什么是时间复杂度
时间复杂度是一个函数,它定性描述该算法的运行时间。
在软件开发中,时间复杂度就是用来方便开发者估计出程序运行的大致时间。
那么如何估计程序运行时间呢,通常会估算算法的操作单元数量来代表程序消耗的时间,这里默认CPU的每个单元运行消耗的时间都是相同的。
假设算法的问题规模为n,那么操作单元数量使用函数f(n)来表示,随着数据规模n的增大,算法执行时间的增长率和f(n)的增长率相同,这称作为算法的渐进时间复杂度,简称为时间复杂度,记为O(f(n))。
什么是大O
算法导论给出的解释是:大O是用来表示上界的,当用它作为算法的最坏情况运行时间的上限,就是对任意数据输入的运行时间的上界。
比如:对于插入排序来说,我们都说时间复杂度是O(n^ 2 )。输入数据的形式对程序运算时间有很大影响,在数据本来有序的情况下时间复杂度是O(n),但如果数据是逆序的话,时间复杂度就是O(n^2),也就是对于所有输入情况来说,最坏是O(n ^2)的时间复杂度,所以称插入排序的时间复杂度是O(n ^2)。
同理对于快排来说,都知道快排的时间复杂度是O(nlogn),但是当数据已经基本有序的情况下,快速排序的时间复杂度是O(n^2)的,所以严格意义上,快速排序的时间复杂度应该是O(n ^2)。但是我们依然说快速排序的时间复杂度是O(nlogn),这就是业内的一个默认规定,这里说的O代表的就是一般情况,而不是严格的上界。
我们主要关心的还是一般情况下的数据形式,面试中说的时间复杂度是多少指的都是一般情况。但是如果面试官和我们深入讨论一个算法的实现及其性能的时候,就要时刻想着数据用例不一样,时间复杂度也是不同的,这一点是一定要注意的。
不同数据规模的差异
如下图中可以看出不同算法的时间复杂度在不同数据规模下的差异:
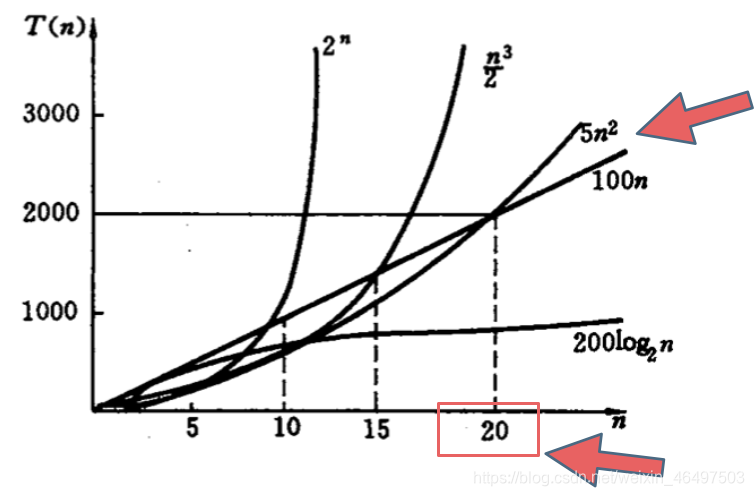
在决定使用哪些算法时,不是时间复杂度越低越好(因为简化后的时间复杂度忽略了常数项等等),要考虑数据规模,如果数据规模很小,那么甚至用时间复杂度为O(n^2)的算法要比用时间复杂度为O(n)的算法更合适。
比如上图中的O(5n^2)和O(100n),在n为20之前很明显O(5n ^2)是更优的,所花费的时间也是最少的。
那为什么要忽略常数项系数呢?这里有涉及到大O的定义:因为大O就是数据量级突破一个点且数据量级非常大的情况下所表现出来的时间复杂度,这个数据量也就是常数项系数已经不起决定性作用的数据量。例如上图20的那个点,n只要大于20,常数项系数已经不起决定性作用了。
所以我们说的时间复杂度都是忽略常数项系数的,因为一般情况下都是默认数据规模足够的大,基于这样的事实,给出算法时间复杂度的一个排行如下所示:
O(1) < O(logn) < O(n) < O(n^2) < O(n ^3) < O(2 ^n)
但是也要注意大常数,如果这个常数非常大,比如10^9等,那么常数就是不得不考虑的因素了。
O(logn)中的log是以什么为底
平时说算法的时间复杂度是log的,那么一定是log以2为底n的对数吗?
其实不然,也可以是以10为底n的对数,也可以是以20为底n的对数。但我们统一说logn,也就是忽略底数的描述。
为什么可以这么做呢?如下图所示:

假如有两个算法的时间复杂度,分别是 log以2为底n的对数 和 log以10为底n的对数,那么 以2为底n的对数 = 以2为底10的对数 * 以10为底n的对数。而以2为底10的对数是一个常数,可以忽略。
抽象一下就是在时间复杂度的计算过程中,log以i为底n的对数等于log以j为底n的对数,所以忽略了i,直接说是logn
递归算法的时间复杂度
递归算法的时间复杂度本质上是要看:递归的次数 * 每次递归的操作次数。
时间复杂度汇总
猜你喜欢
转载自blog.csdn.net/weixin_46497503/article/details/111900479
今日推荐
周排行