在很久很久以前曾经下载分析过国航内网的航班数据,算是第一次爬虫吧,然而那个时候,仅仅局限于一层而已,说是叫爬虫,有点儿牵强。最近写基于MPV的播放器,要下载字幕,就开始看看这方面的东西。一看吓一跳,自己落伍太多了。废话不说,直接上干货。此文完全献给小白,大咖请闪。
本文以流水账的方式一步一步展开,小白可以跟着看。
本文重点:如何构造http访问,获取防盗链技术后面的链接。
目标网站:字幕库,http://www.zimuku.la/
开发语言:C#
需要具备的知识储备:
HTTP基本协议的了解,知道URL,Get,Post 方法以及简单调用
HTTP 解析工具的了解,本代码用到:
本文后面会给出参考网站。
Chrome 调试方法(自己百度 网络抓包)
剩下就是具体工具的使用了。
仔细分析字幕库的下载过程,大约是以下几步:
第一步:测试举例

可以看出,查询方法很好模拟,直接构造URL即可。
测试过程只取第一个字幕,因此需要看看源代码
关键源代码如下:

点击第一行,跳转如下页面

请注意,上图中的URL和源代码中的href是有对应关系的,这是构造url的基本要素。点击下载字幕,进入如下界面:

此时点击第一个按钮,字幕就下载下来了。那么观看源文件,是否可以得到链接呢?
看看源文件:
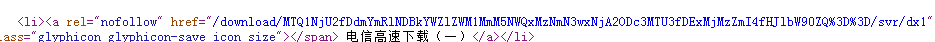
点击上述网页内的链接,奇怪的事情发生了,界面是这样儿的:

因此,网页肯定是进行了防盗处理,你拿到这个链接好像并没用。因此,简单的按照地址爬的方法,到这里就歇菜了。笔者,痛苦思考,知道自己肯定是错过了什么,当然注意是指知识上的沟沟。在百度搜 防盗技术,经过过滤,知道:要模拟http请求才可以即模拟浏览器的调用方式才行。继续百度http请求模拟,知道需要构造如下Http的请求Header 才可以。如何构造httpheader? header的属性值如何获得?请百度,Chrome 调试抓包方法。Chrome 抓包后,这些值都可以获得。
第二步,构造HTTPheader
下面直接给出代码,
httpwebRequest.Referer = url_referer;// @"http://zmk.pw/dld/145499.html";//http://zmk.pw/dld/145499.html
httpwebRequest.Method = Mehtod;
httpwebRequest.ContentType = "text/html";
httpwebRequest.Accept = @"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9";
httpwebRequest.Headers["Accept-Encoding"] = "gzip, deflate";
httpwebRequest.Headers["Accept-Language"] = "zh-CN,zh;q=0.9";
httpwebRequest.UserAgent = "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36";
httpwebRequest.Host = "zmk.pw";
httpwebRequest.Headers["Upgrade-Insecure-Requests"] = "1";
httpwebRequest.KeepAlive = true;
String cookie = "__cfduid = d843ffdcc4b5ccd31db5801cb7cb86d1d1606619179; __gads = ID = eb409c7182aed71c - 22064ba0f3c400b5: T = 1606619196:RT = 1606619196:S = ALNI_Mb7XrQevUe_Ub3ra - 5_LyzWqi98SA; PHPSESSID = q7eqk2525nhbceevfugbsscfm4";
httpwebRequest.Headers.Add("Cookie", cookie);//赋值cookeis
Encoding encoding = Encoding.GetEncoding("utf-8");
这些属性名称和值在Chrome的调试里都可以看到,截图如下:

照着上面的值抄下来,你的httpheader就构造好了。
此时再调用,response 就会返回字幕文件,调用成功了。
第三步 核心代码实现
核心代码如下,包括一步一步构造URL的过程,资源文件和界面代码略。
using Ivony.Html;
using Ivony.Html.Parser;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Xml.XPath;
using System.Xml;
using System.Net;
using System.IO;
using HtmlAgilityPack;
/// <summary>
/// Function:Download subtitle files from web
/// The first web is http://www.zimuku.la/
/// Refer to http://www.360doc.com/content/20/0817/17/71178898_930801275.shtml
/// </summary>
namespace ILearnPlayer
{
class SubtitleDownLoader
{
// 获取对应网页的 HTML Dom TREE
public static IHtmlDocument GetHtmlDocument(string url)
{
IHtmlDocument document;
try
{
document = new JumonyParser().LoadDocument(url);
}
catch
{
document = null;
}
return document;
}
public static string EntryPoint;
//<a href="/detail/145499.html" target="_blank" title="战士 第2季第09集【YYeTs字幕组 简繁英双语字幕】Warrior.2019.S02E09.Enter.the.Dragon.720p/1080p.REPACK.AMZN.WEB-DL.DDP5.1.H.264-NTb"><b>战士 第2季第09集【YYeTs字幕组 简繁英双语字幕】Warrior.2019.S02E09.Enter.the.Dragon.720p/1080p.REPACK.AMZN.WEB-DL.DDP5.1.H.264-NTb</b></a>
public static List<SubtitleFileItem> GetSunbtitle(int page)
{
List<SubtitleFileItem> result = new List<SubtitleFileItem>();
string url = EntryPoint;
IHtmlDocument document = GetHtmlDocument(url);
if (document == null)
return result;
//var aLinks = document.Find("a");//获取所有的meta标签
//foreach (var aLink in aLinks)
//{
// if (aLink.Attribute("name").Value() == "keywords")
// {
// var name = aLink.Attribute("content").Value();//无疆,无疆最新章节,无疆全文阅读
// }
//}
List<IHtmlElement> listsTable = document.Find("table").ToList();
List<IHtmlElement> listsSub = listsTable[0].Find("a").ToList();// find <a href...
//<a href="/detail/130526.html" target="_blank" title="肖申克的救赎 The Shawshank Redemption(1994) 特效中英文字幕 上蓝下白.ass"><b>肖申克的救赎 The Shawshank Redemption(1994) 特效中英文字幕 上蓝下白.ass</b></a>
for (int i = 0; i < listsSub.Count; i++)
{
SubtitleFileItem item = new SubtitleFileItem();
IHtmlElement subItem = listsSub[i];
item.url = subItem.Attribute("href").AttributeValue;
if (item.url.IndexOf("/subs/") >= 0)
{
break;// the last line is:<a target="_blank" href="/subs/24068.html"><span class="label label-danger">还有18个字幕,点击查看</span></a>
}
item.title = subItem.Attribute("title").AttributeValue;
//item.lang = subItem.Attribute("href").AttributeValue;
//item.url = subItem.Attribute("href").AttributeValue;
//item.url = subItem.Attribute("href").AttributeValue;
//item.url = subItem.Attribute("href").AttributeValue;
result.Add(item);
}
return result;
}
/// <summary>
/// The codes steps from the following Python codes.
/// </summary>
//# 获取搜索结果的第一个字幕详情页链接
// etreeRes = etree.HTML(res)
//resTd = etreeRes.xpath('//td/a/@href')[0]
//subDownUrl = 'http://zmk.pw/dld' + resTd.split('detail')[-1]
//# print('成功搜索到字幕 %s ' % videoName)
//resDown = requests.get(subDownUrl).text
//DownUrl = 'http://zmk.pw' + \
// re.findall(r'rel="nofollow" href="(.*?)" class=', resDown)[0]
public String getTheFirstSubtitl(String url)
{
String subContent="";
//Use HtmlAtilityPack to parser the href and else.
// From Web
var web = new HtmlWeb();
var doc = web.Load(url);
//XPath
String xPath = "//td/a[@href]";
var nodes = doc.DocumentNode.SelectSingleNode(xPath).GetAttributes("href");
String resTd="";
foreach (var nd in nodes)
{
resTd = nd.Value;//find the first url of the subtitle files
}
var subDownUrl = "http://zmk.pw/dld" + resTd.Split(new[] {
"detail" }, StringSplitOptions.None)[1];
doc = web.Load(subDownUrl); ;// requests.get(subDownUrl).text
xPath = "//li/a[@rel]";
nodes = doc.DocumentNode.SelectSingleNode(xPath).GetAttributes("href");
foreach (var nd in nodes)
{
resTd = nd.Value;//find the first url of the subtitle files
}
// <li><a rel="nofollow" href="/download/MTQ1NjU2fDdmYmRlNDBkYWZlZWM1MmM5NWQxMzNmN3wxNjA2ODMzMzE5fDRjYTA5MWVhfHJlbW90ZQ%3D%3D/svr/dx1" class="btn btn-danger btn-sm"><span class="glyphicon glyphicon-save icon_size"></span> 电信高速下载(一)</a></li>
var downUrl = "http://zmk.pw" + resTd;
subContent= zimukuHttpReq(downUrl, subDownUrl, "");
return subContent;
}
public static string zimukuHttpReq(string url, string url_referer, string data, string Mehtod = "GET", bool xml = false, string head = "")
{
//encodeURI
HttpWebRequest httpwebRequest = null;
HttpWebResponse httpwebResponse = null;
StreamReader streamReader = null;
string responsecontent = "";
String DownUrl = url;//
try
{
httpwebRequest = (HttpWebRequest)WebRequest.Create(DownUrl);
httpwebRequest.Referer = url_referer;// @"http://zmk.pw/dld/145499.html";//http://zmk.pw/dld/145499.html
httpwebRequest.Method = Mehtod;
httpwebRequest.ContentType = "text/html";
httpwebRequest.Accept = @"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9";
httpwebRequest.Headers["Accept-Encoding"] = "gzip, deflate";
httpwebRequest.Headers["Accept-Language"] = "zh-CN,zh;q=0.9";
httpwebRequest.UserAgent = "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36";
httpwebRequest.Host = "zmk.pw";
httpwebRequest.Headers["Upgrade-Insecure-Requests"] = "1";
httpwebRequest.KeepAlive = true;
String cookie = "__cfduid = d843ffdcc4b5ccd31db5801cb7cb86d1d1606619179; __gads = ID = eb409c7182aed71c - 22064ba0f3c400b5: T = 1606619196:RT = 1606619196:S = ALNI_Mb7XrQevUe_Ub3ra - 5_LyzWqi98SA; PHPSESSID = q7eqk2525nhbceevfugbsscfm4";
httpwebRequest.Headers.Add("Cookie", cookie);//赋值cookeis
Encoding encoding = Encoding.GetEncoding("utf-8");
httpwebResponse = (HttpWebResponse)httpwebRequest.GetResponse();
if (httpwebResponse.CharacterSet.ToUpper().Equals("UTF-8"))
{
encoding = Encoding.Unicode;
}
streamReader = new StreamReader(httpwebResponse.GetResponseStream());
responsecontent = streamReader.ReadToEnd();
}
catch (Exception ex)
{
return ex.Message;
}
finally
{
if (httpwebResponse != null)
{
httpwebResponse.Close();
}
if (streamReader != null)
{
streamReader.Close();
}
if (httpwebRequest != null)
{
httpwebRequest.Abort();
}
httpwebRequest = null;
httpwebResponse = null;
streamReader = null;
}
return responsecontent;
}
}
// used for the subtitle file (item)
public class SubtitleFileItem
{
/// <summary>
/// title
/// </summary>
public String title {
set; get; }
/// <summary>
/// Language
/// </summary>
public String lang {
set; get; }
/// <summary>
/// ranking
/// </summary>
public int rank {
set; get; }
/// <summary>
/// download times
/// </summary>
public int dldTimes {
set; get; }
/// <summary>
/// Updloader
/// </summary>
public String uploader {
set; get; }
/// <summary>
/// upload time
/// </summary>
public String upldTime {
set; get; }
/// <summary>
/// URL
/// </summary>
public String url {
set; get; }
}
}
调用代码:
String url;
url = "http://www.zimuku.la/search?q=" + txtMovie.Text;
SubtitleDownLoader sbtDld = new SubtitleDownLoader();
txtContent.Text = sbtDld.getTheFirstSubtitl(url);
调用截图如下:

至此,第一个爬虫测试告一段落,下一步的任务就是过滤和整理。此文的目的,备忘和分享。
后记
感谢网络以及网友,本人参考的网站及网友文章如下:
主要参考了这篇文章,对笔者启发很大。
Python 源码:
https://blog.csdn.net/xun527/article/details/110229840
c#必须使用适当的属性或方法修改此标头解决办法
https://blog.csdn.net/u011127019/article/details/52571317
C# 使用XPath解析网页
https://blog.csdn.net/weixin_34121282/article/details/86263589
XPath 语法
https://www.w3school.com.cn/xpath/xpath_syntax.asp
https://www.runoob.com/xpath/xpath-syntax.html
马拉孙 2020-12-02 于泛五道口地区