记一次k8s集群中etcd集群恢复处理
现象:
突然我们的kuboard界面访问的时候,一直卡在了登录页,由于是在k8s集群中部署的,于是通过命令行终端登录到master节点上,查看集群中的pod状态,发现竟然k8s集群都不能访问了,于是首先通过kubectl get cs 查看了,发现是etcd集群故障。
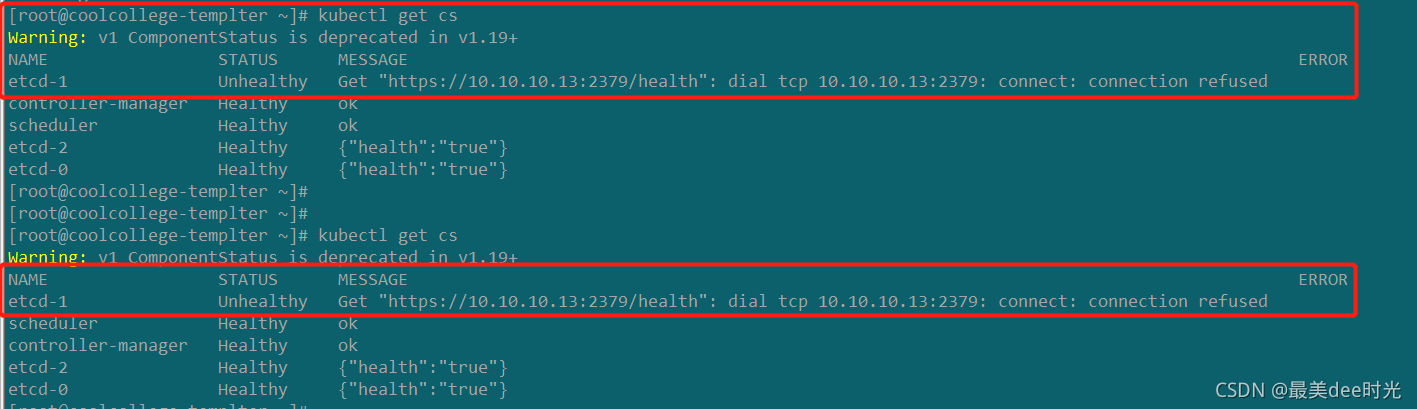
排查:
step1:先登录etcd-1节点(即etcd的leader节点),通过配置文件查看,集群的三个节点分别是10.10.10.11,10.10.10.12,10.10.10.13;
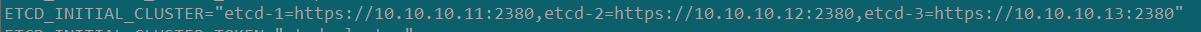
step2:然而在etcd-3(10.10.10.13)上没有/opt/etcd这个目录(意外删除了),从而导致机器在重启(断电重启过)后找不到启动命令和配置文件,所以一直处理故障状态,相当于一直以来etcd都是以两个节点在工作,这次leader挂了导致etcd集群无法选主直接服务故障了。
step3:leader节点挂掉的原因是因为研发在部署pod的时候将某些pod直接固定在了leader这个节点上导致机器卡死了,将etcd服务挤下线了。
处理:
step1:将正常的etcd节点的配置文件、启动命令拷贝过去
step2:在etcd集群中剔除掉故障节点,重新加入集群
具体操作:
step1:etcd-3节点上拷贝配置文件和启动命令,暂不启动(etcd-3节点上操作)
step2:将etcd-3故障节点剔除集群(etcd-1节点上操作)
/opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://10.10.10.11:2379,https://10.10.10.12:2379,https://10.10.10.13:2379" member list

/opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://10.10.10.11:2379,https://10.10.10.12:2379,https://10.10.10.13:2379" member remove 1ce8e50bd8e3c94b

step3:删除点etcd-3原先存在的数据(etcd-3节点上操作
rm -rf /var/lib/etcd/default.etcd/member/
step4:将etcd-3节点加入到集群(etcd-1节点上操作)
/opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://10.10.10.11:2379,https://10.10.10.12:2379,https://10.10.10.13:2379" member add etcd-3 --peer-urls=https://10.10.10.13:2380

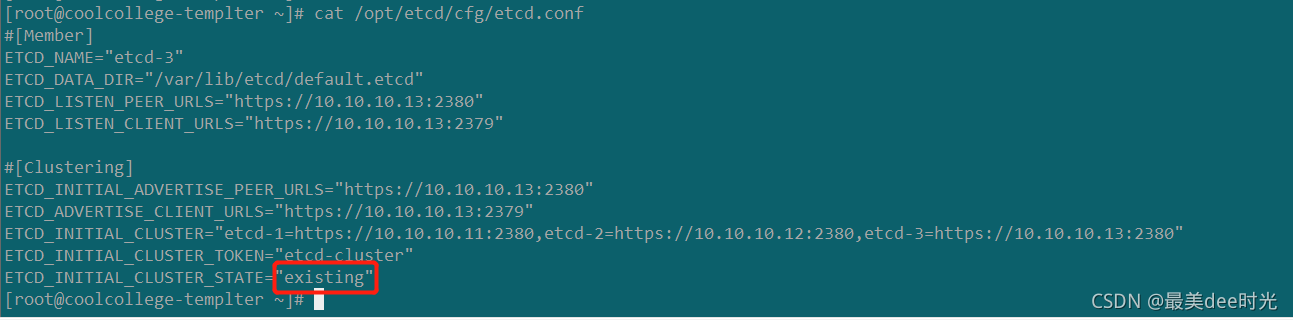
step5:修改etcd-3的配置文件
根据step4中提示的配置,修改即可
step6:启动etcd
systemctl start etcd
step7:再次查看

