HDFS:分布式文件系统
一句话总结
一个文件先被拆分为多个Block块(会有Block-ID:方便读取数据),以及每个Block是有几个副本的形式存储
1个文件会被拆分成多个Block
blocksize:128M(Hadoop2.0以后默认的块大小,可以自定义配置)
130M ==> 2个Block: 128M 和 2M
HDFS设计目标
- 巨大的分布式文件系统
- 满足大数据场景基本数据存储的要求
- 廉价的机器上
- 当你的存储空间不够,你可以水平横向扩展机器方式提高
HDFS架构
NameNode + N个DataNode
典型的主从架构,即:
1 Master(NameNode/NN) 带 N个Slaves(DataNode/DN)
建议:NN和DN是部署在不同的节点上
PS:
常见的主从架构还有:HDFS/YARN/HBase
主从架构一个难题就是:如何保证HA的问题,很多时候会使用Zookeeper来配置使用
NameNode/NN:主节点Master
1)负责客户端请求的响应
2)负责元数据(文件的名称、副本系数、Block存放的DN)的管理
DataNode/DN:从节点Slaves
1)存储用户的文件对应的数据块(Block)
2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
HDFS副本机制
-
replication factor:副本系数、副本因子
-
一个大的文件会被拆分为许多块,最终以多副本的方式存储在多个节点上
-
一个文件,除了最后一个,其余所有块的大小都是一致的
问题:那么如何为每个Block选择存储在哪些节点上呢?
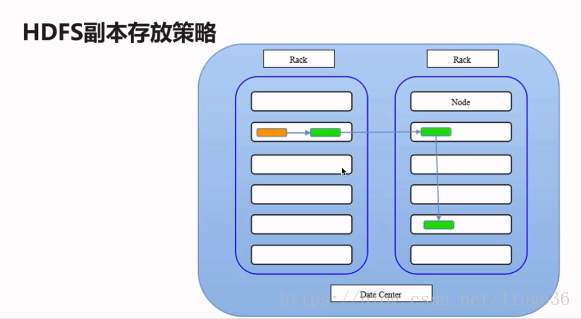
Rack代表的是机架:一般三份副本分别是这样存储的
第一份副本:存储在当前提交存储的机架中当前节点上
第二份副本:存储在非当前机架上的某一节点上
第三份副本:和第二副本统一机架的不同节点之上
建议:生产只能够,起码划分两个及其以上的机架
HDFS Shell
Usage: hdfs dfs [COMMAND [COMMAND_OPTIONS]]
hadoop fs -ls / 等价 hdfs dfs -ls /
[root@hadoop000 data]# ls
hadoop-tmp hello.txt
上传:
[root@hadoop000 data]# hadoop fs -put hello.txt /
下载:
[root@hadoop000 data]# hadoop fs -get /test/a/b/h.txt
查看内容:
[root@hadoop000 data]# hadoop fs -text /hello.txt
[root@hadoop000 data]# hadoop fs -cat /hello.txt
建立目录;
[root@hadoop000 data]# hadoop fs -mkdir /test
创建递归的目录
[root@hadoop000 data]# hadoop fs -mkdir -p /test/a/b
递归展示目录文件:
[root@hadoop000 data]# hadoop fs -ls -R /
本地拷贝到hdfs:
[root@hadoop000 data]# hadoop fs -copyFromLocal hello.txt /test/a/b/h.txt
删除文件:
[root@hadoop000 data]# hadoop fs -rm /hello.txt
递归删除文件夹:
[root@hadoop000 data]# hadoop fs -rm -R /test
HSFS的读写流程,工作原理(面试)
漫画图解
https://blog.csdn.net/eric_sunah/article/details/41546863
Client:客户端,通过HDFS Shell或Java API发起读写请求
1个NameNode:全局把控
N 个DataNode: 数据存储
写数据流程:
1.客户端把文件拆分为多个Block
2.NameNode:提供刚才拆分出来的Block块的具体datanode存储位置
3.DataNode:存储Block块的数据,把3个副本数据写完
读数据流程:
1.用户提供文件名就可以给客户端
2.客户端发起请求给NameNode
3.NameNode就会告诉客户端具体的存储位置和块
4.发起最近距离节点请求给DataNode下载数据
HDFS的优缺点
优点:
数据冗余,硬件容错
一次写入,多次读取数据
适合存储大文件
构建在廉价机器上
缺点:
延时性高
不适合小文件存储