第四章 数据的概括性度量
4.1 集中趋势的度量
4.1.1 分类数据:
- 众数( M o : m o d e M_o:mode Mo:mode):一组数据中出现次数最多的变量值。
4.1.2 顺序数据:
- 中位数( M e : m e d i a n M_e :median Me:median):是一组数据排序后处于中间位置上的变量值。
- 中位数位置 p o s = n + 1 2 pos = \frac{n+1}{2} pos=2n+1, M e = { p o s 位 上 的 值 , n 为 奇 数 ; 对 p o s 向 上 、 向 下 取 整 的 两 个 位 置 数 的 平 均 数 , n 为 偶 数 ; M_e= \left\{ \begin{aligned} & pos位上的值 &,n为奇数;\\ \\ & 对pos向上、向下取整\\ &的两个位置数的平均数 &,n为偶数; \end{aligned} \right. Me=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧pos位上的值对pos向上、向下取整的两个位置数的平均数,n为奇数;,n为偶数;
- 四分位数( Q L Q_L QL, Q U Q_U QU):一组数据排序后处于25%和75%位置上的值。
- 下四分位数( Q L : q u a r t i l e l o w Q_L:quartile \ low QL:quartile low)
- 上四分位数( Q U : q u a r t i l e u p Q_U:quartile \ up QU:quartile up)
- 四分位数的位置 p o s : pos: pos:

- 四分位数的取值:
- 在整数位置上:就是该位置上的值;
- 在0.5的位置上:对pos向上、向下取整的两个位置数的平均值;
- 在0.25或0.75的位置上:对pos向下取整的数 + (对pos向上取整的数 - 对pos向下取整的数) * 0.25或0.75
4.1.3 数值型数据:
- 平均数( x ˉ \bar x xˉ):
- 简单平均数 :
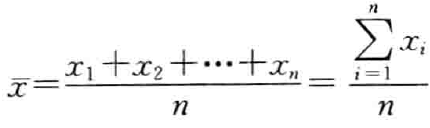
- 加权平均数( M i M_i Mi是各组的组中值,200~250组中值就是225; f i f_i fi是各组变量值出现的频数):

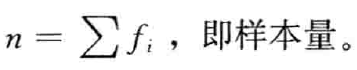
- 几何平均数( G : g e o m e t r i c m e a n G:geometric \ mean G:geometric mean):主要用于计算平均比率

- 简单平均数 :
4.1.4 众数和中位数和平均数的比较:
- 左偏分布(平均数 x ˉ \bar x xˉ最小,众数 M o M_o Mo最大,平均数<中位数<众数);
- 右偏分布(平均数 x ˉ \bar x xˉ最大,众数 M o M_o Mo最小,众数<中位数<平均数);
- 对称分布(三者相等,众数 = 中位数 = 平均数)

4.2 离散程度的度量
4.2.1 分类数据:
- 异众比率( V r : v a r i a t i o n r a t e V_r:variation \ rate Vr:variation rate):不是众数的数占总体数据的比率
- 异众比率主要用于衡量众数对一组数据的代表性;
- 异众比率适合测度分类数据的离散程度

4.2.2 顺序数据:
- 四分位差( Q d : q u a r t i l e d e v i a t i o n Q_d:quartile \ deviation Qd:quartile deviation):
- 四分位差反映了中间50%的数据的离散程度,数值越小说明数据越集中,数值越大说明说明数据月分散;
- 四分位差主要用于测度数据的离散程度
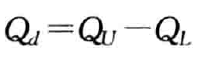
4.2.3 数值型数据:
自由度:样本个数-1,即 n-1;
- 极差( R : r a n g e R:range R:range):一组数据的最大值和最小值之差
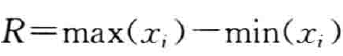
- 平均差:

- 标准差和方差:
-
标准差( s : s t a n d a r d d e v i a t i o n s:standard \ deviation s:standard deviation):

-
方差( s 2 : v a r a n c e s^2:varance s2:varance):
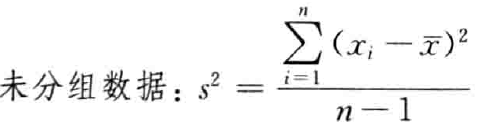
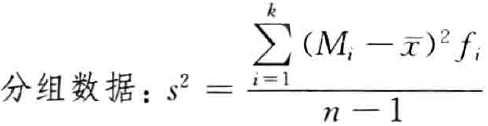
-
- 相对位置的度量
- 标准分数:变量值与其平均数的离差除以标准差以后的值。
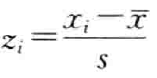

- 经验法则:当一组数据对称分布时,在 ± 3 \pm 3 ±3 个标准差之外的数据,称为离群点。

- 切比雪夫不等式:对任何分布形态的数据都适用(非对称分布就用这个),至少有比例为 ( 1 − 1 k 2 ) (1-\frac{1}{k^2}) (1−k21)的数据在 ± k \pm k ±k 个标准差内( k k k是大于1的任意数)。

- 标准分数:变量值与其平均数的离差除以标准差以后的值。
4.2.4 相对离散程度:
- 离散系数( v s : c o e f f i c i e n t o f v a r i a t i o n v_s:coef\!ficient \ of \ variation vs:coefficient of variation):也称为变异系数,是一组数据的标准差和其平均数之比。


4.3 偏态与峰态的度量
4.3.1 偏态及其测度
- 偏态( s k e w n e s s skewness skewness):对数据分布对称性的测度;
- 偏态系数( S K SK SK):测度偏态的统计量;
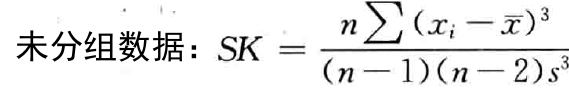

数 据 的 分 布 : { 对 称 , S K = 0 非 对 称 , S K ≠ 0 { 中 等 偏 态 分 布 , 0.5 < ∣ S K ∣ < 1 高 等 偏 态 分 布 , ∣ S K ∣ > 1 数据的分布: \begin{cases} 对称 &,SK = 0 \\ 非对称&,SK \ne 0 \begin{cases} 中等偏态分布 &,0.5<|SK| < 1\\ 高等偏态分布 &,|SK| > 1 \end{cases} \end{cases} 数据的分布:⎩⎪⎨⎪⎧对称非对称,SK=0,SK=0{ 中等偏态分布高等偏态分布,0.5<∣SK∣<1,∣SK∣>1
数 据 的 偏 斜 : { 左 偏 ( 负 偏 ) , S K < 0 右 偏 ( 正 偏 ) , S K > 0 数据的偏斜: \begin{cases} 左偏(负偏)&,SK < 0 \\ 右偏(正偏)&,SK > 0 \end{cases} 数据的偏斜:{ 左偏(负偏)右偏(正偏),SK<0,SK>0
4.3.2 峰态及其测度
- 峰态( k u r t o s i s kurtosis kurtosis):对数据分布平峰或尖峰程度的测度
- 峰态系数( K K K):测度峰态的统计量
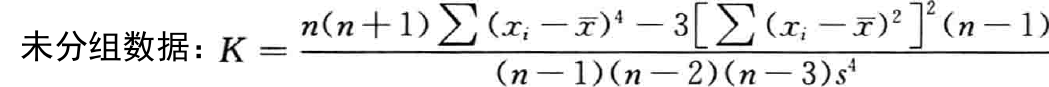
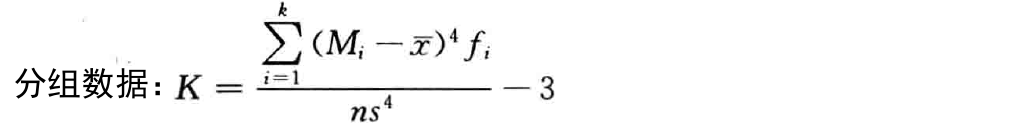
峰 态 : { 扁 平 分 布 , K < 0 , 正 态 分 布 , K = 0 , 尖 峰 分 布 , K > 0 ; 峰态: \begin{cases} 扁平分布 &,K < 0,\\ 正态分布 &,K = 0,\\ 尖峰分布 &,K > 0; \end{cases} 峰态:⎩⎪⎨⎪⎧扁平分布正态分布尖峰分布,K<0,,K=0,,K>0;