前言
随着kubernetes项目的日益火热,该项目中用到的etcd组件作为一个高可用强一致性的服务发现存储仓库,渐渐的被开发人员所关注。
在云计算时代,如何让服务快速、透明的接入到计算集群中,如何让共享配置信息快速被集群中的所有节点发现,如何构建一套高可用、安全、易于部署以及快速响应的服务集群成为了需要解决的问题。
Etcd为解决这类问题带来便捷。
官方地址: https://coreos.com/etcd/
项目地址: https://github.com/coreos/etcd
Etcd是什么
Etcd是一个高可用的键值存储系统,主要用于共享配置和服务发现,它通过Raft一致性算法处理日志复制以保证强一致性,我们可以理解它为一个高可用强一致性的服务发现存储仓库。
在kubernetes集群中,etcd主要用于配置共享和服务发现
Etcd主要解决的是分布式系统中数据一致性的问题,而分布式系统中的数据分为控制数据和应用数据,etcd处理的数据类型为控制数据,对于很少量的应用数据也可以进行处理。
Etcd和Zookeeper的比较
Zookeeper有如下缺点
-
1.复杂。ZooKeeper的部署维护复杂,管理员需要掌握一系列的知识和技能;而Paxos强一致性算法也是素来以复杂难懂而闻名于世(ETCD使用[Raft]协议, ZK使用ZAB,类PAXOS协议);另外,ZooKeeper的使用也比较复杂,需要安装客户端,官方只提供了Java和C两种语言的接口。
-
2.Java编写。这里不是对Java有偏见,而是Java本身就偏向于重型应用,它会引入大量的依赖。而运维人员则普遍希望保持强一致、高可用的机器集群尽可能简单,维护起来也不易出错。
-
3.发展缓慢。Apache基金会项目特有的“Apache Way”在开源界饱受争议,其中一大原因就是由于基金会庞大的结构以及松散的管理导致项目发展缓慢。
相较之下,Etcd
1.简单。使用Go语言编写部署简单;使用HTTP作为接口使用简单;使用Raft算法保证强一致性让用户易于理解。
-
2.数据持久化。etcd默认数据一更新就进行持久化。
-
3.安全。etcd支持SSL客户端安全认证。
Etcd的架构与术语

流程分析
通常一个用户的请求发送过来,会经过HTTP Server转发给Store进行具体的事务处理,如果涉及到节点的修改,则需要交给Raft模块进行状态的变更,日志的记录。
然后再同步给别的etcd节点确认数据提交,最后进行数据提交,再次同步。
工作原理
Etcd使用Raft协议来维护集群内各个节点状态的一致性。简单说,ETCD集群是一个分布式系统,由多个节点相互通信构成整体对外服务,每个节点都存储了完整的数据,并且通过Raft协议保证每个节点维护的数据是一致的。
Etcd主要分为四个部分
-
HTTP Server: 用于处理用户发送的API请求以及其他etcd节点的同步与心跳信息请求
-
Store: 用于处理 etcd 支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是 etcd 对用户提供的大多数 API 功能的具体实现。
-
Raft: Raft 强一致性算法的具体实现,是 etcd 的核心。
-
WAL:Write Ahead Log(预写式日志/日志先行),是 etcd 的数据存储方式,也是一种实现事务日志的标准方法。etcd通过 WAL 进行持久化存储,所有的数据提交前都会事先记录日志。Snapshot 是为了防止数据过多而进行的状态快照;Entry 表示存储的具体日志内容。
服务发现
服务发现要解决的也是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务,要如何才能找到对方并建立连接。本质上来说,服务发现就是想要了解集群中是否有进程在监听 udp 或 tcp 端口,并且通过名字就可以查找和连接。要解决服务发现的问题,需要具备以下三点:
1.一个强一致性、高可用的服务存储目录。基于 Raft 算法的 etcd 天生就是这样一个强一致性高可用的服务存储目录。
2.一种注册服务和监控服务健康状态的机制。用户可以在 etcd 中注册服务,并且对注册的服务设置key TTL,定时保持服务的心跳以达到监控健康状态的效果。
3.一种查找和连接服务的机制。通过在 etcd 指定的主题下注册的服务也能在对应的主题下查找到。为了确保连接,我们可以在每个服务机器上都部署一个 Proxy 模式的 etcd,这样就可以确保能访问 etcd 集群的服务都能互相连接。
例如随着 Docker 容器的流行,多种微服务共同协作,构成一个相对功能强大的架构的案例越来越多。透明化的动态添加这些服务的需求也日益强烈。通过服务发现机制,在 etcd 中注册某个服务名字的目录,在该目录下存储可用的服务节点的 IP。在使用服务的过程中,只要从服务目录下查找可用的服务节点去使用即可。
Etcd集群中的术语
-
Raft: etcd所采用的保证分布式系统强一致的算法
-
Node: 一个Raft状态机实例
-
Member: 一个etcd实例,管理一个Node,可以为客户端请求提供服务
-
Cluster: 多个Member构成的可以协同工作的etcd集群
-
Peer: 同一个集群中,其他Member的称呼
-
Client: 向etcd集群发送HTTP请求的客户端
-
WAL: 预写日志,是etcd用于持久化存储的日志格式
-
Snapshot: etcd防止WAL文件过多而设置的快照,存储etcd数据状态
-
Proxy: etcd的一种模式,可以为etcd提供反向代理服务
-
Leader: Raft算法中通过竞选而产生的处理所有数据提交的节点
-
Follower: Raft算法中竞选失败的节点,作为从属节点,为算法提供强一致性保证
-
Candidate: Follower超过一定时间接收不到Leader节点的心跳的时候,会转变为Candidate(候选者)开始Leader竞选
-
Term: 某个节点称为Leader到下一次竞选开始的时间周期,称为Term(任界,任期)
-
Index: 数据项编号, Raft中通过Term和Index来定位数据
Raft算法
Raft 是一种为了管理复制日志的一致性算法。它提供了和 Paxos 算法相同的功能和性能,但是它的算法结构和 Paxos 不同,使得 Raft 算法更加容易理解并且更容易构建实际的系统。一致性算法允许一组机器像一个整体一样工作,即使其中一些机器出现故障也能够继续工作下去。正因为如此,一致性算法在构建可信赖的大规模软件系统中扮演着重要的角色。
Raft算法分为三部分
Leader选举、日志复制和安全性
Raft算法特性:
1.强领导者: 和其他一致性算法相比,Raft 使用一种更强的领导能力形式。比如,日志条目只从领导者发送给其他的服务器。这种方式简化了对复制日志的管理并且使得 Raft 算法更加易于理解。
2.领导选举: Raft 算法使用一个随机计时器来选举领导者。这种方式只是在任何一致性算法都必须实现的心跳机制上增加了一点机制。在解决冲突的时候会更加简单快捷。
3.成员关系调整: Raft 使用一种共同一致的方法来处理集群成员变换的问题,在这种方法下,处于调整过程中的两种不同的配置集群中大多数机器会有重叠,这就使得集群在成员变换的时候依然可以继续工作。
Leader选举
Raft 状态机
Raft集群中的每个节点都处于一种基于角色的状态机中。具体来说,Raft定义了节点的三种角色: Follower、Candidate和Leader。
1.Leader(领导者): Leader节点在集群中有且仅能有一个,它负责向所有的Follower节点同步日志数据
2.Follower(跟随者): Follower节点从Leader节点获取日志,提供数据查询功能,并将所有修改请求转发给Leader节点
3.Candidate(候选者): 当集群中的Leader节点不存在或者失联之后,其他Follower节点转换为Candidate,然后开始新的Leader节点选举
这三种角色状态之间的转换,如下图:
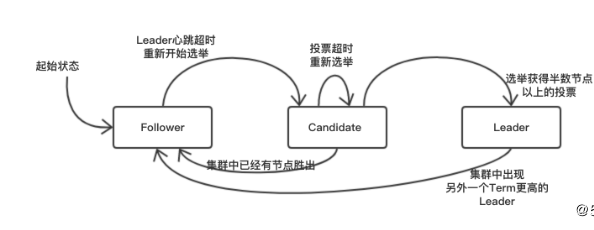
一个 Raft 集群包含若干个服务器节点;通常是 5 个,这允许整个系统容忍 2 个节点的失效。在任何时刻,每一个服务器节点都处于这三个状态之一:领导人、跟随者或者候选人。在通常情况下,系统中只有一个领导人并且其他的节点全部都是跟随者。跟随者都是被动的:他们不会发送任何请求,只是简单的响应来自领导者或者候选人的请求。领导人处理所有的客户端请求(如果一个客户端和跟随者联系,那么跟随者会把请求重定向给领导人)
在节点初始启动的时候,所有节点的Raft状态机都会处于Follower状态。当Follower在一定的时间周期内没有收到来自Leader节点的心跳数据包的时候,节点会将自己的状态切换为Candidate,并向集群中其他Follower节点发送投票请求,Follower都会将自己的票投给收到的第一个投票请求节点。当Candidate收到来自集群中超过半数节点的投票后,会成为新的Leader节点。
Leader节点将接受并保存用户发送的数据,并向其他的Follower节点同步日志。
Follower只响应来自其他服务器的请求。如果Follower接收不到消息,那么他就会变成候选人并发起一次选举。获得集群中大多数选票的候选人将成为Leader。在一个任期(Term)内,领导人一直都会是领导人直到自己宕机了。
Leader节点依靠定时向所有Follower发送心跳数据来保持地位。当急群众的Leader节点出现故障的时候,Follower会重新选举新的节点,保证整个集群正常运行。
每次成功的选举,新的Leader的Term(任期)值都会比之前的Leader增加1。当集群中由于网络或者其他原因出现分裂后又重新合并的时候,集群中可能会出现多于一个的Leader节点,此时,Term值更高的节点才会成为真正的Leader。
Raft算法中的Term(任期)
关于Term,如下图:
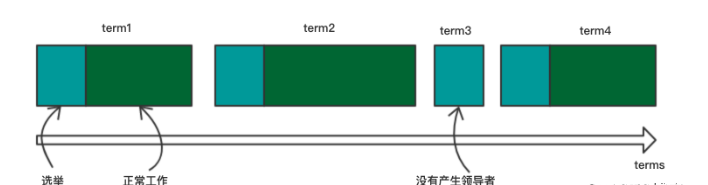
Raft会把时间分割成任意长度的任期。并且任期用连续的整数来标记。每一段任期都是从一次选举开始,一个或者多个候选人尝试成为领导者。如果一个候选人赢得选举,然后他就会在接下来的任期中充当Leader的职责。在某些情况下,一次选举会造成选票瓜分,这样,这一个任期将没有Leader。如果没有Leader,那么新的一轮选举就马上开始,也就是新的任期就会开始。Raft保证了在一个Term任期内,有且只有一个Leader。
日志复制
所谓日志复制,是指主节点将每次操作形成日志条目,并持久化到本地磁盘,然后通过网络IO发送给其他节点。
一旦一个领导人被选举出来,他就开始为客户端提供服务。客户端的每一个请求都包含一条被复制状态机执行的指令。领导人把这条指令作为一条新的日志条目附加到日志中去,然后并行的发起附加条目 RPCs 给其他的服务器,让他们复制这条日志条目。
Raft 算法保证所有已提交的日志条目都是持久化的并且最终会被所有可用的状态机执行。当主节点收到包括自己在内超过半数节点成功返回,那么认为该日志是可提交的(committed),并将日志输入到状态机,将结果返回给客户端。
在正常的操作中,领导人和跟随者的日志保持一致性,所以附加日志 RPC 的一致性检查从来不会失败。然而,领导人崩溃的情况会使得日志处于不一致的状态(老的领导人可能还没有完全复制所有的日志条目)。这种不一致问题会在一系列的领导人和跟随者崩溃的情况下加剧。跟随者的日志可能和新的领导人不同的方式。跟随者可能会丢失一些在新的领导人中有的日志条目,他也可能拥有一些领导人没有的日志条目,或者两者都发生。丢失或者多出日志条目可能会持续多个任期。这就引出了另一个部分,就是安全性
安全性
截止此刻,选主以及日志复制并不能保证节点间数据一致。试想,当一个某个节点挂掉了,一段时间后再次重启,并当选为主节点。而在其挂掉这段时间内,集群若有超过半数节点存活,集群会正常工作,那么会有日志提交。这些提交的日志无法传递给挂掉的节点。当挂掉的节点再次当选主节点,它将缺失部分已提交的日志。在这样场景下,按Raft协议,它将自己日志复制给其他节点,会将集群已经提交的日志给覆盖掉。这显然是错误的
其他协议解决这个问题的办法是,新当选的主节点会询问其他节点,和自己数据对比,确定出集群已提交数据,然后将缺失的数据同步过来。这个方案有明显缺陷,增加了集群恢复服务的时间(集群在选举阶段不可服务),并且增加了协议的复杂度。Raft解决的办法是,在选主逻辑中,对能够成为主的节点加以限制,确保选出的节点已定包含了集群已经提交的所有日志。如果新选出的主节点已经包含了集群所有提交的日志,那就不需要从和其他节点比对数据了。简化了流程,缩短了集群恢复服务的时间。
这里存在一个问题,加以这样限制之后,还能否选出主呢?答案是:只要仍然有超过半数节点存活,这样的主一定能够选出。因为已经提交的日志必然被集群中超过半数节点持久化,显然前一个主节点提交的最后一条日志也被集群中大部分节点持久化。当主节点挂掉后,集群中仍有大部分节点存活,那这存活的节点中一定存在一个节点包含了已经提交的日志了。
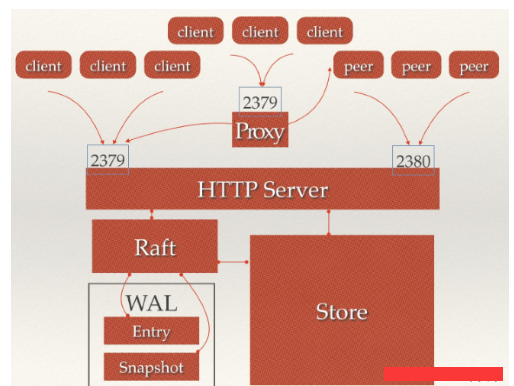
Etcd的代理节点(proxy)
Etcd针对Raft的角色模型进行了扩展,增加了Proxy角色。proxy模式的本职就是启一个HTTP代理服务器,把客户发到这个服务器的请求转发给别的 etcd 节点。
作为Proxy角色的节点不会参与Leader的选举,只是将所有接收到的用户查询和修改请求转发到任意一个Follower或者Leader节点上。
Proxy节点可以在启动Etcd的时候通过"--proxy on"参数指定。在使用了"节点自发现"服务的集群中,可以设置一个固定的"参选节点数目",超过这个数目的成员自动转换为Proxy节点。
一旦节点成为Proxy之后,便不再参与所有Leader选举和Raft状态变化。除非将这个节点重启并指定为成员的Follower节点
etcd 作为一个反向代理把客户的请求转发给可用的 etcd 集群。这样,你就可以在每一台机器都部署一个 Proxy 模式的 etcd 作为本地服务,如果这些 etcd Proxy 都能正常运行,那么你的服务发现必然是稳定可靠的。
完整的Etcd角色状态转换过程如下图:
kubernetes项目中,Etcd用来做什么,为什么选择它
etcd在kubernetes集群是用来存放数据并通知变动的。
Kubernetes中没有用到数据库,它把关键数据都存放在etcd中,这使kubernetes的整体结构变得非常简单。
在kubernetes中,数据是随时发生变化的,比如说用户提交了新任务、增加了新的Node、Node宕机了、容器死掉了等等,都会触发状态数据的变更。状态数据变更之后呢,Master上的kube-scheduler和kube-controller-manager,就会重新安排工作,它们的工作安排结果也是数据。这些变化,都需要及时地通知给每一个组件。etcd有一个特别好用的特性,可以调用它的api监听其中的数据,一旦数据发生变化了,就会收到通知。有了这个特性之后,kubernetes中的每个组件只需要监听etcd中数据,就可以知道自己应该做什么。kube-scheduler和kube-controller-manager呢,也只需要把最新的工作安排写入到etcd中就可以了,不用自己费心去逐个通知了
试想一下,如果没有etcd,那么要怎样做?这里的本质是:数据的传递有两种方式,一种是消息的方式,比如说NodeA有了新的任务,Master直接给NodeA发一个消息,中间不经过任何人;一种是轮询的方式,大家都把数据写到同一个地方,每个人自觉地盯着看,及时发现变化。前者演化出rabbitmq这样的消息队列系统,后者演化出一些有订阅功能的分布式系统。
第一种方式的问题是,所有要通信的组件之间都要建立长连接,并且要处理各种异常情况,比例如连接断开、数据发送失败等。不过有了消息队列(message queue)这样的中间件之后,问题就简单多了,组件都和mq建立连接即可,将各种异常情况都在mq中处理。
那么为什么kubernetes没有选用mq而是选用etcd呢?mq和etcd是本质上完全不同的系统,mq的作用消息传递,不储存数据(消息积压不算储存,因为没有查询的功能),etcd是个分布式存储(它的设计目标是分布式锁,顺带有了存储功能),是一个带有订阅功能的key-value存储。如果使用mq,那么还需要引入数据库,在数据库中存放状态数据。
选择etcd还有一个好处,etcd使用raft协议实现一致性,它是一个分布式锁,可以用来做选举。如果在kubernetes中部署了多个kube-schdeuler,那么同一时刻只能有一个kube-scheduler在工作,否则各自安排各自的工作,就乱套了。怎样保证只有一个kube-schduler在工作呢?那就是前文说到的通过etcd选举出一个leader。
上面的介绍转发下面的文章:https://blog.51cto.com/13210651/2358716 感谢作者分享,为方便阅读重新复制了一遍
下面介绍集群的安装
环境
系统centos 7.6
etcd01 10.211.55.11
etcd02 10.211.55.12
etcd02 10.211.55.13
安装方式:
wget https://github.com/etcd-io/etcd/releases/download/v3.3.13/etcd-v3.3.13-linux-amd64.tar.gz
还有一种方式是通过系统YUM 安装
我这边用的是YUM 安装
yum install etcd -y
vim /etc/etcd/etcd.conf
ETCD_DATA_DIR="/data/etcd/"
ETCD_LISTEN_CLIENT_URLS="https://0.0.0.0:2379"
ETCD_NAME="etcd01"
ETCD_LISTEN_PEER_URLS="https://0.0.0.0:2380"
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://10.211.55.11:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://10.211.55.11:2379"
ETCD_INITIAL_CLUSTER="etcd01=https://10.211.55.11:2380,etcd02=https://10.211.55.12:2380,etcd03=https://10.211.55.13:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_CERT_FILE="/etc/ssl/kubernetes/kubernetes.pem"
ETCD_KEY_FILE="/etc/ssl/kubernetes/kubernetes-key.pem"
ETCD_TRUSTED_CA_FILE="/etc/ssl/kubernetes/ca.pem"
ETCD_PEER_CERT_FILE="/etc/ssl/kubernetes/kubernetes.pem"
ETCD_PEER_KEY_FILE="/etc/ssl/kubernetes/kubernetes.pem"
ETCD_PEER_TRUSTED_CA_FILE="/etc/ssl/kubernetes/ca.pem"
这里面涉及到证书,有相关文章介绍了,可以参考上一篇文章,这里不在多说了,证书统一放到/etc/ssl/kubernetes/下面
参数说明
--name
etcd集群中的节点名,这里可以随意,可区分且不重复就行
--listen-peer-urls
监听的用于节点之间通信的url,可监听多个,集群内部将通过这些url进行数据交互(如选举,数据同步等)
--initial-advertise-peer-urls
建议用于节点之间通信的url,节点间将以该值进行通信。
--listen-client-urls
监听的用于客户端通信的url,同样可以监听多个。
--advertise-client-urls
建议使用的客户端通信url,该值用于etcd代理或etcd成员与etcd节点通信。
--initial-cluster-token etcd-cluster-1
节点的token值,设置该值后集群将生成唯一id,并为每个节点也生成唯一id,当使用相同配置文件再启动一个集群时,只要该token值不一样,etcd集群就不会相互影响。
--initial-cluster
也就是集群中所有的initial-advertise-peer-urls 的合集
--initial-cluster-state new
新建集群的标志,初始化状态使用 new,建立之后改此值为 existing
修改服务启动脚本
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
EnvironmentFile=-/etc/etcd/etcd.conf
#将gomaxprocs设置为处理器数 go 程序的优化 GOMAXPROCS=$(nproc)
ExecStart=/bin/bash -c "GOMAXPROCS=$(nproc) /usr/bin/etcd \
--name=${ETCD_NAME} \
--listen-client-urls=${ETCD_LISTEN_CLIENT_URLS} \
--listen-peer-urls=${ETCD_LISTEN_PEER_URLS} \
--advertise-client-urls=${ETCD_ADVERTISE_CLIENT_URLS} \
--initial-advertise-peer-urls=${ETCD_INITIAL_ADVERTISE_PEER_URLS} \
--initial-cluster=${ETCD_INITIAL_CLUSTER} \
--initial-cluster-token=${ETCD_INITIAL_CLUSTER_TOKEN} \
--initial-cluster-state=new \
--client-cert-auth=true \
--cert-file=${ETCD_CERT_FILE} \
--key-file=${ETCD_KEY_FILE} \
--peer-cert-file=${ETCD_PEER_CERT_FILE} \
--peer-key-file=${ETCD_PEER_KEY_FILE}\
--trusted-ca-file=${ETCD_TRUSTED_CA_FILE} \
--peer-trusted-ca-file=${ETCD_PEER_TRUSTED_CA_FILE}"
User=etcd
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
注: 启动的时候注意给/data/etcd 赋予权限
chown etcd.etcd /data/etcd
systemctl daemon-reload
service etcd start
chkconfig etcd on
查看日志
tail -f /var/log/message
其他节点也是这种部署方式,唯一的区别是修改为本机IP ,和修改ETCD_NAME,上面配置文件红色部分就是需要修改的
全部启动成功以后,验证一下
etcdctl \
--ca-file=/etc/ssl/kuberneters/ca.pem --cert-file=/etc/ssl/kuberneters/kuberneters.pem --key-file=/etc/ssl/kuberneters/kuberneters-key.pem \
--endpoints="https://10.211.55.11:2379,https://10.211.55.12:2379,https://10.211.55.13:2379" member list
344a57bb34515764: name=etcd01 peerURLs=https://10.211.55.11:2380 clientURLs=https://10.211.55.11:2379 isLeader=true
f9c27963788aad6e: name=etcd02 peerURLs=https://10.211.55.12:2380 clientURLs=https://10.211.55.12:2379 isLeader=false
ff2f490dbe25f877: name=etcd03 peerURLs=https://10.211.55.13:2380 clientURLs=https://10.211.55.13:2379 isLeader=false
可以看到etc01 是leader
注:其实集群内部不用证书验证通信可以,可以对peerurls 只用http ,外部客户端用TSL 验证
新增加新的节点
etcdctl --ca-file=/etc/ssl/kubernetes/ca.pem --cert-file=/etc/ssl/kubernetes/kubernetes.pem --key-file=/etc/ssl/kubernetes/kubernetes-key.pem --endpoints="https://k8s-etcd1:2379" member add k8s-etcd4 http://k8s-etcd4:2380
然后去新的节点配置

新增加节点的conf文件注意 ETCD_INITIAL_CLUSTER_STATE="existing"
启动etcd 即可观察
etcdctl --ca-file=/etc/ssl/kubernetes/ca.pem --cert-file=/etc/ssl/kubernetes/kubernetes.pem --key-file=/etc/ssl/kubernetes/kubernetes-key.pem --endpoints="https://k8s-etcd1:2379" member list
etcd升级遇到的问题
1 conflicting environment variable "ETCD_NAME" is shadowed by corresponding command-line flag (either unset environment variable or disable flag)
原因:ETCD3.4版本会自动读取环境变量的参数,所以EnvironmentFile文件中有的参数,不需要再次在ExecStart启动参数中添加,二选一,如同时配置,会触发以下类似报错
etcd: conflicting environment variable "ETCD_NAME" is shadowed by corresponding command-line flag (either unset environment variable or disable flag)
解决:剔除ExecStart中和配置文件重复的内容即可
2 cannot access data directory: directory "/application/kubernetes/data/","drwxr-xr-x" exist without desired file permission "-rwx------".
解决:将权限设置为700即可
3、Failed at step CHDIR spawning /usr/bin/etcd: No such file or directory
原因:etcd.service服务配置文件中设置的工作目录WorkingDirectory=/var/lib/etcd/必须存在,否则会报以上错误
Etcd v3.3 升级到 v3.4
flannel 使用 v0.10.0 版本
遇到的问题
Etcd 需要升级到 v3.4.7 版本,从 v3.3.9 直接升级到 v3.4.7 是没有问题的。但升级完成后,在查看 flannel 日志时,发现日志不断报 E0714 14:49:48.309007 2887 main.go:349] Couldn't fetch network config: client: response is invalid json. The endpoint is probably not valid etcd cluster endpoint. 错误。
刚开始以为是 flannel 版本过低导致,后面把 flannel 升级到最新版本 v0.12.0,但是问题还是一样。
问题原因
后面仔细通过排查,发现是连接不上 Etcd,当时很疑惑 Etce 连接不上,可 kube-apiserver 连接是正常的,后面才想起来,kube-apiserver 使用 Etcd v3接口,而 flannel 使用 v2接口。
怀疑在升级 Etcd 时默认没有开启 v2接口。最后查阅官方 Etcd v3.4 发布说明,从 3.4 版本开始,默认已经关闭 v2 接口协议,才导致上面报错。
解决方法
直接在 Etcd 启动参数添加 --enable-v2
etcd2和etcd3是不兼容的,两者的api参数也不一样,详细请查看 etcdctl -h 。
可以使用api2 和 api3 写入 etcd3 数据,但是需要注意,使用不同的api版本写入数据需要使用相应的api版本读取数据。
api 2 使用方法
ETCDCTL_API=2 etcdctl ls /
api 3 使用方法
ETCDCTL_API=3 etcdctl get /
修改flaneld 为host-gw 模式 因为flanneld 用的是v2版本 所以需要切换到V2 版本设置
export ETCDCTL_API=2
etcdctl --ca-file=/etc/ssl/kubernetes/ca.pem --cert-file=/etc/ssl/kubernetes/kubernetes.pem --key-file=/etc/ssl/kubernetes/kubernetes-key.pem --endpoints="https://k8s-etcd1:2379" set /coreos.com/network/config '{ "Network": "172.17.0.0/16", "Backend": {"Type": "host-gw"}}'
etcd 的备份和恢复
https://www.imooc.com/article/275606
下面是我们生产环境中的备份脚本, V2 和V3 都备份
#!/bin/bash
date_time=`date +%Y%m%d`
function etcd_backup(){
ETCDCTL_API=2 etcdctl --ca-file=/etc/ssl/kubernetes/ca.pem --cert-file=/etc/ssl/kubernetes/kubernetes.pem --key-file=/etc/ssl/kubernetes/kubernetes-key.pem --endpoints="https://k8s-etcd1:2379" backup --data-dir /data/etcd --backup-dir /data/tmp/ &> /dev/null
ETCDCTL_API=3 etcdctl --cacert=/etc/ssl/kubernetes/ca.pem --cert=/etc/ssl/kubernetes/kubernetes.pem --key=/etc/ssl/kubernetes/kubernetes-key.pem --endpoints="https://k8s-etcd1:2379" snapshot save /data/tmp/v3 &>/dev/null
tar cvzf etcd-${date_time}.tar.gz * &> /dev/null
}
function sendmsg() {
sign=`echo -n "backup${msg}zcD3xseDxJvvevvv"|md5sum|cut -d ' ' -f1`
curl "http://ctu.xxx.com/alarm/weixin?from=backup&msg=${msg}&sign=${sign}"
}
function ftp_init(){
printf "set ftp:passive-mode on
set net:max-retries 2
set net:reconnect-interval-base 10
set net:reconnect-interval-max 10
set net:reconnect-interval-multiplier 2
set net:limit-rate 8000000:8000000" > ~/.lftprc
lftp -e "put etcd-${date_time}.tar.gz;exit" ftp://ftp:[email protected]/etcd/ &>/dev/null
if [ $? -ne 0 ]
then
msg="etcd lftp put fail"
sendmsg
fi
}
mkdir /data/tmp && cd /data/tmp
ftp_init
etcd_backup
if [ $? -ne 0 ]
then
msg="etcd backup fail"
sendmsg
fi
rm -rf /data/tmp
ETCDCTL_API=3 etcdctl --cacert=/etc/ssl/kubernetes/ca.pem --cert=/etc/ssl/kubernetes/kubernetes.pem --key=/etc/ssl/kubernetes/kubernetes-key.pem --endpoints="https://k8s-etcd1:2379" snapshot restore etcbackup -data-dir /data/etcd
版本2 的数据直接拷贝目录,重新启动集群就可以了
好的etcd 参考文章
http://www.xuyasong.com/?p=1983