下载 安装
Mysql安装板https://dev.mysql.com/downloads/windows/installer/8.0.html
卸载后,还需要删除Mysql文件夹+programData下的Mysql文件夹
最好还要清理一下注册表,不过使用IObit卸载会自动清理注册表
免安装版下载地址:
Mysql免安装版https://dev.mysql.com/downloads/mysql/
下载后得到zip压缩包,放在固定文件夹下,以后就不能变动了。
解压到自己想要安装到的目录,本人解压到的是C:\Environment
添加环境变量,选择PATH,在其后面添加: 你的mysql 安装文件下面的bin文件夹
C:\Environment\mysql-8.0.20-winx64\bin
在C:\Environment\mysql-8.0.20-winx64下新建my.ini文件,注意替换路径位置
[mysqld]
basedir=C:\Environment\mysql-8.0.20-winx64\
datadir=C:\Environment\mysql-8.0.20-winx64\data\
port=3306
skip-grant-tables
管理员模式下的CMD,并将路径切换至mysql下的bin目录,然后输入
mysqld –install
如果提示 由于找不到msvcp120.dll是因为缺少运行库
自行下载安装vcredist 地址:https://www.microsoft.com/zh-CN/download/details.aspx?id=40784
mysqld --initialize-insecure --user=mysql # 初始化数据文件
由于找不到VCRUNIIME140_1.dll,无法继续执行代码
https://cn.dll-files.com/vcruntime140_1.dll.html(选择最新版本)
文件包解压后,vcruntime140_1.dll 复制贴入 C:\Windows\System32 (我当前是64位的)
然后再次启动mysql net start mysql
然后用命令mysql –u root –p进入mysql管理界面(密码可为空)如果提示无法连接就自行去启动服务
(如果服务启动后会立刻自动停止,需要将mysql.ini文件最后一句注释掉 #skip-grant-tables)
进入界面后更改root密码
在MySQL8新版中修改密码的命令给严格限制了,应该使用:
alter user'root'@'localhost' identified with mysql_native_password by '123456' ;
还有一种方式这种对于8.0以下版本会报语法错误。
flush privileges; 刷新权限
my.ini文件删除最后一句skip-grant-tables
net stop mysql
net start mysql
创建用户 & 授权
创建用户命令:CREATE USER 'username'@'host' IDENTIFIED BY 'password';
说明:
username:你将创建的用户名
host:指定该用户在哪个主机上可以登陆,如果是本地用户可用localhost,如果想让该用户可以从任意远程主机登陆,可以使用通配符%
password:该用户的登陆密码,密码可以为空,如果为空则该用户可以不需要密码登陆服务器
例子:
CREATE USER 'dog'@'localhost' IDENTIFIED BY '123456';
CREATE USER 'pig'@'192.168.1.101_' IDENDIFIED BY '123456';
CREATE USER 'pig'@'%' IDENTIFIED BY '123456';
CREATE USER 'pig'@'%' IDENTIFIED BY '';
CREATE USER 'pig'@'%';
授权:
命令:GRANT privileges ON databasename.tablename TO 'username'@'host'
说明:
privileges:用户的操作权限,如SELECT,INSERT,UPDATE等,如果要授予所的权限则使用ALL
databasename:数据库名
tablename:表名,如果要授予该用户对所有数据库和表的相应操作权限则可用*表示,如*.*
例子:
GRANT SELECT, INSERT ON test.user TO 'pig'@'%';
GRANT ALL ON *.* TO 'pig'@'%';
GRANT ALL ON maindataplus.* TO 'pig'@'%';
注意:
用以上命令授权的用户不能给其它用户授权,如果想让该用户可以授权,用以下命令:
GRANT privileges ON databasename.tablename TO 'username'@'host' WITH GRANT OPTION;
在navicat链接mysql8以后的版本时,会出现2059的错误,
这个错误出现的原因是在mysql8之前的版本中加密规则为mysql_native_password,
而在mysql8以后的加密规则为caching_sha2_password。
解决此问题有两种方法,一种是更新navicat驱动来解决此问题,
一种是将mysql用户登录的加密规则修改为mysql_native_password。本文采用第二种方式。
ALTER USER 'root'@'localhost' IDENTIFIED BY 'password' PASSWORD EXPIRE NEVER; #修改加密规则
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password'; #更新一下用户的密码
FLUSH PRIVILEGES; #刷新权限
Delete FROM user Where User='pig' and Host='localhost';
flush privileges;
三范式
- 每个字段不可再分
比如:学生表,班级字段,班级还有所属班级,班主任,班号等多个属性,是可分割的,应该将班级有关字段全部归到新建的班级表,给学生信息增加一个字段:班级code,用来关联班级; - 所有列都必须依赖于主键,即有直接关系
也就是说一个表只描述一件事情;也有人说是每一条记录都必须有主键 - 数据不能存在传递关系
即每个属性都跟主键有直接关系而不是间接关系。像:员工编号-员工部门-部门名称 属性之间含有这样的关系,是不符合第三范式的,部门名称是关联部门id的,二和员工编号没有直接关系;
举例:比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)
这样一个表结构,就存在上述关系。 学号–> 所在院校 --> (院校地址,院校电话)
这样的表结构,我们应该拆开来,如下。
(学号,姓名,年龄,性别,院校id)–(院校id,院校名称,院校地址,院校电话)
ps:其实核心就是为了让表所存储的数据不要出现冗余
反范式(三范式的改进)
三范式为了不产生冗余数据,但这样关联性极强的表设计带来的数据的查询速度较慢,为了提高速度有时候需要反着来设计。
- 横向切割
比如sunline的日报表数据很多,可以将2018年之前的存一张表中,之后日期的存另一张表中,保证单表数据量不会过大。 - 纵向切割
sunline人员基本信息表pcmc_user如果存用户的毕业院校、身高等等很多不是特别重要的字段,表会特别沉重,所以相对而言不太重要的字段放在另一张表hr_user_base_info中。 - 增加冗余列
sunline日报表存project_id,每次查询要关联项目表,来获取project_name会速度很慢,因为日报表本身数据量巨大,所以日报表将project_id和project_name同时存入日报表中,就不用每次查询时候去left join项目表了,可以增加速度。但是缺点是project_name可能会变化,就需要同时修改两张表的数据了。 - 增加附加列
sunline考勤打卡表,记录员工每日签到和签退时间,使用的时候需要sql查初迟到和早退时间,每次去计算效率不高,因此可以增加签到时间-09:00就是late_time,以及签退时间-17:30就是早退时间early_time,查询时候就不需要计算,可提高速度。
分库分表
垂直分表
将访问频次低的商品描述信息单独存放在一张表中,访问频次较高的商品基本信息单独放在一张表中
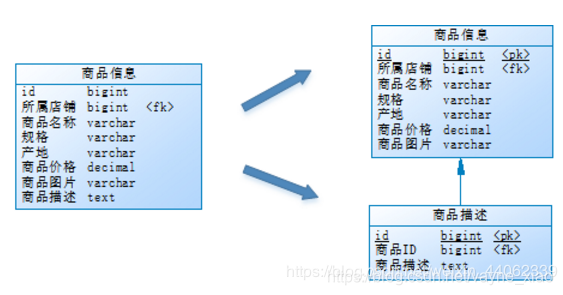
垂直分表定义:将一个表按照字段分成多表,每个表存储其中一部分字段。
它带来的提升是:
- 为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响
- 充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累。
为什么大字段IO效率低:第一是由于数据量本身大,需要更长的读取时间;第二是跨页,页是数据库存储单位,很多查找及定位操作都是以页为单位,单页内的数据行越多数据库整体性能越好,而大字段占用空间大,单页内存储行数少,因此IO效率较低。第三,数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
通常我们按以下原则进行垂直拆分:
- 把不常用的字段单独放在一张表;
- 把text,blob等大字段拆分出来放在附表中;
- 经常组合查询的列放在一张表中;
垂直分库
通过垂直分表性能得到了一定程度的提升,但是还没有达到要求,并且磁盘空间也快不够了,因为数据还是始终限制在一台服务器,库内垂直分表只解决了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。
经过思考,他把原有的SELLER_DB(卖家库),分为了PRODUCT_DB(商品库)和STORE_DB(店铺库),并把这两个库分散到不同服务器,如下图:
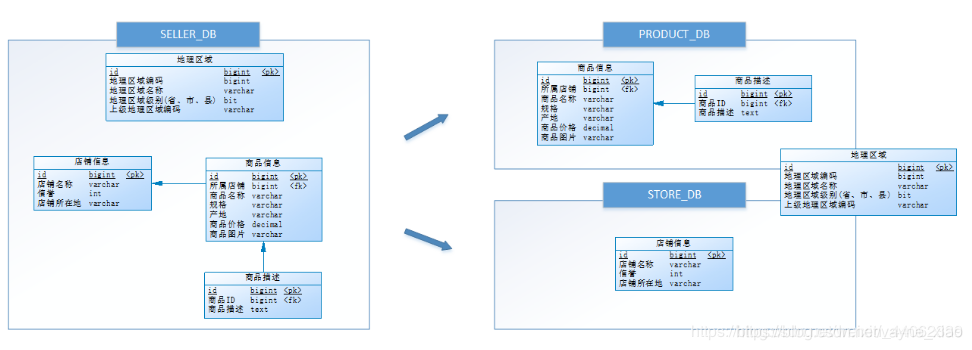
由于商品信息与商品描述业务耦合度较高,因此一起被存放在PRODUCT_DB(商品库);而店铺信息相对独立,因此单独被存放在STORE_DB(店铺库)。
垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。
水平分库
将店铺ID为单数的和店铺ID为双数的商品信息分别放在两个库中。
水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库了,经过水平切分的优化,往往能解决单库存储量及性能瓶颈。但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
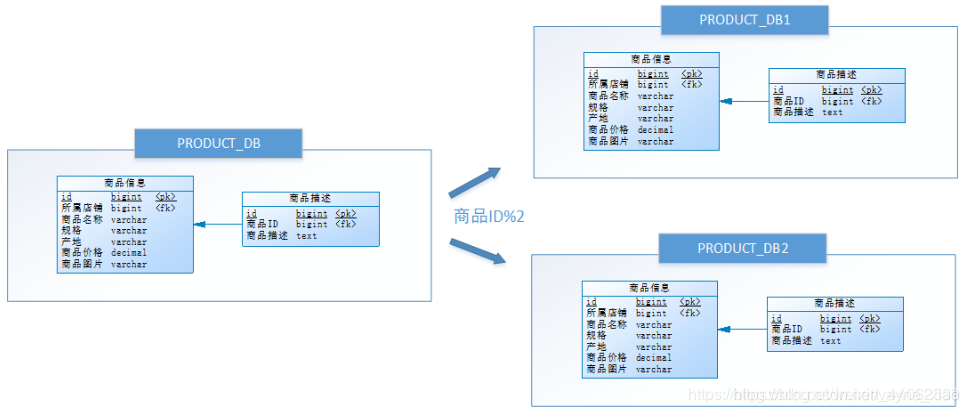
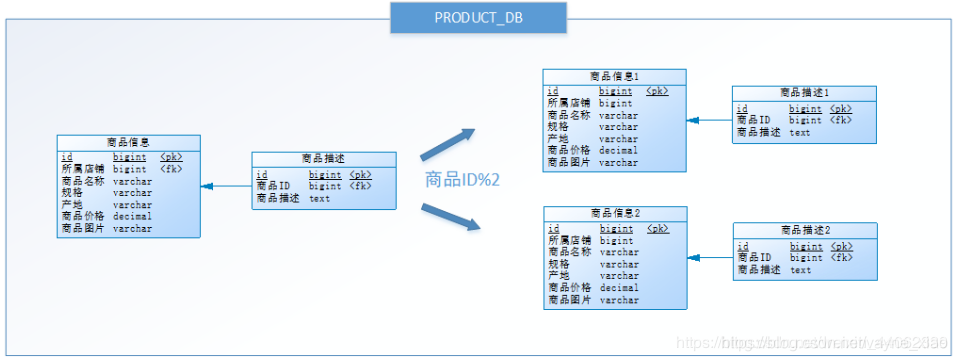
水平分表
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
总结
-
垂直分表:可以把一个宽表的字段按访问频次、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提升部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失。
-
垂直分库:可以把多个表按业务耦合松紧归类,分别存放在不同的库,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题。
-
水平分库:可以把一个表的数据(按数据行)分到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能。它不仅需要解决跨库带来的所有复杂问题,还要解决数据路由的问题(数据路由问题后边介绍)。
-
水平分表:可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化。
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。