Hadoop的概述:hadoop是一个开源的,可靠的,可扩展的系统框架,我们主要hadoop实现海量数据的分布式存储,以及分布式的计算,此外hadoop还可以利用自身框架的机制实现自动检测以及故障处理。
Hadoop的核心框架:hadoop的核心任务是大量数据的分布式存储以及数据的分布式计算,基于这两个核心业务,hadoop开发了相关的框架支持,HDFS和MapReduce,分别是分布式的文件系统框架和分布式的计算框架,这里需要注意的是,hadoop并不适合存储大量的小文件,这是由于namenode将元数据文件存储在了内存中,因此文件系统所能存储的文件总数取决于namenode的内存容量。
图一:HDFS的系统框架图
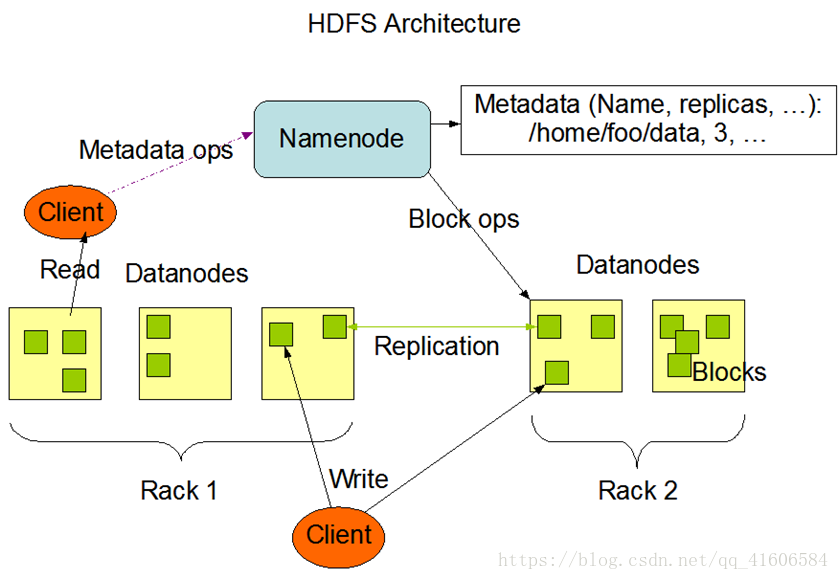
Namenode:管理元数据的节点;
Metadata:元数据,其中保存有各分块数据的信息,如分块大小,存储节点位置等,存储于namenode的内存中,此外还会存储在Fsimage文件和Edits文件中,每当HDFS启动时都会将Fsimage文件中的内容加载到内存中;
Blocks:文件块,HDFS是一个分布式的文件系统,存储在HDFS节点上的数据已经不再是一个完整的文件而是经过分块切分后数据块block,文件的上传切分会在后面讲;
Replication:HDFS中的副本,hadoop中引入了副本冗余机制,来确保datanode节点的数据不会丢失,而在hadoop中一般采用的三副本机制,这样固然提高了安全性,但是也降低了磁盘的利用率,三副本机制意味着副本利用率仅有三分之一,除了采用副本冗余还可以使用纠删码也可以达到提高数据安全性的功能,磁盘的利用率会大大提升,但是相对的对于CPU的消耗就会变大;
Rack:机架,可以看做是一个书架,只是上面放置的是服务器而已;
Datanode:数据节点,是用来实际存放数据的节点,文件在经过分块计算后就被存储在了Datanode节点中;
Client:客户端,凡是通过指令或代码操作的一端都是客户端,在HDFS的底层都是通过DFSClient这个类来操作的,通过RPC接口与namenode和datanode通信。
HDFS中文件下载流程
从图一中也能大概看出客户端在读取和上传文件的时候都是直接在datanode中操作的,下面就具体讲下HDFS中文件的下载和上传。
图二:HDFS中文件的下载流程图
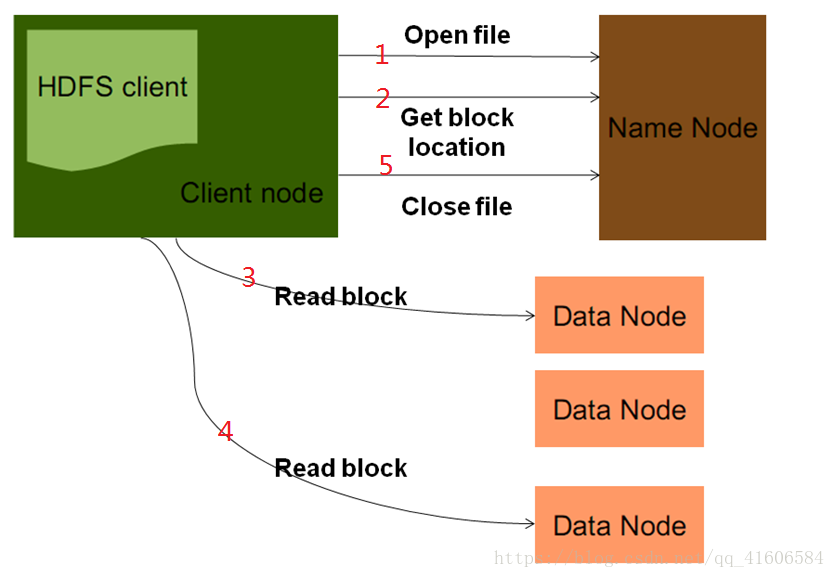
1.DFSClient通过namenode来获取指定文件的输入流,namenode会对这个请求做一系列的校验,例如路径是否合法,该用户是否拥有访问权限等,如果验证不通过,会直接报错并返回客户端;
2.DFSClient通过namenode获取文件分块后block的相关信息,如果在第一步的验证中通过了的话,namenode会直接将这些与请求文件相关的元数据信息封装到一个输入流当中并将输入流返回给客户端;
3、4.客户端通过这个输入流去到相应的Datanode中读取数据;
5.关闭相关资源。
以下是文件下载的代码实现:
public void TestGetFile() throws Exception{
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.195.130:9000"), conf);
FSDataInputStream in = fs.open(new Path("/park02/world.txt"));
OutputStream out = new FileOutputStream(new File("world.txt"));
IOUtils.copyBytes(in, out, conf);
}
HDFS中文件上传流程
图三:HDFS中的文件上传
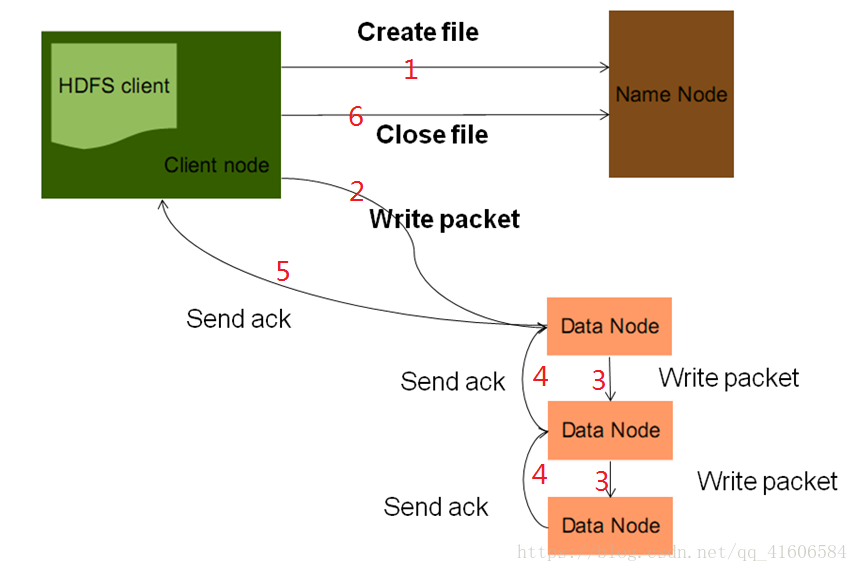
1.DFSClient会通过namenode获取到一个文件输出流,namenode会对这个请求进行校验,如果校验不通过会直接报错并返回客户端,校验通过后namenode会根据文件的信息其进行切块的分配,例如哪一块文件将要存储在哪一个文件节点上,这些信息会被封装到一个文件的输出流中,然后返回给客户端;
2、3、4、5.DFSClient获取到输出流后会将需要上传的数据打散,变成一个个的packet进行发送,每个packet只有64kb,根据输出流中封装的文件切块分配信息将这些packet发送到指定的Datanode中,Datanode会将数据发送到数据链中的其他Datanode节点上,此外,每一个datanode在收到数据后会给上一级反馈ack确认机制,直到最上一级的Datanode给客户端返回了ack后才会再发送下一个packet;
注:1.namenode不对原数据进行切分,只是做相关的运算,具体的切分是在客户端执行的;
2.在3过程中有用到一个数据流管道(pipeline),目的是为了充分利用每一台服务器的带宽,最小化数据的传输延迟;
以下是文件上传的代码实现:
public void TestPutFile() throws Exception{
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.195.130:9000"), conf);
FSDataOutputStream out = fs.create(new Path("/folw/folw.txt"));
FileInputStream in = new FileInputStream(new File("flow.txt"));
IOUtils.copyBytes(in, out, conf);
}
HDFS文件系统中删除文件的流程
1.DFSClient向namenode发送删除文件的请求,namenode会进行相关的验证,验证不通过会报错并返回客户端;
2.如果验证通过,namenode会对删除的路径做删除标记,但是此时文件并没有真正的删除,客户端已经无法再访问到该文件了;
3.datanode会定期向namenode发送心跳包(这是基于hadoop的心跳机制),这时datanode会收到namenode的删除命令,此时文件真正的被删除了;
HDFS的相关体系结构
一、DFSClient的结构体系
|-------Lease HDFS不支持不支持文件的修改(但是允许数据的追加),并且不允许并行写,为解决可能出现的多个用户同时进行文件的写操作问题,引入锁机制,Lease是一种带有“租约”期限的互斥锁,当一个用户拿到了租约锁后,在租约期间都是有着文件的写权限的。 DFSClient |-------ClientProtocol 客户端与HDFS通信的RPC协议的接口,这是客户端能够与HDFS通信的基础。 |-------DFSInputStream 是DFSClient用来读取datanode上文件的输入流。 |-------LocatedBlocks 封装了文件块的信息。 |-------BlockReader 该类的read()方法读取datanode上的数据。 |-------DFSInputStream |-------DFSOutputStream DFSClient向HDFS写数据时,namenode会返回一个文件的输出流,文件会根据输出流切分为64kb的packet并将其存放在dataqueue队列中。 |--------Packet |--------pipeline |--------DataStreamer 从dataqueue中一个一个的取出packet进行数据的传输,然后形成一个数据流管道pipeline,然后将数据流管道输出给管道里的第一个datanode,第一个再将其交个第二个节点,直到最后一个完成保存并ack确认DFSClient再发送下一个packet。 |--------ResponseProcessor
DFSClien
DFSClient这个类是用来实现客户端连接HDFS文件系统的,并在HDFS上做基本的文件操作的,通过RPC机制与namenode和datanode通信,并在datanode上对block进行读写操作。下列方法是该类通过namenode取得文件元信息的重要方法。
static LocatedBlocks callGetBlockLocations(ClientProtocol namenode, String src, long start, long length) throws IOException { try { return namenode.getBlockLocations(src, start, length); } catch(RemoteException re) { throw re.unwrapRemoteException(AccessControlException.class, FileNotFoundException.class, UnresolvedPathException.class); } }
DFSOutputStream中有两个队列和两个线程:
dataQueue是数据队列,用于保存等待发送给datanode的数据包;
ackQueue是确认队列,保存还没有被datanode确认接收的数据包;
streamer线程,不停的从dataQueue中取出数据包,发送给datanode;
response线程,用于接收从datanode返回的反馈信息;
在向DFSOutputStream中,写入数据(通常是byte数组)的时候,实际的传输过程是:
1、文件数据以字节数组进行传输,每个byte[]被封装成64KB的Packet,然后扔进dataQueue中
2、DataStreamer线程不断的从dataQueue中取出Packet,通过socket发送给datanode(向blockStream写数据)
发送前,将当前的Packet从dataQueue中移除,并addLast进ackQueue
3、ResponseProcessor线程从blockReplyStream中读出从datanode的反馈信息,反馈信息很简单,就是一个seqno,再加上每个datanode返回的标志(成功标志为 DataTransferProtocol.OP_STATUS_SUCCESS)
通过判断seqno(序列号,每个Packet有一个序列号),判断datanode是否接收到正确的包。
只有收到反馈包中的seqno与ackQueue.getFirst()的包seqno相同时,说明正确。否则可能出现了丢包的情况。
4 、如果一切 OK ,则从 ackQueue 中移出: ackQueue.removeFirst(); 说明这个 Packet 被 datanode 成功接收了。二、Namenode结构体系
Namenode HDFS文件系统的管理者类,管理文件的元数据信息。 |-------FSNameSystem 是HDFS文件系统实际执行的核心,提供各种对文件的管理和操作 |-------DFSConfigKeys |-------FSDirectory 存储整个文件系统的目录状态,保存了文件路径和数据块的映射关系。 |-------FsImage 把文件和目录的元数据信息持久化地存储到fsimage文件中,每次启动时从中将元数据加载到内存中构建目录结构树,之后的操作记录在edits中,定期将fsimage和edits合并并将数据刷到fsimage中。 |-------LeaseManager |-------HeartbeatManager 管理各个datanode传来的心跳。 |-------HeartbeatThread |------Monitor 周期性检测各个datanode的心跳,当检测到超时心跳时,判断节点上是否有数据需要复制,然后对这个节点进行死亡标记,如果这个节点上有数据需要复制就进行备份(满足三副本机制),复制完后删除该死亡节点。 Namenode 实际管理的是两张表:
1.文件——文件块信息
2.文件块信息——存储这个文件块的机器列表信息
第一张表信息存储在namenode节点的磁盘上,并且访问是非常高效的(因为namenode在启动之后,会将数据加载到
内存里供快速访问);
第二张表信息,在每次namenode重启工作后,会重新建立。(这么做目的是为了确保块信息存储的准备性,实现
机制时,当namenode重启工作后,每个datanode节点通过rpc心跳向namenode汇报自身存储的文件块信息,然后
namenode根据这些信息,重建第二张表信息,在此过程中,HDFS是处于安全模式的,即只能对外提供读服务。当第二
表信息重建完后,确认文件块数量正确且都完整,则退出安全模式);
三、Datanode结构体系
Datanode |-------BlockSender 用于发送datanode数据的类 |-------DataXceiverServer 用于开启线程接收客户端的数据 |-------- BlockReceiver 接受数据并写入磁盘,同时将数据传输给管道中的下一个节点 |-------DatanodeProtocol datanode和namenode之间RPC通信协议的接口,datanode通过RPC协议向namenode 汇报节点信息,发送心跳包。 |-------InterDatanodeProtocol |-------ClientDatanodeProtocolBlockSender会使用到的场景:1.datanode向客户端发送数据;2.当namenode发现某一个block的副本数量不足,会要求存储有该block的datanode向其他节点复制该block;3.当HDFS开启了负载均衡,有可能会发生数据的迁移;4.datanode会定期使用BlockSender检查block的数据是否有损坏。
Hadoop为了解决单点故障问题所提出的方案
可以看出namenode节点在hadoop中的重要性,与此同时一个重要的问题产生了,那就是namenode的单点故障问题,一旦namenode发生故障,整个HDFS就不能使用了,这是我们不想看到了,于是下面给出了hadoop两个版本对于该问题的解决方案。
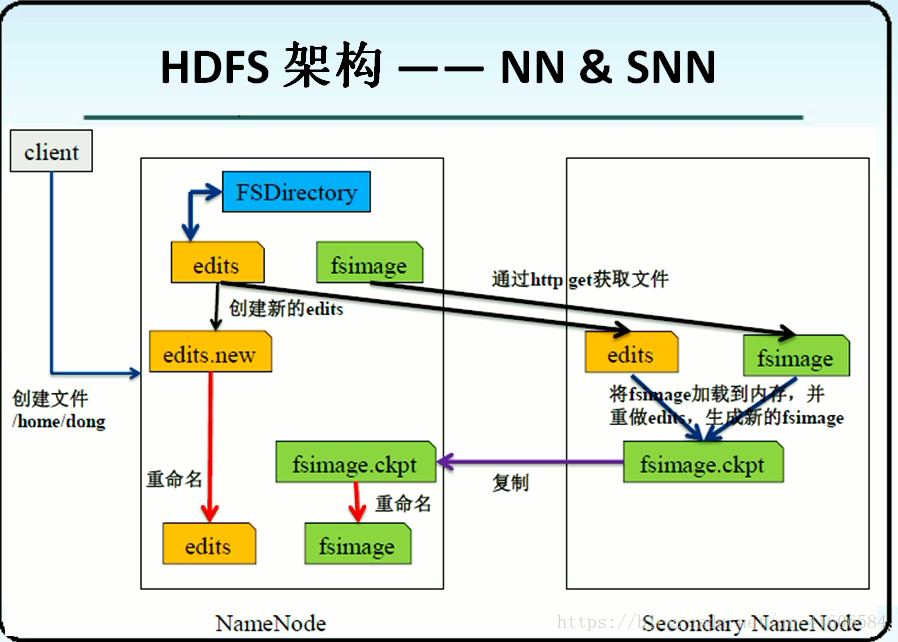
这是在hadoop1中针对单点故障问题的解决方案,有两个namenode,在SNN中进行两张表的合成,并将其刷到namenode中,但是这么做并不能实现数据的实时共享,还是可能导致数据的丢失,因此在hadoop2中提出了下面的解决方法
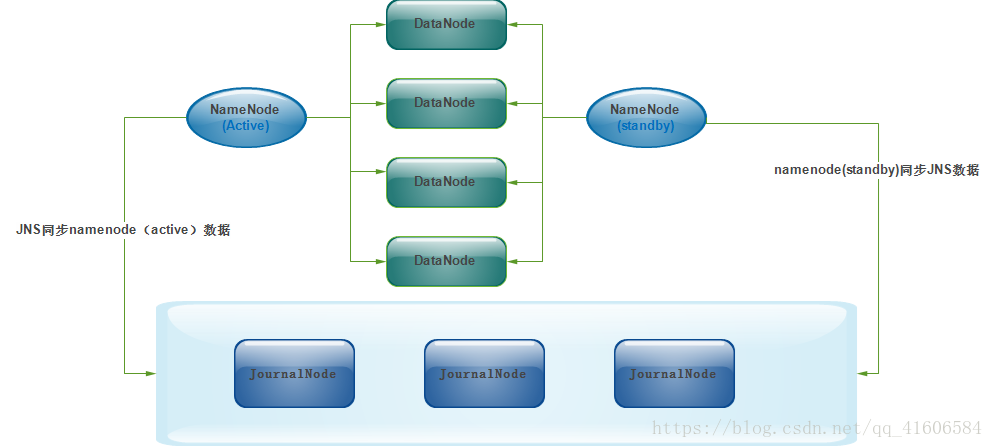
在Hadoop2中有两个namenode,每一个都具有相同的职能,并不是1中的secondarynamenode,一个处于active状态,一个处于standby待命状态,但是该状态的namenode时刻同步active,这里就是利用了JournalNode实现了同步,处于安全性的考虑,这里是搭建了journalNode集群。
