pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)
参数说明:
data : array-like, Series, or DataFrame 输入的数据
prefix : string, list of strings, or dict of strings, default None. get_dummies转换后,列名的前缀
columns : list-like, default None 指定需要实现类别转换的列名
dummy_na : bool, default False 增加一列表示空缺值,如果False就忽略空缺值
drop_first : bool, default False 获得k中的k-1个类别值,去除第一个
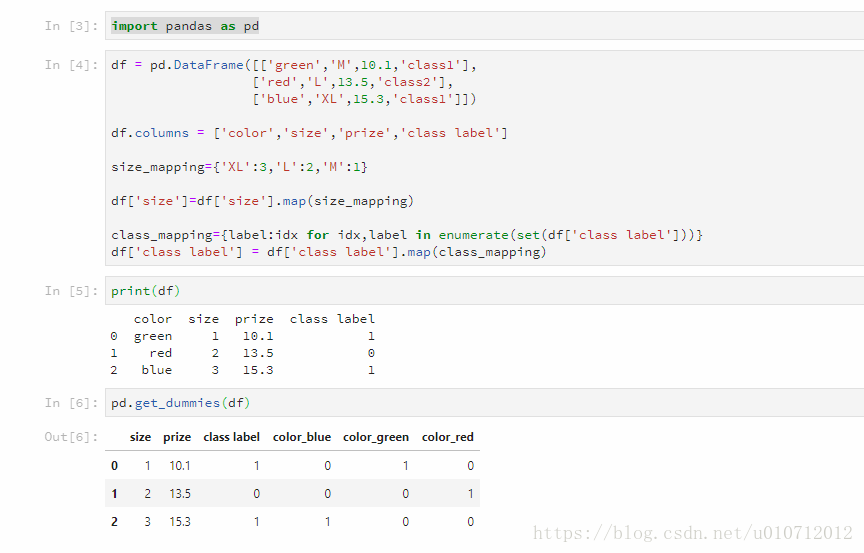
get_dummies是一种onehot编码方式,将拥有不同值的变量转换为0/1数值。比如说我们将yellow,red,blue三种颜色分别用1,2,3表示它们的编号。只是用1,2,3区分,实际上1,2,3是没有什么数值上的意义。
import pandas as pd
xiaoming=pd.DataFrame([1,2,3],index=['yellow','red','blue'],columns=['hat'])
print(xiaoming)
hat_ranks=pd.get_dummies(xiaoming['hat'],prefix='hat')
print(hat_ranks.head())输出结果:
hat
yellow 1
red 2
blue 3
hat_1 hat_2 hat_3
yellow 1 0 0
red 0 1 0
blue 0 0 1再举一个例子,我们没有设定编号,只给定了种类(color和class)。让程序自带的编号作为区分种类,得到的结果如下:
import pandas as pd
df = pd.DataFrame([
['green' , 'A'],
['red' , 'B'],
['blue' , 'A']])
df.columns = ['color', 'class']
pd.get_dummies(df) 
还有要注意的是:
离散特征的编码分为两种情况:
1、离散特征的取值之间没有大小的意义,比如color:[red,blue,green],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}