前言
该笔记主要是基于DIP理论➕openCV实现,学习该笔记首先要确保通读DIP理论,并由自己的话描述相关知识,并且掌握openCV中的相关算子
这里主要是基于VS2017/2019来实现openCV3.4.10版本的操作
图像处理分为传统图像处理和基于深度学习的图像处理,当某章某节涉及到深度学习时,我会在标题后追加(深度学习)以示区分.
第一章 特征提取
在特征提取上,传统的图像处理都是自行设计提取固定特征的算子,在深度学习上主要是利用CNN网络来广泛的提取图像的特征.在本章中主要介绍的是传统图像处理的经典的特征描述和提取方法,例如Haar、LBP、SIFT、HOG和DPM特征,其中的DPM特征是传统DIP在特征提取领域的天花板.
图像的浅层特征主要是颜色、纹理和形状
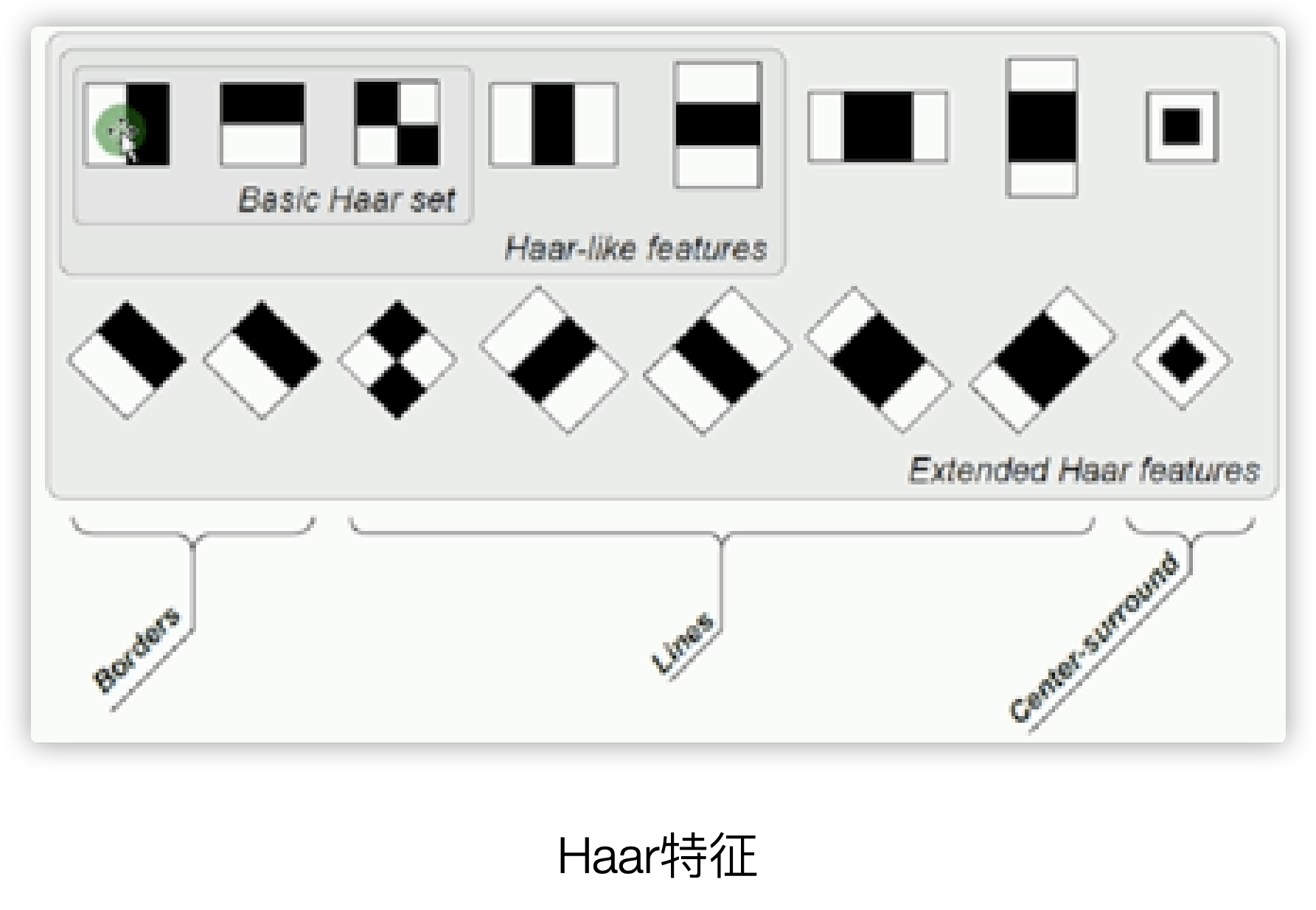
第一节 Haar特征(黑白色块)
Haar特征是按照黑白像素区域,每一个黑色或白色区域都是一个包含了多个像素的像素块,像素块之间的差值决定了哪些块之间存在哪种类型的边缘,比如下图的第一个是描述的垂直边缘,第二个则表示水平边缘.
一个矩形Haar特征定义了矩形中几个区域像素和的差值,可以是任意尺寸和任意位置,这个差值表明了图像的特定区域的某些特征
Haar特征往往应用在人脸识别的场景
第二节 LBP特征(局部二值模式)
LBP是Local Binary Pattern局部二值模式的缩写,LBP特征描述的是图像的局部特征,LBP特征的特点是旋转不变性和灰度不变性
常用在人脸识别和目标检测上

LBP的旋转不变性和灰度不变性,往往可以对光照,旋转等具有较强的鲁棒性
2.1 原始LBP特征
在一张图片或一个感兴趣区域中,其LBP特征有如下描述步骤:
- 在灰度图片中,在3x3的像素邻域内,以中心像素作为阈值T,将中心点的8邻域像素的8个数值,分别和T进行比较,若大于T则置1,小于则0
- 把第一步的8个比较结果,依次排成一行,形成一个8位二进制序列,并转换成十进制数值
- 十进制结果即该中心像素的LBP特征值
显然,一个像素点,可以生成2^8=256种LBP特征值
原始LBP由于采用固定邻域像素点作为比较对象,所以面对尺寸变换时往往失去鲁棒性,更不要谈旋转不变性了

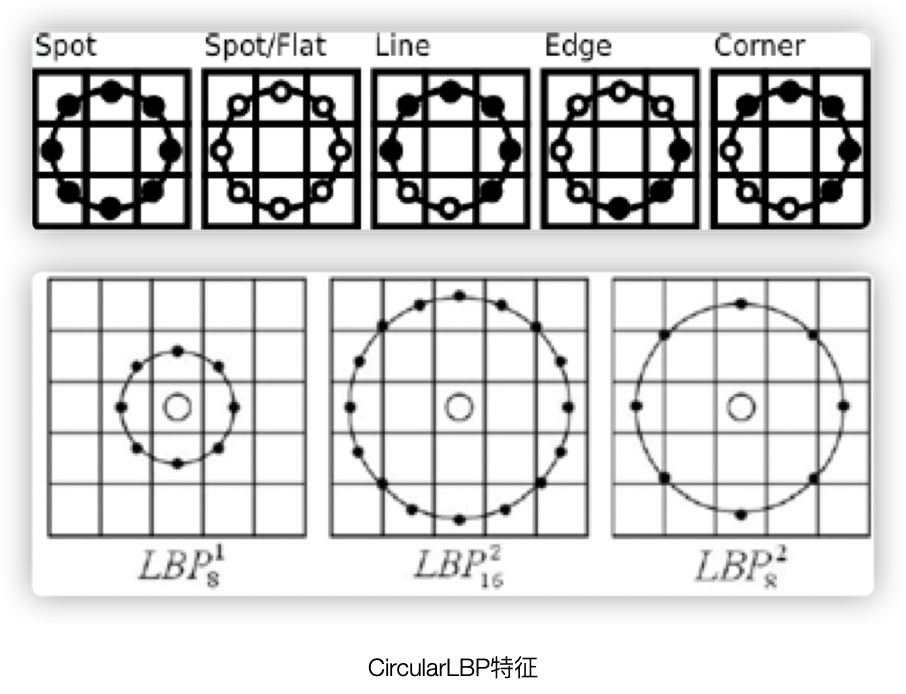
2.2 CircularLBP特征
原始LBP没有旋转不变性和尺度不变性,因此给予改进.
在CircularLBP特征中,保留了LBP的基本思想,具有如下描述步骤:
- 在灰度图片中,以某个像素点作为中心点,以R为半径画圆,圆的周长覆盖到的像素点,就是待和中心点比较的像素点
- 若圆周长覆盖的像素点不在图像内,就要采用差值算法,一般是双线性差值
- 对于CircularLBP所述的圆圈覆盖的邻域像素,按照一定步长进行角度旋转,得到一系列的序列(下图白点为1黑点为0),转换成LBP值,则每个像素点会有多个LBP值
- 取上述LBP值中最小的值作为该中心像素点的CircularLBP特征值

第三节 SIFT特征(尺度旋转不变)
SIFT是尺度旋转不变的缩写,主要用于局部特征的描述提取,SIFT描述子对特征在图片中受到旋转、尺度变化、放缩和亮度等因素变化时具有较强的鲁棒性
2.3.1 SIFT特征提取方法
首先直接给出SIFT特征提取的流程图,然后对其逐个分析

建立尺度空间主要分成两步,第一步是对图片进行Gaussion金字塔操作,正常的pyramid每做一次下采样就是1层,但这里叫做一组,对每一组的图片,按照模糊尺度进行分层,第二步就是把每一组中上下层图像进行像素差分操作,得到高斯差分金字塔DOG金字塔

在流程图中,第二个大步骤就是寻找极值点,在每一个octave中,寻找每个像素的3x3x3邻域的26个邻域像素点,找出其max或min,该极值点暂定关键点
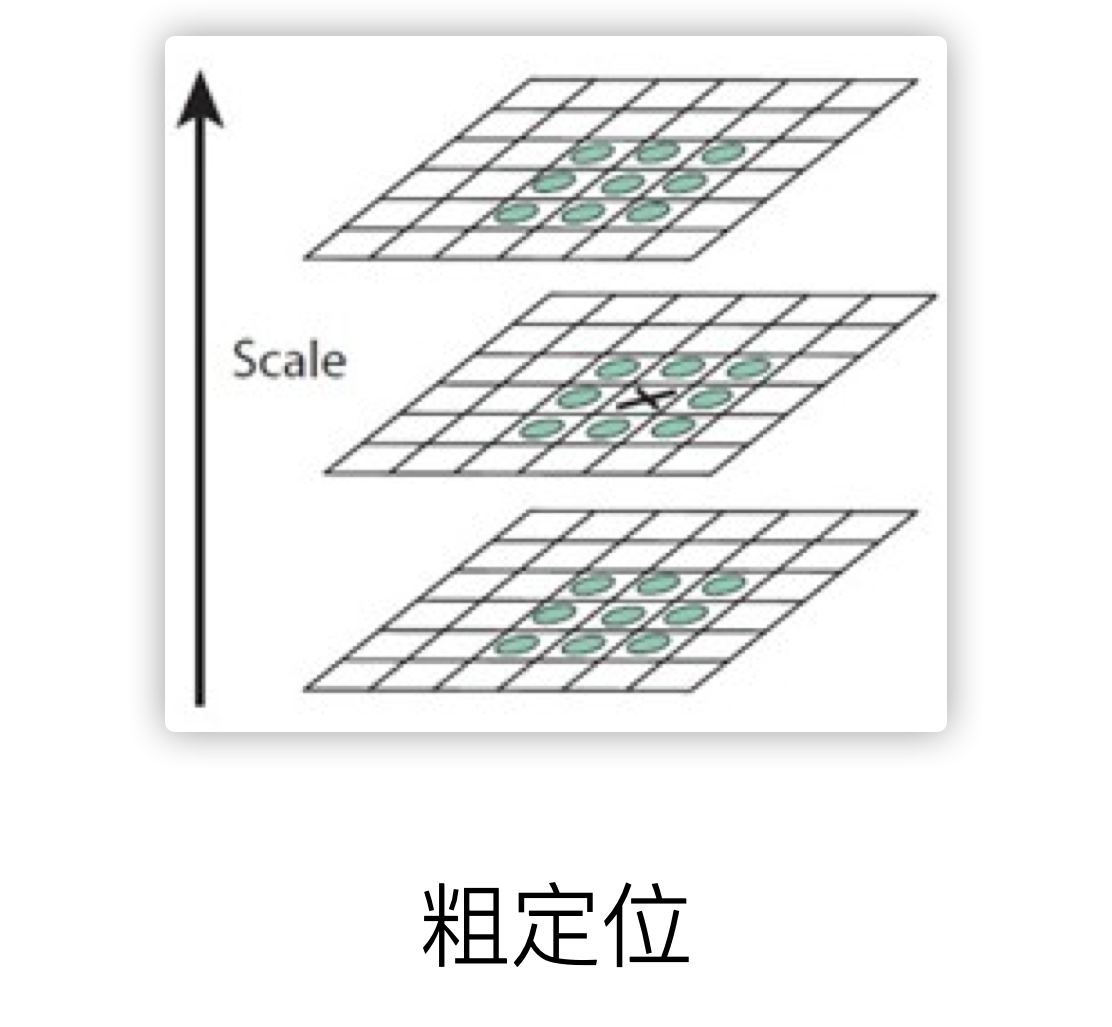
第三个大步骤就是对上述的粗定位进行精确定位,这里主要是采用的亚像素级别的差值处理,获得精确的关键点位置信息
第四步则是对关键点进行方向的初步分配,这正是旋转不变性的基础,首先把每个关键点以3.05σ为半径画圆,圆形面积覆盖的全部像素点,计算对应的梯度大小得到梯度方向,统计该区域的0-360°的梯度方向直方图,并把360°划分成36个bins每个bin代表10°,直方图峰值所在方向即该关键点主方向,保留峰值80%所在角度为该关键点辅助方向.
最后一步就是最重要的,即对关键点进行精准方向校准,此时已经获得了精准位置信息+尺度信息+粗方向信息,因此需要对方向进行精准修正,方法步骤如下:
- 增强旋转不变性,以关键点为中心,把邻域像素内坐标轴旋转该关键点主方向角度,获得新坐标
- 在新坐标中,以关键点为中心,获取16x16像素的窗口
- 在窗口中以4x4个像素为1个cell,均分成4x4个cell
- 统计每个cell中的16个像素的梯度直方图,360°按45°分成8个bins,即每个cell可得到8个特征信息
- 该关键点,16x16像素邻域范围内,共得到16x8=128个梯度特征信息,即每个关键点会产生128维的SIFT特征向量
2.3.2 SIFT特征在openCV中的实现方法
在openCV中依然采用简单算子api来实现
cv::xfeatures2d::SIFT::create(int nfeatures = 0, 关键点总个数
int nOctaveLayers =3, octave层数
double contrastThreshold = 0.04, 对比度阈值
double edgeThreshold= 10, 边缘阈值
double sigma=1.6)高斯模糊因子σ第四节 HOG特征(梯度直方图)
HOG是Histograms of Oriented Gradients梯度方向直方图的缩写
HOG在SVM中的应用在传统图像处理中的行人检测领域取得了极大的成功,可以说是传统行人检测的基石.
一般情况, 在行人检测中由于每个人的内在特征存在明显的差异,因此需要一个能够全面描述人体特征的描述子进行描述,而HOG正是基于这个基本思想设计的.
HOG算子认为局部目标的表象和形状,能够被gradient或者边缘的方向密度分布很好的描述(当然gradient是梯度,而梯度往往存在于边缘处)
HOG特征提取的过程就是绘制图像的梯度分布直方图,然后利用算法,把梯度直方图归一化处理,正是这种归一化算法,将会很有效的检测出哪里是边缘,经过标准化,梯度直方图会被压缩成一个特征向量,就是HOG特征描述子,该描述子保存了大量的边缘信息,最终作为SVM分类器的输入
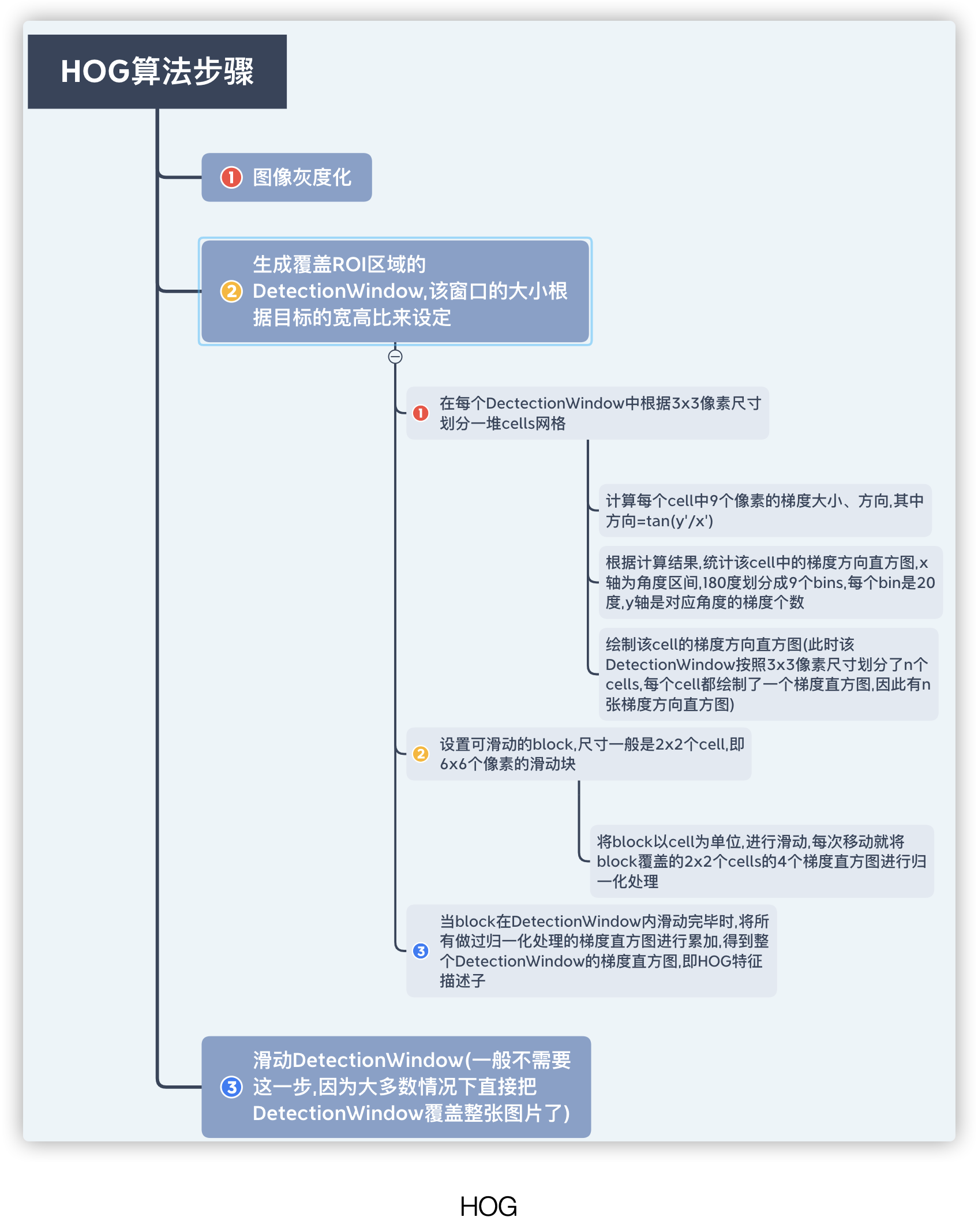
为了更好的理解HOG,用下图来描述HOG描述子的处理过程

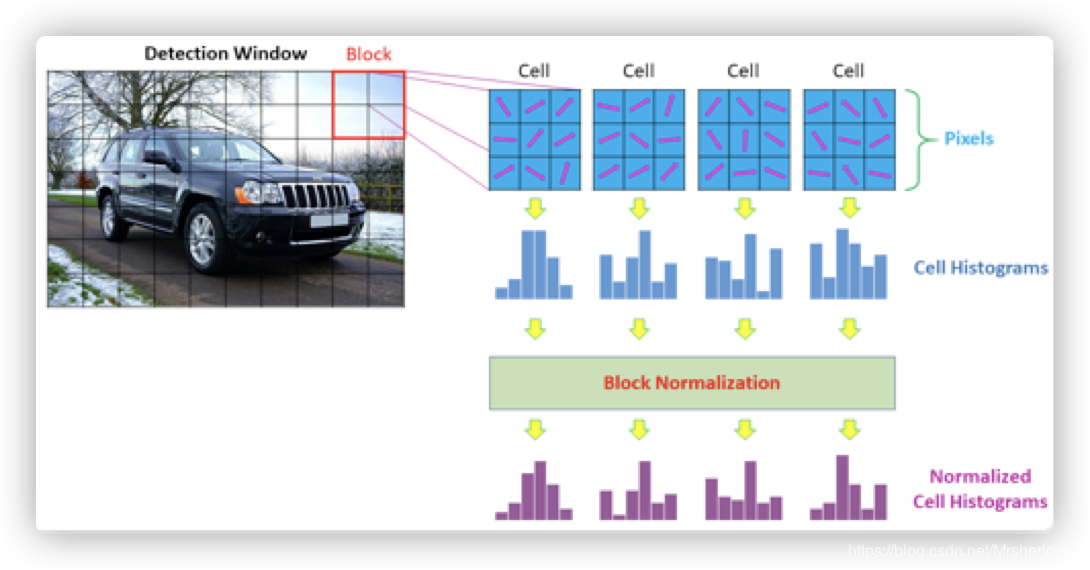
根据上图显示,一个HOG描述子的长度=block个数 ✖️ 一个block覆盖cell个数 ✖️ 每个cell的直方图中bins个数.
如果一幅图片中包含了多个DetectionWindow,那么一张图片中的HOG描述子的长度=窗口个数✖️一个HOG描述子长度
在openCV中,提供了关于HOG描述子的案例,比如下面的行人检测案例.在下面的案例中,HOGDescriptor作为HOG描述子的类,hog是类对象,该类的构造函数为默认构造函数.HOGDescriptor类存在一个svmDetector公共属性,他是用来配置HOG描述子输入给的SVM分类器的系数值的.
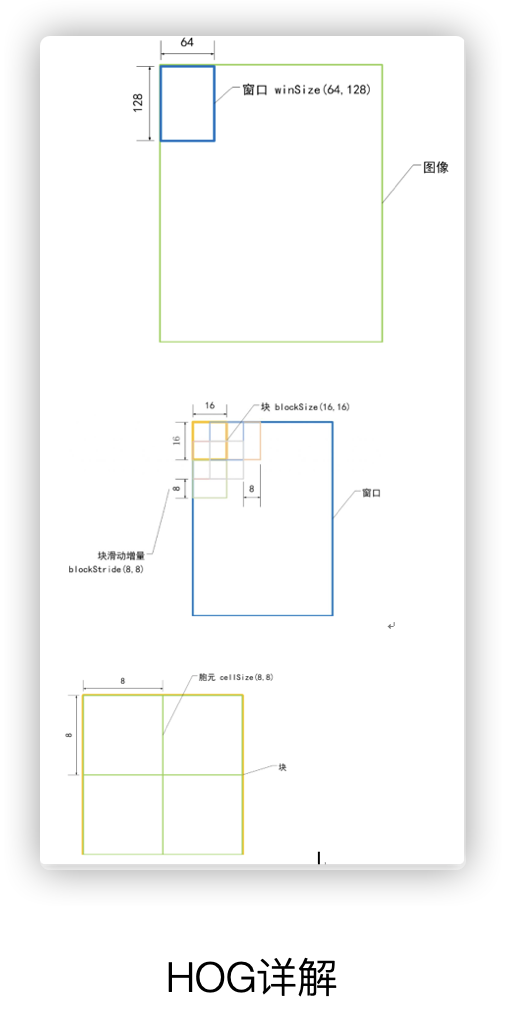
在上述的hog类对象中,默认构造一个64*128,的DetectionWindow,16*16的block,8*8的cell,且每个cell的HOG中含9个bins
更多关于HOGDescriptor类的描述详见:https://docs.opencv.org/3.4.10/d5/d33/structcv_1_1HOGDescriptor.html#ac0544de0ddd3d644531d2164695364d9
案例详解:
Mat gray;
Mat dst;
resize(src, dst, Size(64,128));
cvtColor(dst, gray, COLOR_BGR2GRAY);
HOGDescriptor detector(Size(64,128), Size(16,16), Size(8,8), Size(8,8), 9);
vector<float> descriptors;
vector<Point> locations;
detector.compute(gray, descriptors, Size(0,0),Size(0,0),locations);
cout<<“result number of HOG = “<<descriptors.size()<<endl;API介绍:
// HOG描述子
cv2.HOGDescriptor( win_size = (64, 128), //前5个最常用
block_size = (16, 16),
block_stride = (8, 8), //这个是块之间的x距离和y距离
cell_size = (8, 8),
nbins = 9,
win_sigma = DEFAULT_WIN_SIGMA,
threshold_L2hys = 0.2,
gamma_correction = true,
nlevels = DEFAULT_NLEVELS)
// 计算描述子数值类方法
HOGDescriptor::compute(image) //输入图像
virtual void cv::HOGDescriptor::compute
(
InputArray img,
std::vector< float > &descriptors,//输出HOG描述子
Size winStride = Size(), //窗口与窗口之间的距离
Size padding = Size(), //窗口的步长
const std::vector< Point > &locations = std::vector< Point >()d
)const
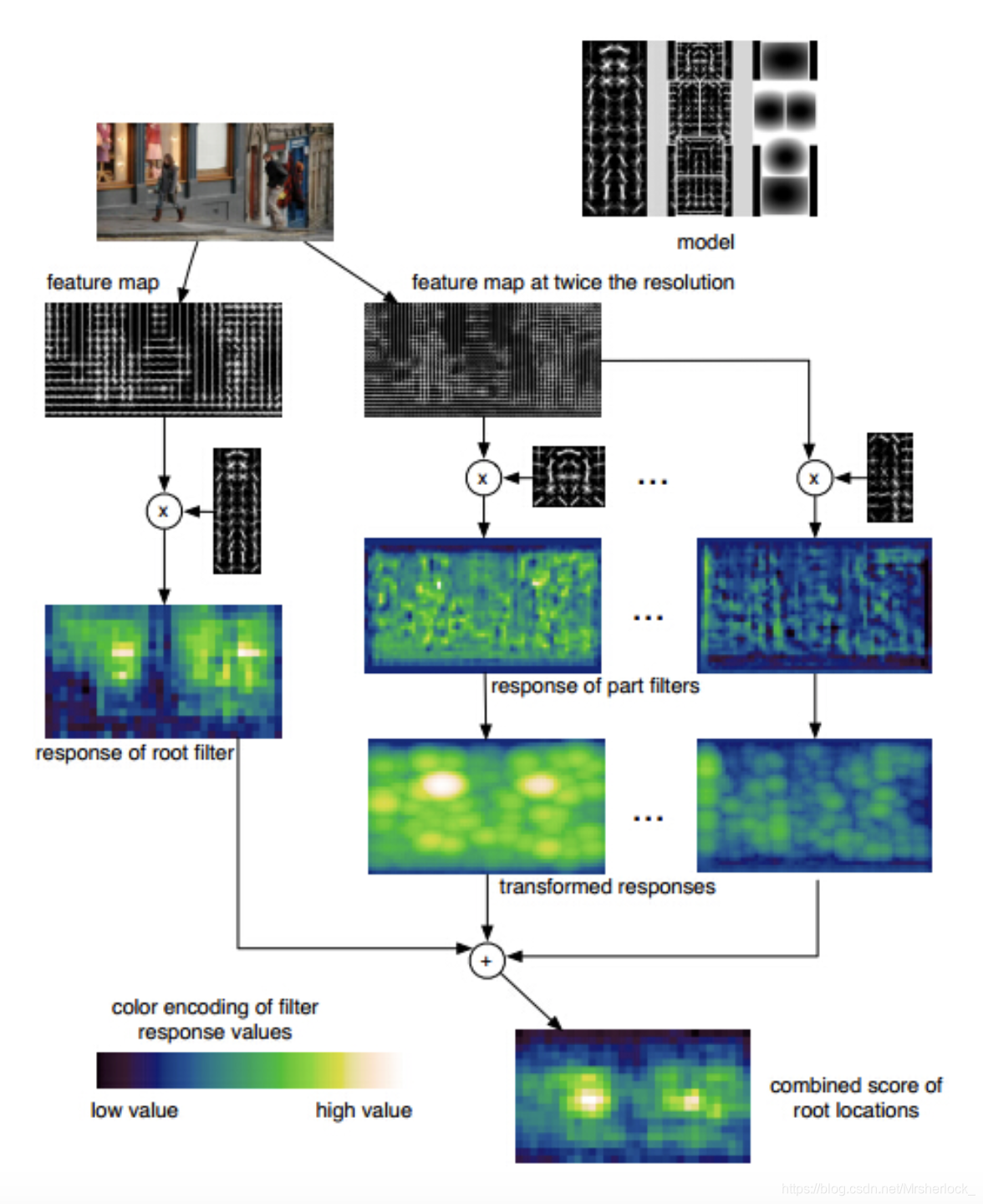
第五节 DPM特征(可形变部件模型)
DPM特征是Deformable Parts Model可形变部件模型,DPM是传统目标检测算法的天花板,是HOG特征检测算法的扩展与改进,由于HOG往往带来高纬度的特征向量,这些特征向量作为SVM分类器的输入,往往产生很大的计算量,HOG一般采用PCA主成分分析法降维,但DPM作为HOG算法的改进,采用了一种逼近PCA的降维方法.
首先规定前提,DPM把梯度方向根据180度和360度分成了有符号和无符号两类,其中有符号表示有正负符号,其0-360角度范围的梯度看成有方向的,分成18个bins,0-180的成为无方向的分成9个bins, 显然无路方向有无,每个bin的角度都是20度.

在对该流程的理解过程中或许有偏差,但是最终的结果是一样的,另一个理解角度是:
- 采用HOG的cell思想,每8✖️8个像素为一个cell,均分图片成多个cell,计算全部像素的梯度大小和方向,统计每个cell中所有像素的梯度直方图
- 对每个cell的4邻域的4个cell,即对角线上4个cell,如图1234(上图绿色为一个cell内部情况,黄色块为一个cell简笔画), 把该cell和4邻域的4个cell对应做归一化处理见下一步
- 中心cell和4邻域4个cell分别归一化处理步骤:
- 对于有符号梯度: 计算中心cell和第i个cell(i=1,2,3,4)的梯度方向直方图,在有符号的梯度方向直方图为18个bins,4个cell直方图累加得到18个bins即18个特征
- 对于无符号梯度:如图右侧,把上图橘色块即36个特征看成一个矩阵,进行行求和、列求和,共得到4+9=13个特征**
- 归一化后合计得到18+13=31个特征,即每个8✖️8像素的cell会产生一个31维的特征向量

DPM检测
DPM作为目标检测算法的天花板,有着自己的独特的检测流程,如下图所示: