《Select, Answer and Explain: Interpretable Multi-hop Reading Comprehension over Multiple Documents》
这篇文章是发表在2020年AAAI上的,京东实验室。在hotpotQA数据集取得了较好的效果。是一个pipeline的结构,先检索然后再结合GNN进行推理。
与上一篇2019ACL的论文CogQA 《Cognitive Graph for Multi-Hop Reading Comprehension at Scale》不同。传送门
分以下四部分介绍:
- Motivation
- Model
- Experiment
- Discussion
1、Motivation
- Most existing research in machine RC/QA focuses on answering a question given a single document. Although the performance on these types of tasks have been improved a lot over the last few years, the models used in these tasks still lack the ability to do reasoning across multiple documents. 缺乏跨文档的推理
- little attention has been paid to the explainability of the answer prediction
- regardless of the fact that most context is not related to the question or not helpful in finding the answer.
- current applications of GNN for QA tasks usually take entities as graph nodes and reasoning is achieved by conducting message passing over nodes with contextual information. 需要预定义一些target entity,而且有可能会抽取一些噪音实体
2、Model
- first filters out answer-unrelated documents
and thus reduce the amount of distraction information(训练一个文档分类器,document classifier trained with a novel pairwise learning-to-rank loss) - The selected gold documents are then input to a model to jointly predict the answer to the question and supporting sentences. (以多任务学习的方式对answer预测和sup预测)
- 同时把句子当作图中的节点,句子的表示获取:summarized over token representations based on a novel mixed attentive pooling mechanism.
2.1 overview
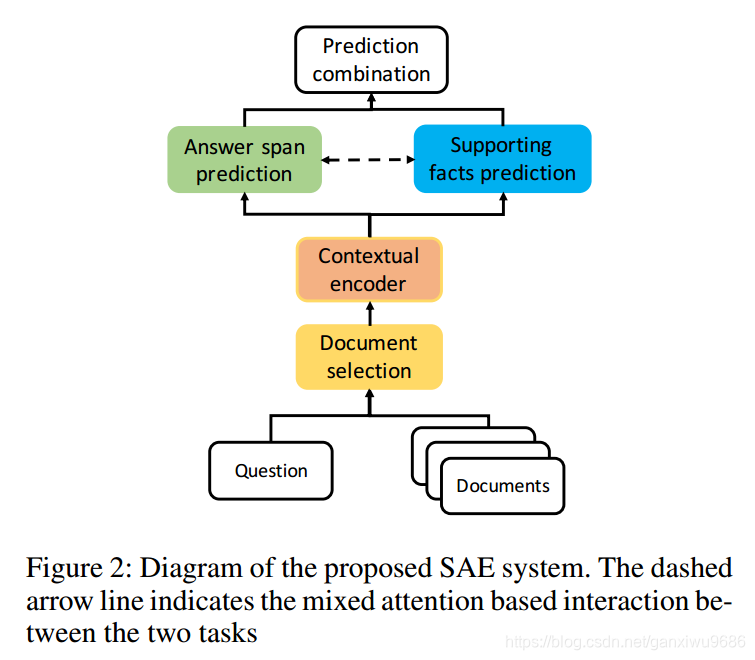
2.2 Select gold documents
对于每一篇文档都会把它处理成bert形式的输入。然后会取它的cls向量,经过一个multi head self attention层。目的是为了使得文档之间会有一个内部的交互,这个对于跨文档的推理来说是比较关键的。接下来会把这些文档的表示经过一个双线性层去计算novel learning to rank loss。
文档之间两两会进行比较,将取得的概率和标签进行二元交叉熵损失。
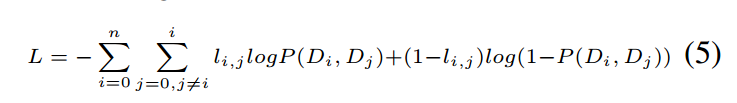
标签确定:
首先会定一个打分S,如果文档是gold的文档,为1,否则为0。接下来会对每一对输入的文档打标签:
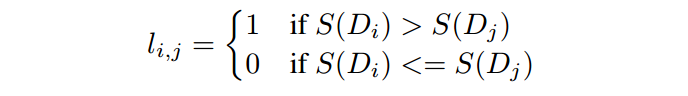
这个标签的含义就是指我希望能够找到关键的文档和其他文档的区别;我们会做一个特殊的处理对于包含答案片段的文档我们会让他的S=2。
训练好模型之后,在预测的时候,我们会对每一篇文章求一个相关性。然后排序,最后选出Topk。

2.2.2 Answer and Explain
在后续阶段,我们会对选出来的开篇文档进行串联。然后再经过一个bert,得到H。对于答案预测,我们会选择一个两层的多层感知机,输出开始位置和结束位置的,概率分布。
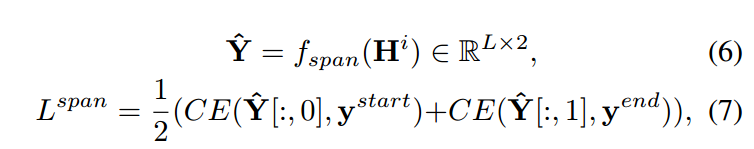
在支撑事实预测阶段,首先要得到的是句向量。
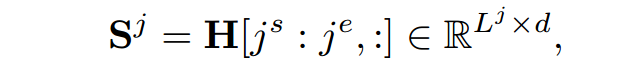
s和e表示句子的开始位置和结束位置。j表示第j个句子,L表示的是句子的长度。
文章在这里提出了一种混合的attention机制。在计算距向量的权重的时候,我们不仅仅考虑句子本身的信息,同时也会考虑在答案预测阶段的两个概率分布。
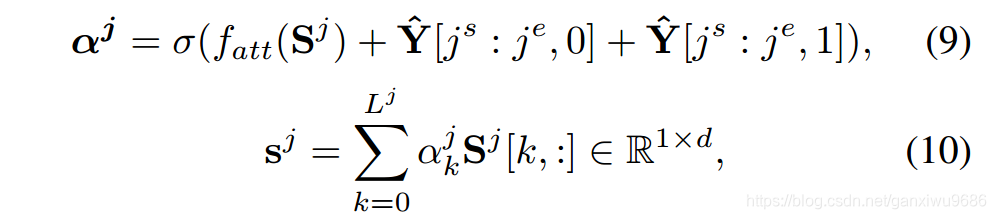
原因是答案里面的信息它一定是支撑的事实,但是支撑的事实不一定包含答案。因此在计算句子当中每个词的权重的时候,我们会把预测阶段的答案的概率分布加入,实现一种混合的attention。而不是仅仅考虑句子本身的attention。
得到了句子的表示之后,我们会把这些句子的表示作为图神经网络当中节点的初始化,然后使用一个基于消息传递策略的多关系图卷及神经网络。
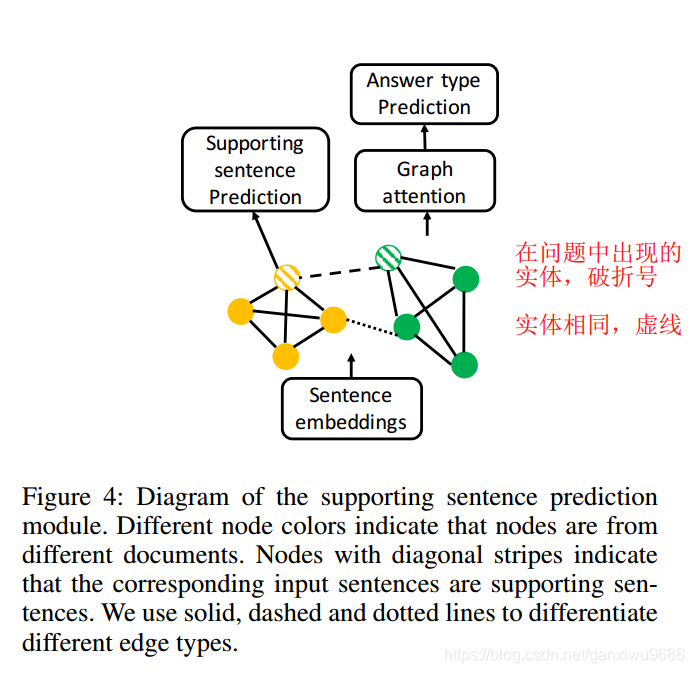
总共有三类,第1类边是句子,本身之间是一个全联接。第2类是对问题当中出现的实体连接,他们不需要完全一致。第3类是不同的文档之间包含相同的实体,那么把这个实体进行连接。后两类主要是为了能够捕获到跨文档之间的路径信息。确保文档和文档之间能够通过这两类的边进行信息传递。
更新公式如下:
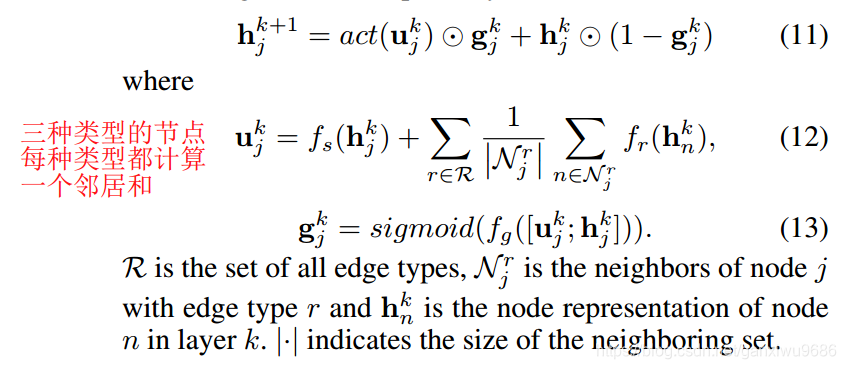
接下来会对每一个节点去进行一个二分类,计算这个节点属于支撑事实的概率y_sp。因为数据集当中的问题还包括是否,所以会继续在这个图当中去对答案的类型进行预测。分类器是一个三分类,分别是yes,no和span。主要的思想就是对图中的所有节点去进行加权,而这个权重就是来自于y_sp。得到整个图的信息之后,去过一个全连接神经网络,得到答案类型的概率y_ans。
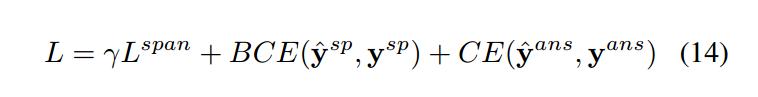
3、Experiment
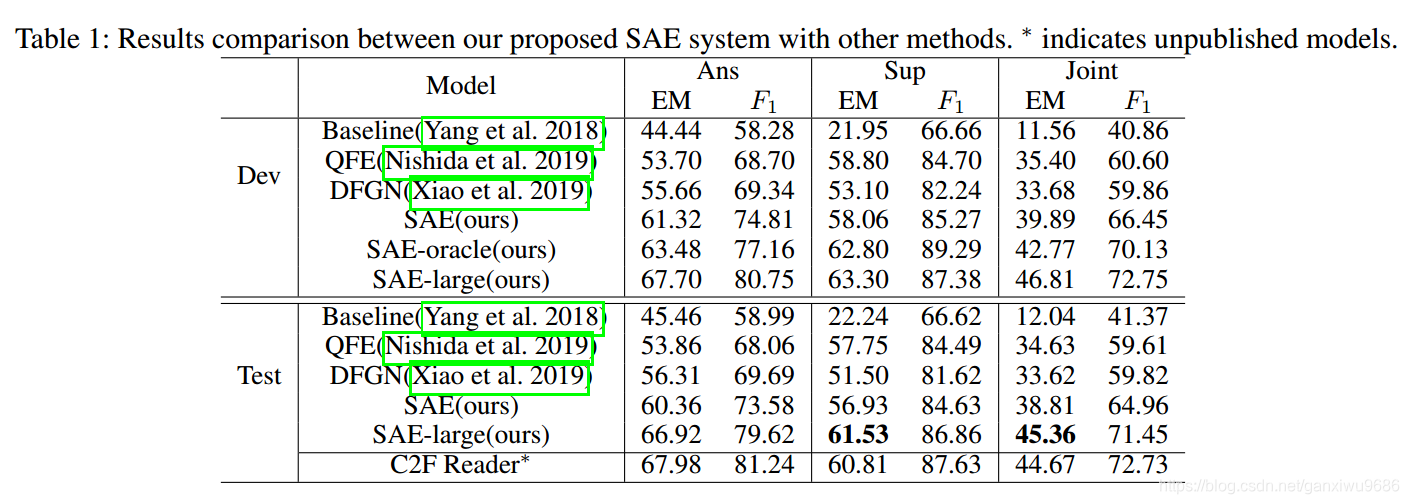
1、实验结果在榜单上当时取得第2名。下面是在验证集合测试集上面的具体效果。
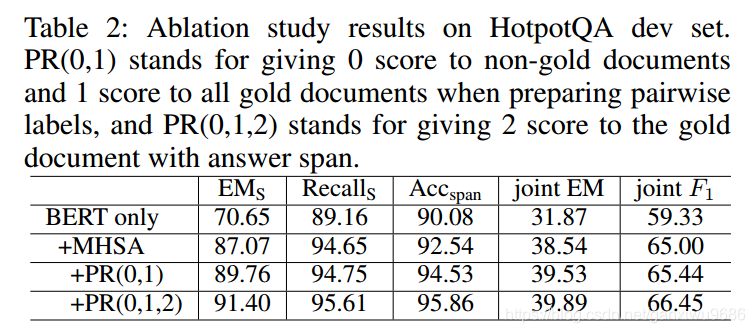
2、这个实验主要是验证了,在加入我们的多头注意力网络。以及对打分安排权重的去除实验。通过加入文档对之间的损失,实验效果也会得到一定的提升。
主要验证的是文档选择器的准确率:
3、对GNN的去除实验

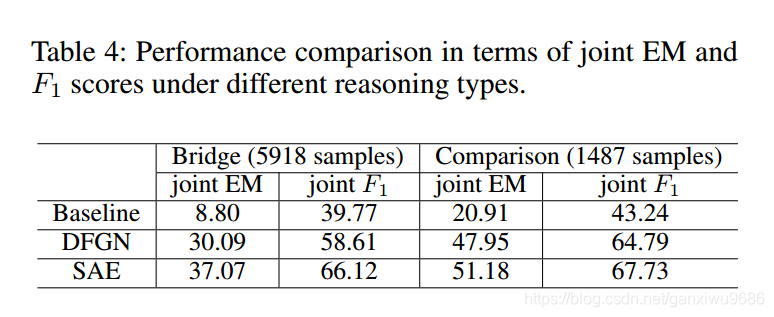
3、对不同类型的问题,效果都有所提升,尤其是存在跳转类型的问题。
4、Discussion
文章提到:first accurately filters out unrelated documents and then performs joint prediction of answer and supporting evidence.
这篇文章写的比较流畅,实验效果也还可以。看起来不是那么的复杂,简洁明了
问题的话就是他在计算图卷集的时候,把所有的句子节点都加入到途中,是否会造成图过大的问题?
第2个问题是他的这种pipeline的形式,最后答案的预测结果其实还是比较依赖之前的文档选择器的。