有效个数(Quorum)
有效个数(Quorum)这个设计模式一般是指分布式系统的每一次修改都要在大多数实例上通过来确定修改通过。
问题背景
在一个分布式存储系统中,用户请求会发到一个实例上。通常在一个实例上面执行的修改,需要复制到其他的实例上,这样可以保证在原实例挂了的情况下,用户依然可以看到这个修改。这就涉及到一个问题,究竟复制到多少个其他实例上之后,用户请求才会返回成功呢?如果复制的实例个数过多,那么请求响应时间就会更长;如果复制的实例过少,则这个修改可能会丢失。取得这个平衡性很重要,这也是分布式 PACELC 中的 L(Latency) 与 C(Consistency) 的取舍。
解决方案
当一个修改,被集群中的大部分节点(假设个数为N)通过之后,这个修改也就被这个集群所接受。这个 N 就是有效个数。假设集群数量为 n,那么 N = n/2 + 1.例如 n = 5,则 N = 3.
这个有效个数,间接地体现了集群中最多可以有多少个实例挂掉,这个数量就是 f = n - N。通常的,如果我们期望可以忍受 f 个实例挂掉,那么集群就至少要有 2f + 1 个实例。
以下就是两个经典需要有效个数这个设计模式的场景:
- 更新存储集群中的数据。同时还会涉及到最高水位线(High-Water Mark)这个设计模式,用于标注截止到哪里的日志,已经同步到了集群中的大多数实例。
- 选主。在主从(Leader and)设计模式中,被有效个数选举为主的就是最终的主。
如何设计集群个数
目前主流的集群设计模式有如下两种:
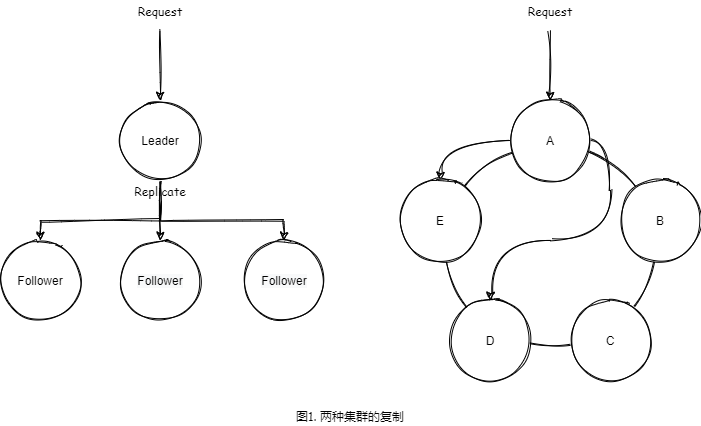
- 第一种是主从同步模式:
- 一种是请求发往主,主负责同步到其他从上面,之后返回。如果请求发到了从上面,则从发到主上面处理。例如 Zookeeper 就是这么做的。
- 另一种是,请求发到哪个实例,哪个实例就是主,主将请求同步到从上面。例如 Eureka 就是这么设计的。
- 第二种是分区模式,集群中不同节点存储不同数据。一般的,这个数据切分经常采用一致性哈希。假设请求发送到了 A,经过 A 的计算,这个数据需要存储在 D,并且我们配置的存储备份是一份,这个备份是在 E 上面,这样这个请求就会被同步到 D,E 上面。ElasticSearch,Riak,Dynamo 就是这种类似的设计。
在这种设计模式下的系统,主要考虑两点:
- 写操作的吞吐量。因为每次写入集群,都要复制到多个实例,所以肯定会对性能有所影响。一般的,复制是并发复制的,这个性能主要受本次同步最慢的那个实例的影响。
- 可以容忍的实例挂掉的个数。这样的集群,如果我们期望可以忍受 f 个实例挂掉,那么集群就至少要有 2f + 1 个实例。
实现举例
1. Zookeeper 的两阶段提交 + 半数以上写入机制
客户端把写请求发送到 leader 节点上(如果发送的是 follower 节点,follower节点会把写请求转发到leader节点),leader节点会把数据通过proposal请求发送到所有节点(包括自己),所有到节点接受到数据以后都会写到自己到本地磁盘上面,写好了以后会发送一个ack请求给leader,leader只要接受到过半的节点发送ack响应回来,就会发送commit消息给各个节点,各个节点就会把消息放入到内存中(放内存是为了保证高性能),该消息就会用户可见了。
2. Riak,DynamoDB
在默认情况下,是 P+A 以及 E+L 的系统,但是可以根据配置修改,主要基于NWR模型与同步和异步备份。N 代表 N 个备份,W 代表要写入至少 W 份才认为成功,R 表示至少读取 R 个备份。配置的时候要求 W+R > N。 因为 W+R > N, 所以 R > N-W。这个是什么意思呢?就是读取的份数一定要比总备份数减去确保写成功的倍数的差值要大。
也就是说,每次读取,都至少读取到一个最新的版本。从而不会读到一份旧数据。当我们需要高可写的环境的时候(例如,amazon 的购物车的添加请求应该是永远不被拒绝的)我们可以配置W = 1 如果N=3 那么R = 3。 这个时候只要写任何节点成功就认为成功,但是读的时候必须从所有的节点都读出数据。如果我们要求读的高效率,我们可以配置 W=N R=1。这个时候任何一个节点读成功就认为成功,但是写的时候必须写所有三个节点成功才认为成功。
大家注意,一个操作的耗时是几个并行操作中最慢一个的耗时。比如R=3的时候,实际上是向三个节点同时发了读请求,要三个节点都返回结果才能认为成功。假设某个节点的响应很慢,它就会严重拖累一个读操作的响应速度
3. MongoDB
MongoDB 和上面的 Dynamo 类似,MongoDB关于一致性、可用性的权衡,取决于三者:
write-concern: 表示当写请求在value个MongoDB实例处理之后才向客户端返回read-concern: 设定是否必须从 primary 读取最新的数据还是可以从 secondary 读取最终一致性的数据。read-preference: 对于replica set,是返回当前节点的最新数据,还是返回写入节点最多的数据,还是根据一些函数计算出的数据。
微信搜索“我的编程喵”关注公众号,每日一刷,轻松提升技术,斩获各种offer:
