《Cognitive Graph for Multi-Hop Reading Comprehension at Scale》
这篇文章是清华和阿里巴巴共同发表在2019acl上面。主要是从推理能力和可解释性方面结合预训练语言模型以及图神经网络,构造了CogQA。在hotpotqa数据集上面取得了很好的效果。
分以下四部分介绍:
- Motivation
- Model
- Experiment
- Discussion
1、Motivation
这篇文章认为深度学习已经取得了很大的进步,但是在人类和机器的理解能力方面还是存在一定的鸿沟,主要表现在三个方面。1推理能力,2可解释性,3Scalability。之前针对这种数据集的方法,都是先检索,然后根据检索的文档去进行回答。可是存在的问题就是在这种多跳的数据集当中,在后几跳,其实真实文档和问题相关性会很低。
为了解决这些问题,作者从dual process theory出发。这个理论呢认为大脑主要包括两个系统,第1个系统它是一个隐式的,无意识的,直觉的过程。同时它也会检索一些比较相关的信息。第2个系统它是显式的,有意识的,可控的推理过程。系统一会根据当前的需求提供一些resources,系统二接下来就会进行一个深度的关系信息挖掘。因此可以使用预训练语言模型来表示系统一,使用图的形式来表示系统二,图中的节点表示的是抽取的实体,和实体之间的连接会形成一条可推理的路径,也提高了模型的可解释性。
2、Model
模型主要包括两个系统,BERT+GNN,下图是算法流程:

2.1 overview
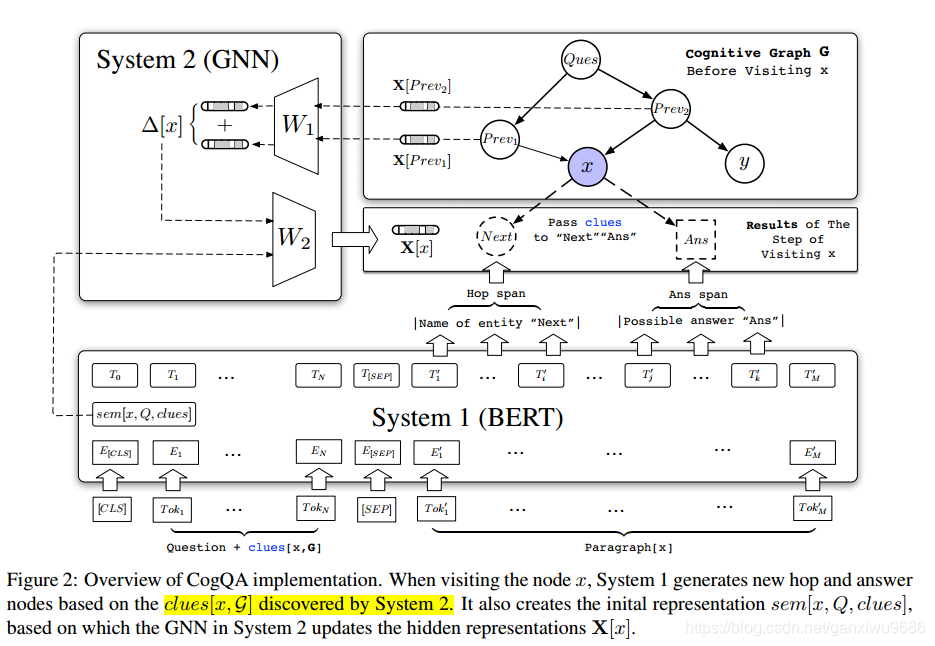
2.2 system1
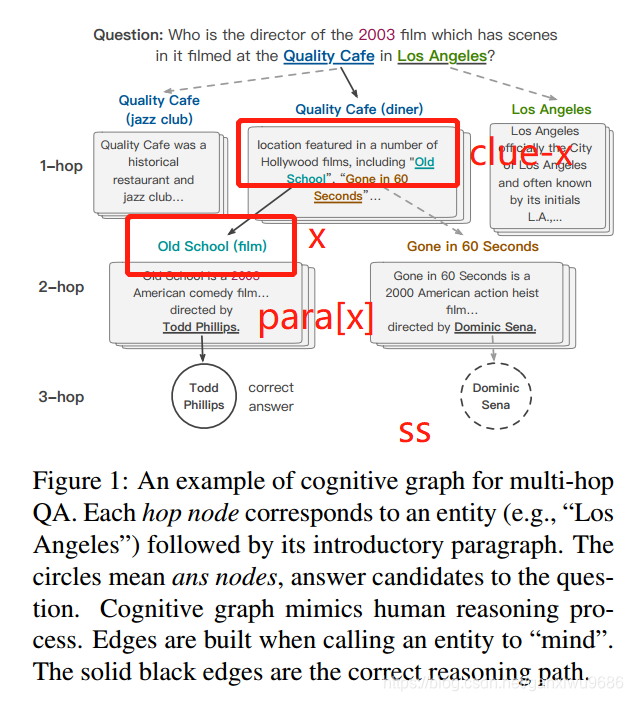
如图所示,系统一的输入包括三部分,在图1当中已经标出。我们以old school为例,线索就是指当前节点的上一个节点当中,包含该实体的句子。而paragraph就指的是当前节点抽取的维基百科段落(抽取哪一个段落是有index的)
经过bert之后会得到两种实体,一个是跳转节点,一个是答案节点。文章说的是答案节点最多只有一个跳转节点可能会有多个。同时得到sem[x,Q,clues],作为当前节点x的初始向量。文章引入指针向量,类似抽取式MRC中的方法,构造损失函数,对系统1进行更新。 T i T_i Ti 表示Bert的输出向量。

这里提一个小问题,就是对于从问题当中抽取出来的实体,是没有线索的,只有question输入。虽然也可以计算得到语义向量sem,但是文章说不计算语义向量,那么问题实体当中的节点怎么去初始化?怎么进行更新,还是说他不参与整个图的更新?

2.3 system2
从算法流程图可以看出:
对于抽取出来的跳转节点当中的每一个节点,如果他不属于图,但是在维基百科当中能够去检索,那么我们会在图中创造一个新的跳转节点(不加边)。如果这个节点已经在图里面了,但是这条边并不在图里面,那么我们就会建立一条从实体x指向实体y的一条边,并且把这个节点y作为一个边界节点(我理解的这个是一个队列?)。
对于答案节点当中的任何一个节点,我们都会把这个节点和边加入G中。
这些新加入的节点不参与图更新,因为他们的初始向量还没有表示出来(System 1计算的)。
更新图!更新方式如下:
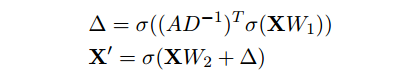
从这个反复迭代的过程来说,这个图的更新应该是一个动态的更新,因为笔者接触GNN比较少。昨天和同学也讨论了一下这种动态的更新,它的邻接矩阵是在动态的变化,而且它节点的表示,也就是说h,也是在每一次迭代过程中节点数都会加1。这种更新方式和一般的GNN的更新方式是一致的吗?
2.3 predictor
文章当中包含的问题主要分为三类,一般疑问,特殊疑问,选择疑问。对于一般疑问句,回答的答案往往是某个实体,所以作者使用了一个两层的FCN,去对整个图上的节点进行预测。然后归一化,选择得分最高的那个节点作为答案。
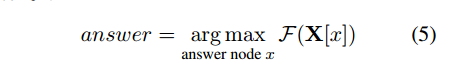
对于另外的两种问题,回答往往是yes or no或者是比较问题当中的实体x和y。这样的情况下构建了另外的一个二分类器,让模型作出选择,获得答案。
3.4 training
训练的时候他会提前先抽取出next hop和answers spans。笔者认为这个地方它应该是根据数据集当中的supporting fact,对每一篇文档去做一个实体的模糊匹配,然后确定标签spans。

注意!此处的标签,对于答案来说,因为每个段落最多只有一个答案,所以答案的span对应的标签就是1。但是对于跳转节点来说,可能会有多个跳转节点,因此我们把跳转节点的span对应的标签设置为k/1。K为当前段落抽取出的跳转节点数量。目的的话就是希望模型能够把当前段落当中我想要的实体都能够赋予它同等的概率。
同时对于Top k的spans来说,那些开始概率低于阈值的将会被舍弃,即不参与到loss中计算。阈值我们选取cls对应的向量的概率 P 0 P_0 P0。
文章提到,为了能够保证去判别不相关文档的能力,那些不相关的negative hops nodes也会被提前加到图当中(是不是把context字段中不包含supporting fact中实体的那些实体当做负实体?)
而且如果是这些负实体作为系统一的输入。那么答案标签,我们直接把cls设置为1,即阈值最高,过滤所有的节点:
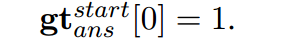
最后的ans和hops的loss计算如下:
图的loss计算:
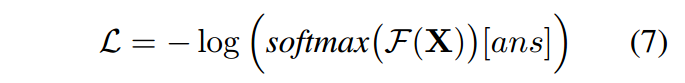
在训练的时候,每一个样例都会有一个gold graph,下面说明是如何构建的
Each training sample is a composition of the gold only graph, which is the union of all correct reasoning paths, and negative nodes. 
3、Experiment
3.1 dataset
数据当中包含若干个字段, Question, supporting facts, answer, Context。
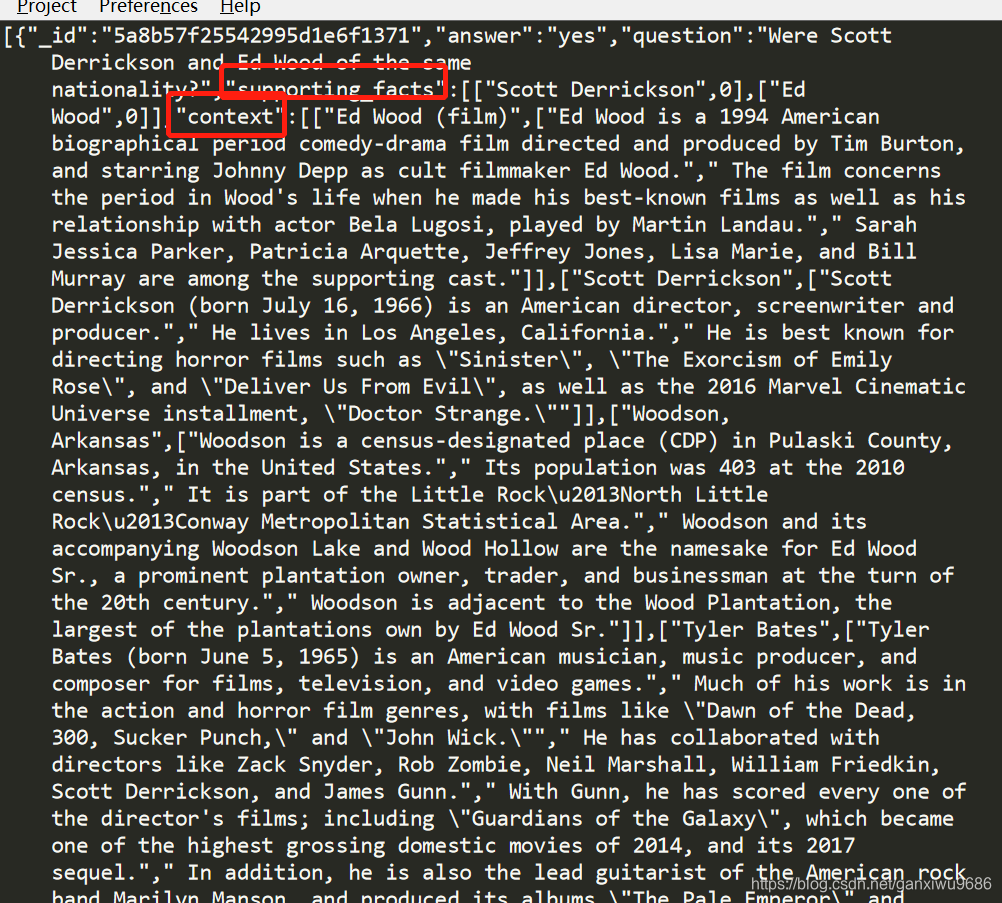
在训练集当中,对于每一个问题都会提供一个答案和包含两个gold实体的段落,以及多个支持事实。同时也有8个副样本。在验证的时候呢,只有问题被提供,除了在给出答案的情况下,还要给出支持事实。
文章提到,抽取的一跳实体可以改善其他检索模型的效率。(是指在原来的基础上再用问题中的实体去检索相关文档?)

3.2 Results
三列分别表示在答案层面,支持事实层面以及两者同时考虑的EM和F1评价指标。

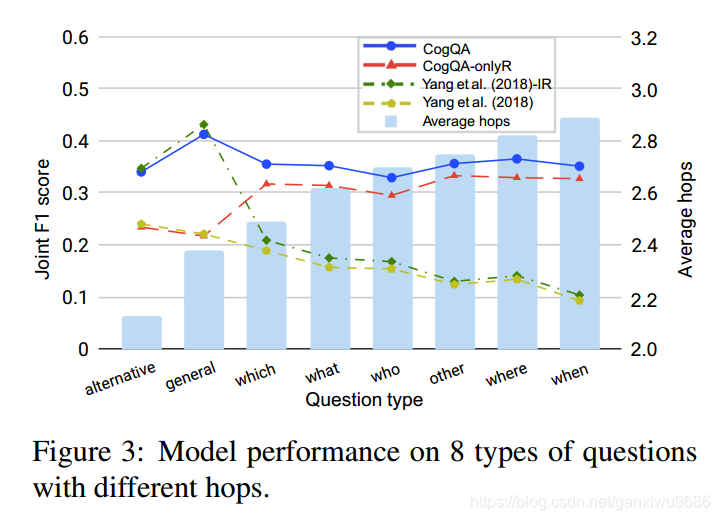
不同类别的问题,不同模型的效果。跳数也逐渐增加。
三种类型的图结构,树结构,汇聚结构,循环结构:
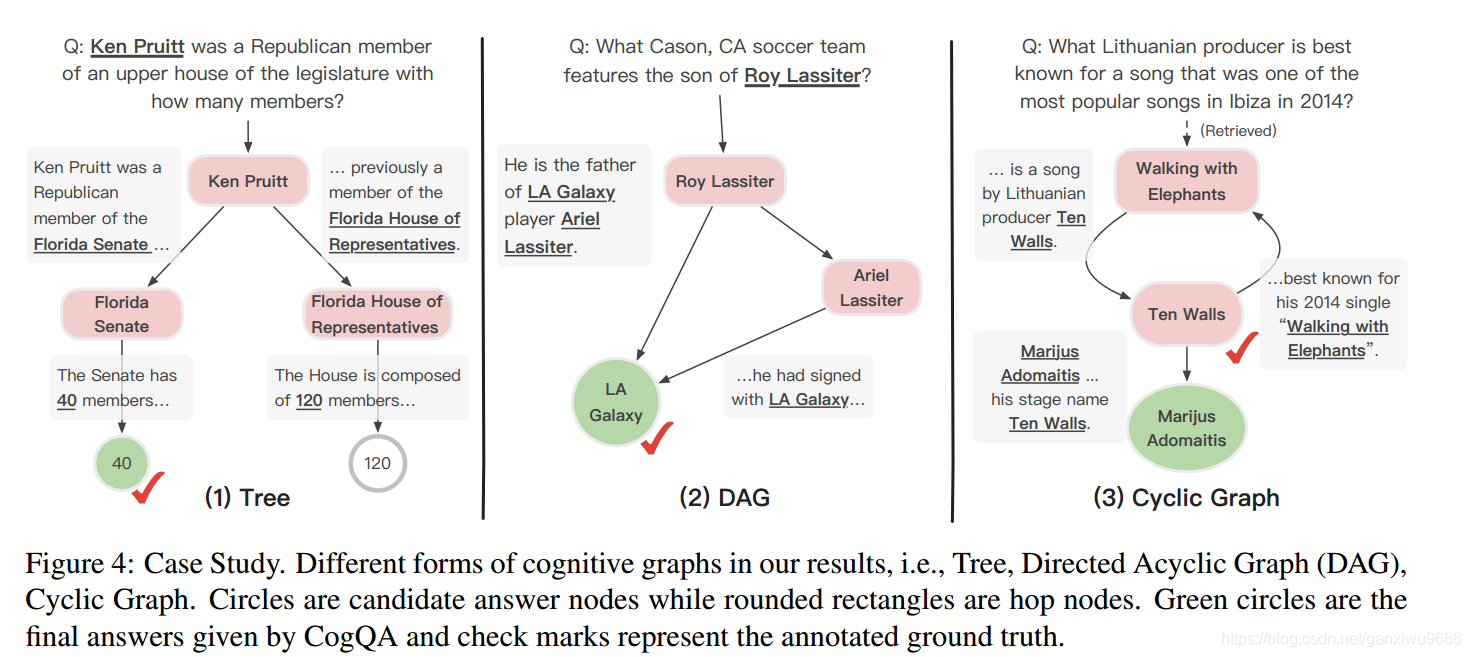
在 ablation 中,提到:

用检索的实体进行图的初始化?文章不是说用sem()向量去初始化吗? 这里的初始化应该不是指节点向量的初始化,可能是就把他们当成一跳的实体节点而已。
4、Discussion
- 这篇文章写的很好,利用图的路径增强模型的可解释性,而且在数据集上取得了很好的效果。
- 模型方面的改动其实不是很大,就是一个BERT+GNN,其实后续可以从这个角度入手,继续提升模型的效果。
- 标签的构造还不是很清楚。每个文档当中包含的实体数量都不尽相同。(想明白了,就是如果有多个实体的话,直接把它的开始和结束位置的标签都置为1/n。然后对应的标签就是0和1/n组成的一个向量。答案的话就是如果存在答案,那么就是真实答案的开始和起始位置的标签为1,如果不存在答案就是cls对应的位置为1)
- 那么其他问题的话就在博客里面都给加粗了,希望有大佬能够帮我解决一下。