本篇目录链接
背景:ECS机器重启后故障后,无法正常开机,集群由原先的3主3从变成了双主3从。

现象:k8s集群的新master节点无法加入到集群中,提示如下:
[control-plane] Creating static Pod manifest for
“kube-controller-manager” W1110 17:36:52.162178 17976
manifests.go:225] the default kube-apiserver authorization-mode is
“Node,RBAC”; using “Node,RBAC” [control-plane] Creating static Pod
manifest for “kube-scheduler” W1110 17:36:52.162925 17976
manifests.go:225] the default kube-apiserver authorization-mode is
“Node,RBAC”; using “Node,RBAC” [check-etcd] Checking that the etcd
cluster is healthy error execution phase check-etcd: etcd cluster is
not healthy: failed to dial endpoint https://10.7.54.135:2379 with
maintenance client: context deadline exceeded To see the stack trace
of this error execute with --v=5 or higher
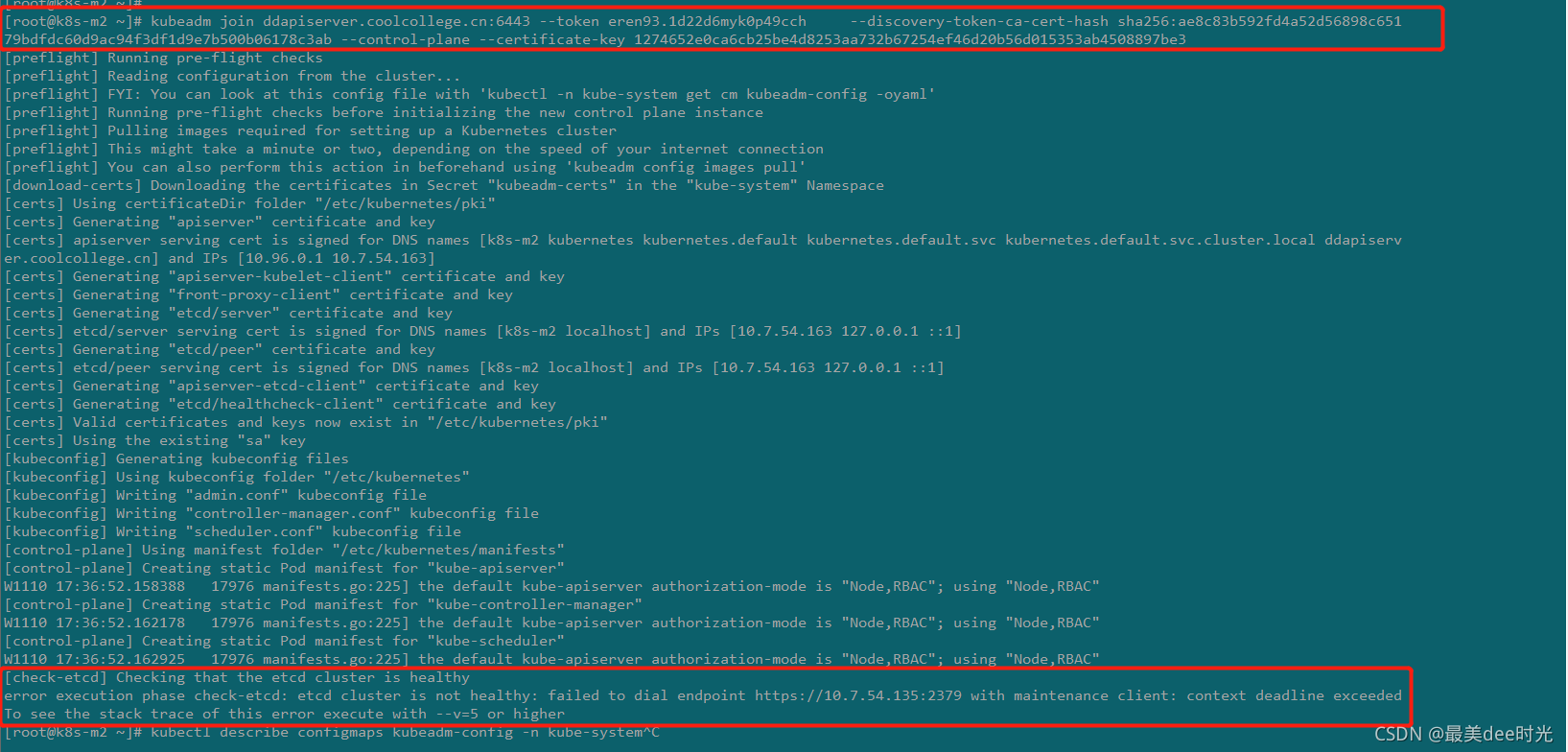
原因:通过报错可以集群在进行节点加入时,检查etcd集群,但是10.7.54.135这台集群为故障主机,而由于之前在集群正常时该机器上有etcd的pod,当机器故障后,集群无法检测到该节点上的etcd服务,所以报错。
处理办法:
由于10.7.54.135已经无法开机,但之前的etcd的信息都在etcd集群中,所以我们要做的是将故障节点的地址信息从etcd集群中剔除掉,然后重新做集群加入的操作即可。
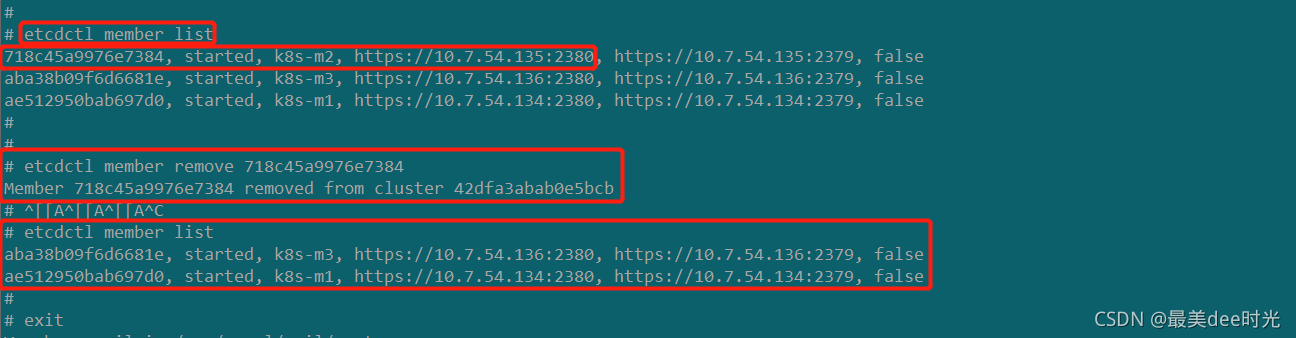
step1:登录任意正常的etcd的pod中,剔除故障节点的地址信息。
> kubectl exec -it etcd-k8s-m1 sh -n kube-system #进入到正常的etcd pod中,执行以下命令
> ls -l /etc/kubernetes/pki/etcd #查看证书
total 32
-rw-r--r-- 1 root root 1017 Aug 26 03:15 ca.crt
-rw------- 1 root root 1679 Aug 26 03:15 ca.key
-rw-r--r-- 1 root root 1094 Aug 26 03:15 healthcheck-client.crt
-rw------- 1 root root 1675 Aug 26 03:15 healthcheck-client.key
-rw-r--r-- 1 root root 1127 Aug 26 03:15 peer.crt
-rw------- 1 root root 1675 Aug 26 03:15 peer.key
-rw-r--r-- 1 root root 1127 Aug 26 03:15 server.crt
-rw------- 1 root root 1679 Aug 26 03:15 server.key
> export ETCDCTL_API=3
> alias etcdctl='etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key' #创建快捷命令
> etcdctl member list #查看etcd的节点
718c45a9976e7384, started, k8s-m2, https://10.7.54.135:2380, https://10.7.54.135:2379, false
aba38b09f6d6681e, started, k8s-m3, https://10.7.54.136:2380, https://10.7.54.136:2379, false
ae512950bab697d0, started, k8s-m1, https://10.7.54.134:2380, https://10.7.54.134:2379, false
> etcdctl member remove 718c45a9976e7384 #删除etcd集群中的故障节点
Member 718c45a9976e7384 removed from cluster 42dfa3abab0e5bcb
# ^[[A^[[A^[[A^C
> etcdctl member list #再次查看etcd的节点
aba38b09f6d6681e, started, k8s-m3, https://10.7.54.136:2380, https://10.7.54.136:2379, false
ae512950bab697d0, started, k8s-m1, https://10.7.54.134:2380, https://10.7.54.134:2379, false
#
# exit #退出
step2:重置待加入master的节点,再次加入集群。
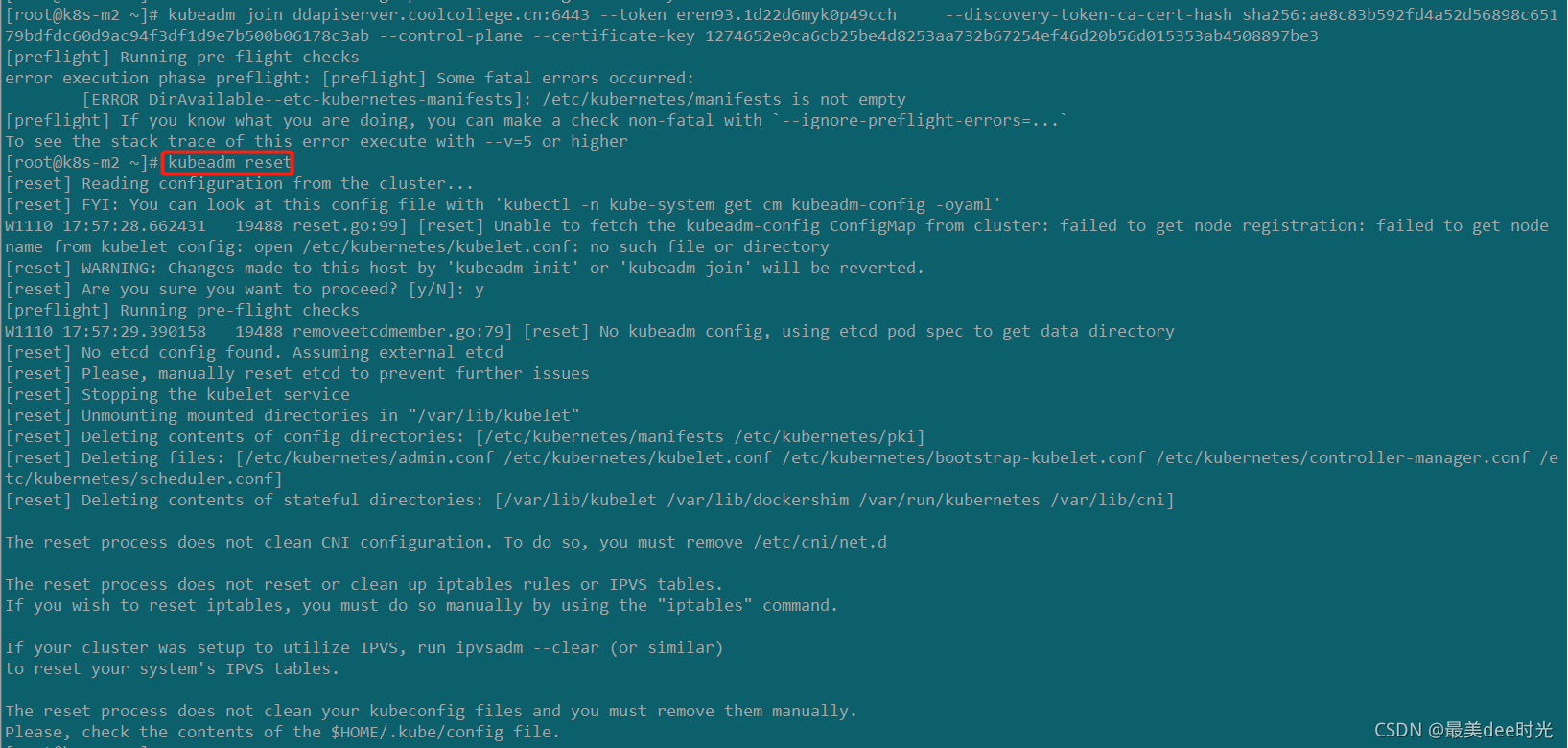
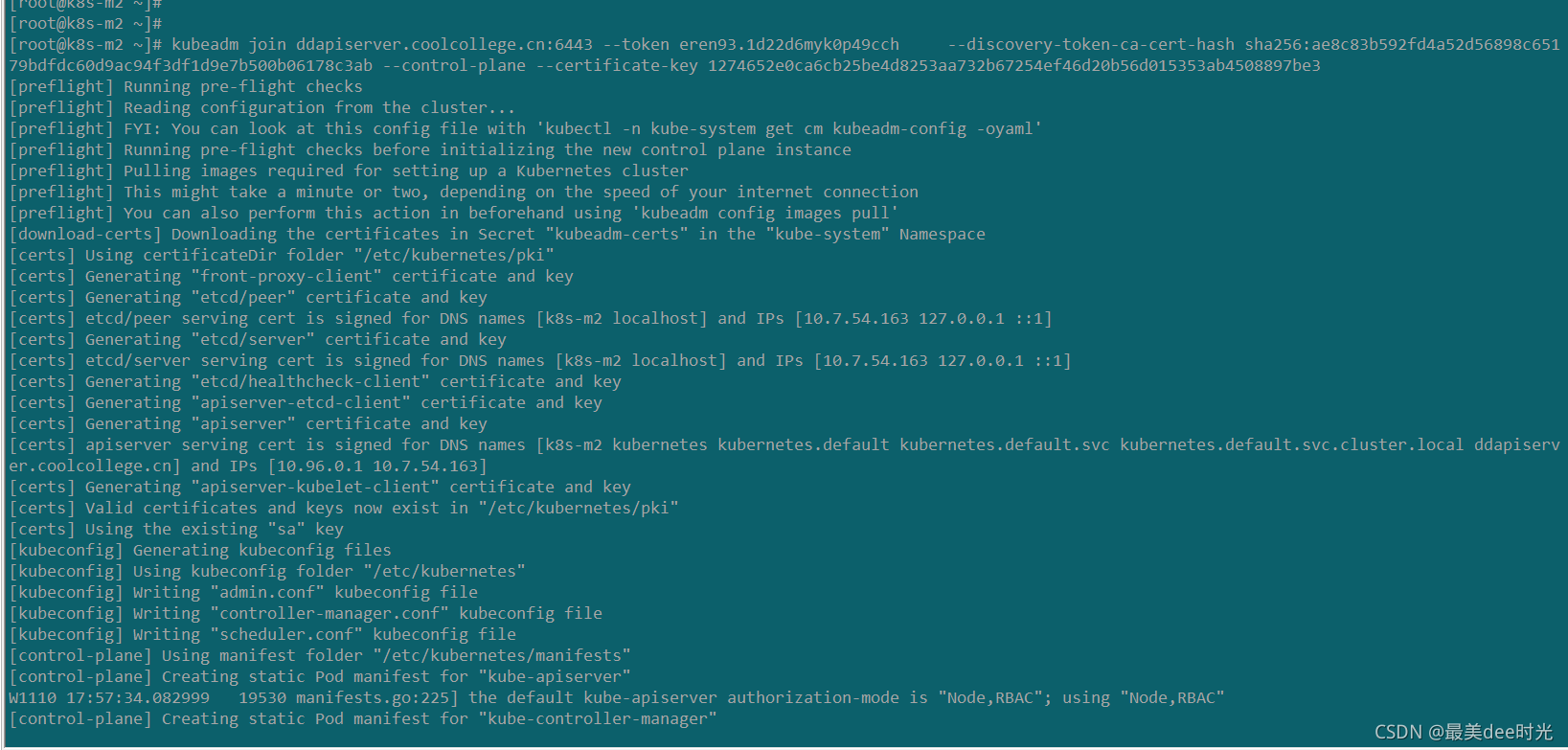
kubeadm join ddapiserver.coolcollege.cn:6443 --token
eren93.1d22d6myk0p49cch --discovery-token-ca-cert-hash
sha256:ae8c83b592fd4a52d56898c65179bdfdc60d9ac94f3df1d9e7b500b06178c3ab
–control-plane --certificate-key 1274652e0ca6cb25be4d8253aa732b67254ef46d20b56d015353ab4508897be3
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[preflight] Running pre-flight checks before initializing the new control plane instance
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[download-certs] Downloading the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-m2 localhost] and IPs [10.7.54.163 127.0.0.1 ::1]
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-m2 localhost] and IPs [10.7.54.163 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-m2 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local ddapiserver.coolcollege.cn] and IPs [10.96.0.1 10.7.54.163]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[certs] Using the existing "sa" key
[kubeconfig] Generating kubeconfig files
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
W1110 17:57:34.082999 19530 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
W1110 17:57:34.086698 19530 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[control-plane] Creating static Pod manifest for "kube-scheduler"
W1110 17:57:34.087262 19530 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[check-etcd] Checking that the etcd cluster is healthy
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.18" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[etcd] Announced new etcd member joining to the existing etcd cluster
[etcd] Creating static Pod manifest for "etcd"
[etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s
{
"level":"warn","ts":"2021-11-10T17:57:50.967+0800","caller":"clientv3/retry_interceptor.go:61","msg":"retrying of unary invoker failed","target":"passthrough:///https://10.7.54.163:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[mark-control-plane] Marking the node k8s-m2 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node k8s-m2 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane (master) label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.
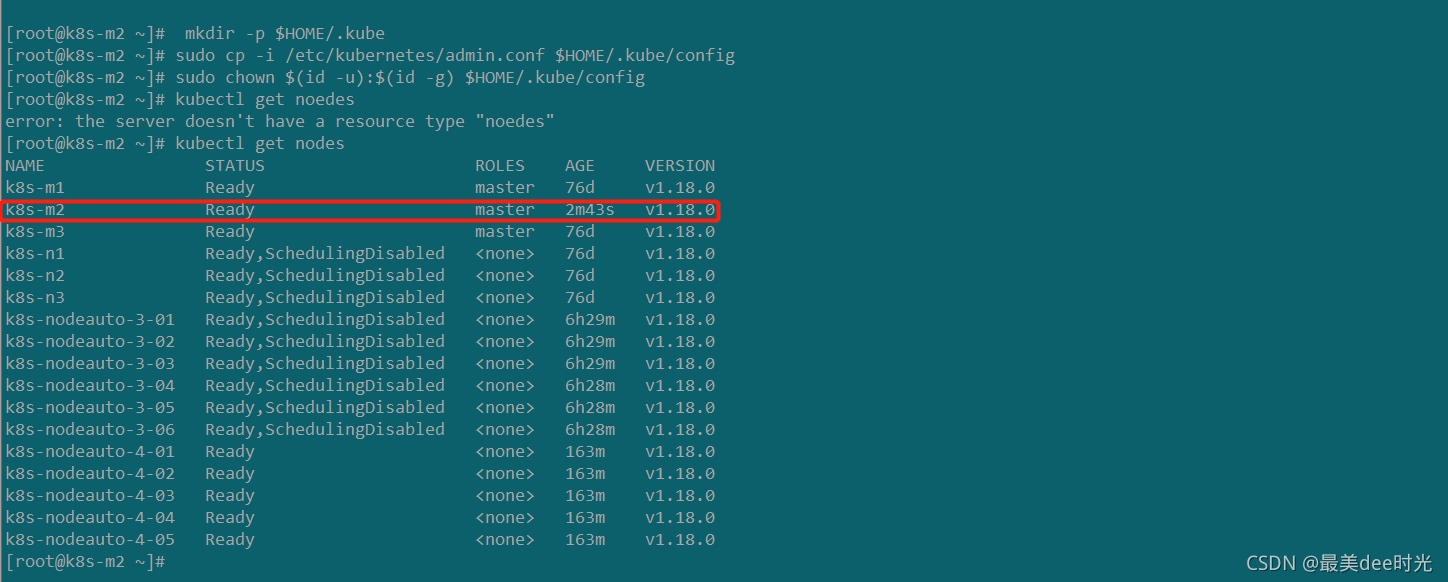
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.