人脸识别中的开集和闭集测试
这个领域里可以简单分成两大类:
• 人脸验证
• 人脸检索
做人脸识别的时候,需要根据业务需要来选择合适的测试指标,测试指标也远远不止文中提到的几个,这里就列举几个比较常用的。
1. 人脸验证:
给定两张人脸图片,判断两张图片是否为同一人。
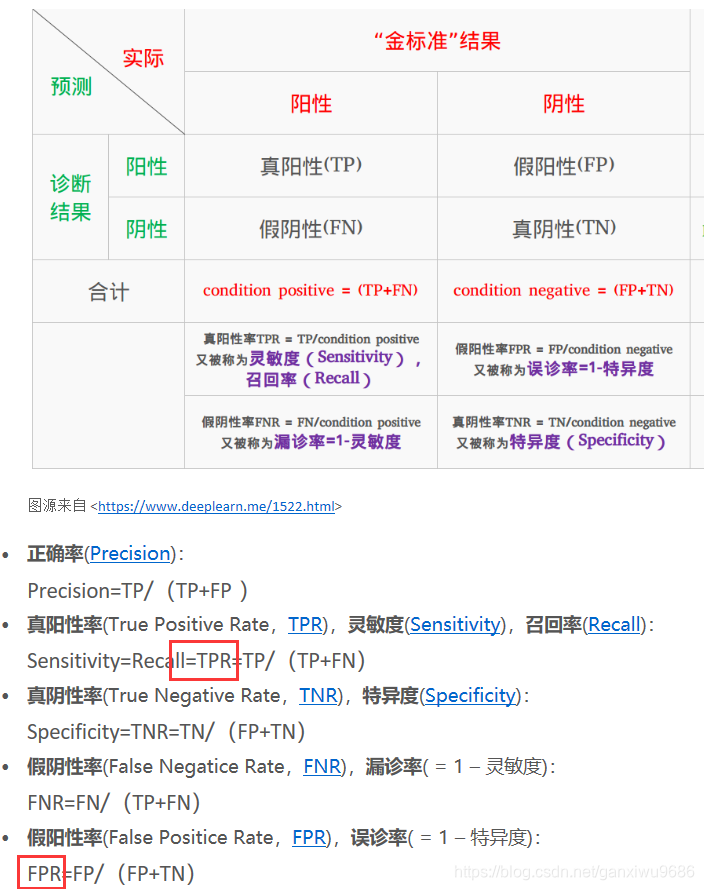
两个基本术语:误识率–人脸比对通过了但其实并不是本人的概率,通过率–将同一人正确识别出来的概率。
其实都是根据实际业务定义的,人脸验证场景中,比如需要刷身份证的人脸闸机,一般希望误识率越低越好,因为不希望有人冒充混入,同时希望通过率越高越好,不然明明是本人却老是验证失败。一般会给定误识率,然后确定一个threshold,再计算出通过率。
将这两个术语对应到ROC上:误识率-False Positive Rate,通过率:True Positive Rate。接下来就可以利用ROC来评价人脸验证模型的性能了。具体计算方式如下图:
2. 人脸检索:
人脸检索可以分为两大类,开集(Open Set)和闭集(Close Set)检索。
给定集合probe和gallery,其中probe和gallery的元素均为一张人脸图片,一般情况下probe元素数小于gallery元素数。
a. 闭集测试:
probe集合所有的图片对应的所有人,肯定包含在gallery集合的人中。
一般用top k准确率来评估模型的闭集测试性能。以k=1为例,先计算probe和gallery中所有元素之间的两两相似度,若probe中某人的元素与gallery中对应人的元素相似度最高,则视为该probe元素检索成功。此时tok 1准确率=probe检索成功数/probe总数。同理,以k=5为例,若probe中某人的元素与gallery中对应人的元素相似度在前五位,则视为该probe元素检索成功,此时称作top 5准确率。以此类推。
CMC就是以k为x轴,准确率为y轴的折现图。
b. 开集测试:
相对于闭集测试, 开集测试会增加一个集合impostor ,该集合的人既不包含于probe,也不包含于gallery。
开集测试有个虚警率的概念,即将impostor里的人错误的匹配上了gallery里的人。这也是根据实际业务确定的,例如一个人脸检索系统,gallery是在逃嫌犯库,这时来了一张不是嫌犯的照片,却匹配到了gallery集合里的一张照片,就称作误报警了,因此我们希望虚警率越低越好。
如何计算虚警率?其实就是False Positive Rate,具体计算方式是先计算impostor和gallery的两两相似度,对于每一个impostor的元素,取对应gallery中相似度最高的,即取最大的打分score,然后就可以根据sklearn.metrics.roc_curve(label,scores)方法,输入标签(全阴性)和score,按照threshold可以计算每一个TPR和FPR。可见博客。
接下来的top k准确率的计算方式也跟闭集测试差不多,主要增加了threshold作为过滤条件。以k=5为例,除了满足probe中某人的元素与gallery中对应人的元素相似度在前五位, 该人的相似度还应大于threshold才算检索成功。