字。:hadoop fs -get /xiyouji/sunwukong.txt ./sunwukong2.txt

(8). -ls | -cat | -chmod | -chown | -mkdir | -cp | -mv | -tail | -rm | -rm -r(递归删除目录里面的所有文件)
这些命令和linux命令功能用法是一样的。
(9). -du
统计文件夹的总的大小信息: hadoop fs -du -s -h /xiyouji

统计文件夹中的每个文件的大小信息: hadoop fs -du -h /xiyouji

(10). -setrep
设置文件的副本数量:hadoop fs -setrep 5 /xiyouji/sunwukong.txt

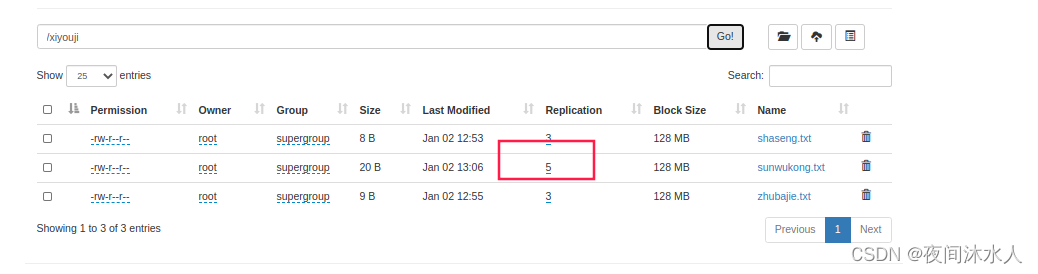
这里虽然设置里sunwukong.txt的副本数量为5,但是因为只有三台机器,那么实际上sunwukong.txt的副本数量还是3,直到机器数量达到5台的时候,sunwukong.txt的副本数量才能真正的变成5。
HDFS数据完整性:
奇偶位校验:数据传输时,后边增加一个校验位,存放2进制数据中的1的个数标志,如果为偶数,则为0,否则为1。
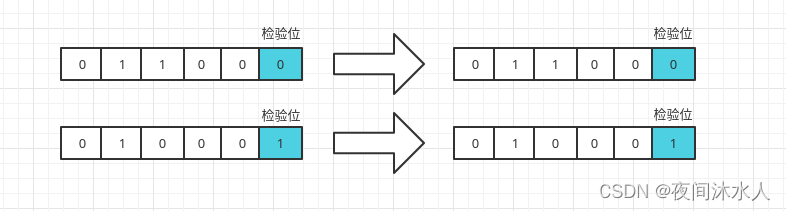
crc校验位:和奇偶位校验原理相同,但是要比奇偶位校验更加准确,具备更高的差错检测能力,是一种普遍的数据校验方式。

HDFS的保持数据完整性的方法:
- DN读取block的时候,计算数据的CheckSum。
- 如果计算出的CheckSum和存储数据的时候创建的CheckSum不一致,则数据无效。此时从其他的DN上读取block数据。
- 常见的数据校验方式:crc(32位),md5(128位)。
- DN会周期性的检验block数据块的CheckSum。
HDFS读写流程:
HDFS中读写流程涉及的数据单位:
- block:客户端上传文件时的最大的数据单位,默认为128M,可以通过参数修改,和磁盘的读写速率有关。block太大,会导致Map任务数少,导致任务执行速度慢,block太小,存放的位置就多,会增加寻址时间。
- packet:数据传输的第二个单位,实际上客户端的数据大小达到一个packet的时候才会发送数据包到DN,默认64KB。每一个packet由多个chunk填充。
- chunk:数据传输的最小的单位,作用是对数据进行校验,默认512Byte,附带4个字节的校验位,实际上写入packet的时候就是516Byte。pakcet和chunk占比位约为128:1(64 * 1024 / 512)。
HDFS写数据流程:
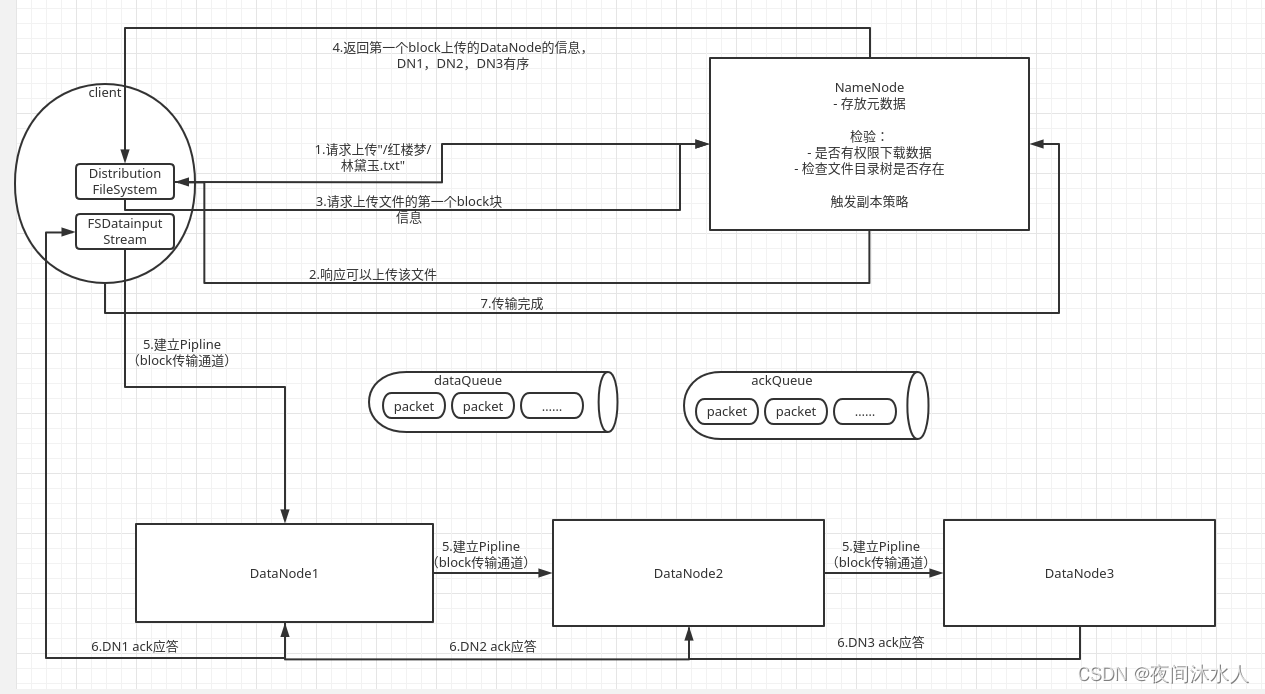
1、客户端通过Distributed FileSystem向NN发送上传文件请求,例如上传"/红楼梦/林黛玉.txt"。
2、NN接受到请求1后,检查文件是否可以上传并返回检查结果给客户端:
- 检查是否有权限上传文件。
- 检查文件目录树是否存在。
3、客户端得到NN可以上传该文件的响应后,继续向NN发送请求上传该文件的第一个block块的请求,并要求NN返回可使用的DN有序列表。
4、NN接受到请求3后,根据副本策略(副本数默认为3),计算出可以使用的DN1,DN2,DN3,并将可使用的DN有序列表返回给客户端。
- 副本策略:假设有两个机架,总共六台机器,每个机架上三台机器,r1(r1dn1,r1dn2,r1dn3),r2(r2dn1,r2dn2,r2dn3).
- 假如上传文件的请求就是在r1dn1发起的,那么第一个副本就保存在r1dn1。即第一个副本保存在客户端所在机架并且所在节点上(客户端直接在自己所在的节点上写数据,是最节省资源的)。
- 第二个副本保存在与第一个副本不同的机架的节点上(r1dn1向r2dn1中写数据是为了保证可靠性,如果r1挂了,那么r2dn1中还有一个副本)。
- 第三个副本保存在第二个副本所在机架的不同的节点上(r2dn1向r2dn2中的节点写数据是为了节约资源,r2dn1向r2dn2中写数据不需要出跨机架)。
- 更多节点、更多机架的情况下,节点随机选择。
5、客户端得到NN返回的可使用的DN有序列表后,创建DFSOutputStream,开始和可使用的DN有序列表中的第一个DN1建立Pipline,这里也会考虑负载均衡,然后再由DN1和DN2建立Pipline,再由DN2和DN3建立Pipline。
6、客户端与DN1建立Pipline后,开始向DN1发送packet,DN1接受到packet后,先写EditsLog,然后更新内存,再将packet通过Pipline发送到DN2,那么此时客户端就可以继续发送第二个packet到DN1,DN2接受到packet后,DN2做同样的操作,再发送到DN3,那么此时DN1就可以继续发送第二个packet到DN2。
7、当DN3,DN2,DN1处理完后,会逐级向上应答处理结果,最后由DN1向客户端反馈,之后客户端向NN反馈。
注意:其中,当客户端发送packet的时候,会将packet放在一个dataqueue中,由DataStreamer不断的拉取,并发送给DN1,并且同时会将该packet对象移动到ackququeue中等待所有的节点的应答结果,只要有一个节点应答成功,那么就将该packet从ackqueue中移除。如果其中有一个节点应答失败,那么会将ackququeue中的packet移动到dataqueue中,并提出故障节点,重新建立Pipline进行传输。 传输第二个block的时候,重复上述所有的步骤。
HDFS读数据流程:
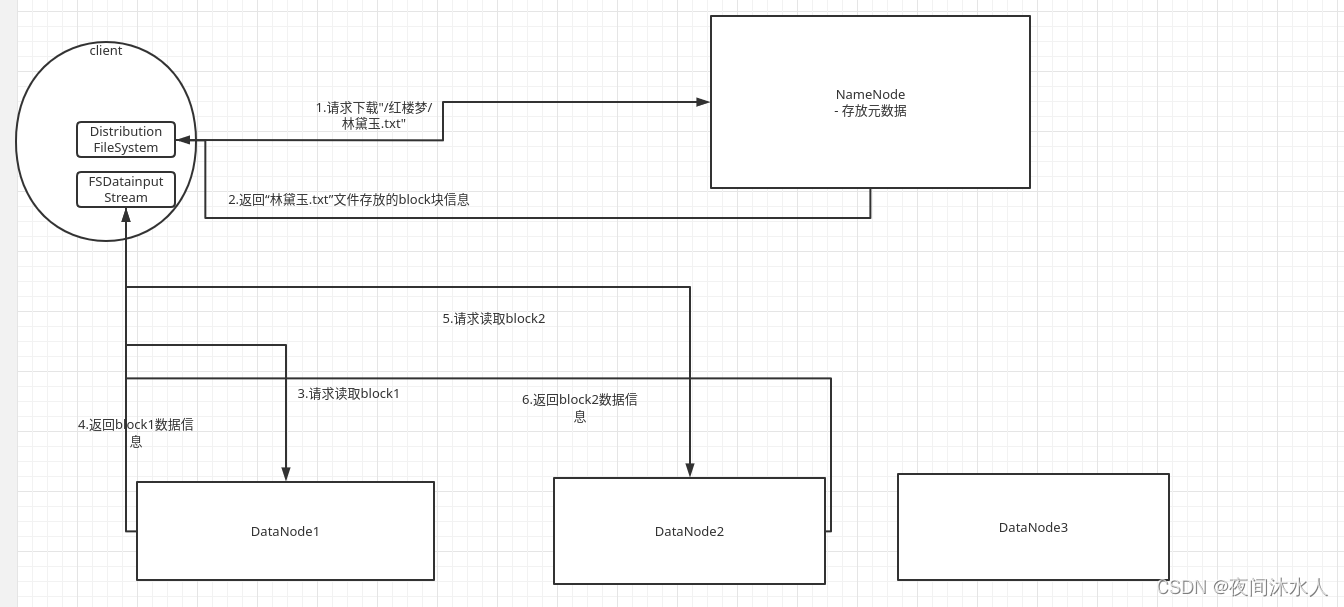
1、客户端通过Distributed FileSystem向NN发送下载文件请求,例如下载"/红楼梦/林黛玉.txt"。
2、 NN接受到请求1后,检查文件是否可以上传,并且通过查询元数据信息,找到该文件的元数据,包括所有的block块的信息所在的DN位置信息,并排序后返回。
- 检查是否有权限下载文件。
- 检查文件目录树是否存在。
3、客户端开始向DN(就近原则选择一个DN)发起下载文件的请求,DN从本地文件系统读取文件信息后,以packet为单位返回给客户端。
注意:因为NN返回的是元数据,那么客户端也可以做到读取指定位置的文件信息,也就说,客户端A可以读取block1的信息,客户端B可以读取block2的信息,最后将读取的所有的信息进行汇总,那么也能得到整个文件的信息,这里体现了一个分治的思想,也是支持分布式计算的核心。
常见报错:
1.hadoop集群启动后,jps发现所有的nodemanager都没有显示,查看nodemanager日志,发现如下报错,原因是yarn.nodemanager.aux-services的值在高版本的Hadoop中只能包含a-zA-Z0-9_,不能以数字开头,改为mapreduce_shuffle
2021-12-12 01:36:37,592 INFO org.apache.hadoop.service.AbstractService: Service NodeManager failed in state INITED
java.lang.IllegalArgumentException: The ServiceName: mapreduce.shuffle set in yarn.nodemanager.aux-services is invalid.The valid service name should only contain a-zA-Z0-9_ and can not start with numbers
at com.google.common.base.Preconditions.checkArgument(Preconditions.java:141)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxServices.serviceInit(AuxServices.java:146)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:108)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl.serviceInit(ContainerManagerImpl.java:323)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:108)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.serviceInit(NodeManager.java:519)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.initAndStartNodeManager(NodeManager.java:977)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.main(NodeManager.java:1057)
2.执行官方提供的wordcount时,出现以下错误提示,原因etc/hadoop/mapred-site.xml文件中需要配置hadopp的根目录。报错信息中出现三个属性增加到etc/hadoop/mapred-site.xml中即可。
[2021-12-12 01:53:05.088]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME= f u l l p a t h o f y o u r h a d o o p d i s t r i b u t i o n d i r e c t o r y < / v a l u e > < / p r o p e r t y > < p r o p e r t y > < n a m e > m a p r e d u c e . m a p . e n v < / n a m e > < v a l u e > H A D O O P M A P R E D H O M E = {full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME= fullpathofyourhadoopdistributiondirectory</value></property><property><name>mapreduce.map.env</name><value>HADOOPMAPREDHOME={full path of your hadoop distribution directory}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}
[2021-12-12 01:53:05.088]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
3.namende和datanode同时只能启动一个
原因是namenode挂机之后,直接格式化format后启动了namenode。因为namenode第一format之后会生成集群ID,再次格式化会生成新的集群ID,导致datanode中的集群ID和新启动的namenode中集群ID不一致。
解决方法:在所有的节点上删除datanode中所有的信息(默认在temp目录下,如果自行配置了,那么就在对应的目录下全部删除),然后在format namenode。
总结
本文着重讲解了HDFS的一些简单操作以及浅显的说明了下HDFS在存储数据时的一些工作原理。