绪论
数据结构主要包括数据的逻辑结构、数据的存储结构和数据的操作这三个方面的内容。
数据的逻辑结构分为:线性结构,非线性结构
数据的物理(存储)结构:顺序结构,链式结构
四大基本数据结构:
集合—属于/不属于
线性结构–一对一
树形结构–一对多
图状结构/网状结构–多对多
数据运算:插入 删除 修改 查找 排序
算法的5个特性:
有穷性、确定性、可行性、有零个或多个输入、有一个或多个输出
算法分析的两个主要方面:
时间复杂性和空间复杂性
学习重点:
- 数据结构的“三要素”:逻辑结构、物理(存储)结构及在这种结构上所定义的操作(运算)。
用计算语句频度来估算算法的时间复杂度。
线性表
线性表(List):n个元素的有限序列
线性表的第i个数据元素ai的存储位置为:
LOC(ai)=LOC(a1)+(i-1)L
- 顺序表中逻辑上相邻的元素,其物理位置一定相邻。在单链表中,逻辑上相邻的元素,其物理位置不一定相邻。
顺序表中等概率下插入或删除一个元素的时间复杂度为O(n),修改操作的时间效率是O(1)。
单链表中查找/删除第i个结点的算法时间复杂度为O(n)。
线性表的两种存储结构各自的优缺点:
顺序存储
优点:存储密度大,存储空间利用率高,可随机存取。
缺点:插入或删除元素时不方便。
链式存储
优点:插入或删除元素时很方便,使用灵活;结点空间可以动态申请和释放。
缺点:存储密度小,存储空间利用率低,非随机存取。
若线性表的长度变化不大,且其主要操作是查找,则采用顺序表。
若线性表的长度变化较大,且其主要操作是插入、删除操作,则采用链表。
顺序表(sequenceList):用一组地址连续的存储单元依次存放线性表的数据元素。
- 插入–在线性表的第i个位置前插入一个元素
实现步骤:
①将第n至第i位的元素向后移动一个位置;
②将要插入的元素写到第i个位置;
③表长加1。
注意:事先应判断:插入位置i是否合法?表是否已满?
应当符合条件: pos=[1, len+1]
核心语句:
for (i=len; i>=pos; i–){
listArray[i]=listArray[i-1];
}
listArray[pos-1]=obj
链表(linkList):用一组任意的存储单元来存放线性表的数据元素。
-
结点的定义
class Node{
T data;
Node next;
Node(Node n){
Next=n;
}
Node(T obj,Node n){
data=obj;
next=n;
}
T getData(){
return data;
}
Node getNext(){
return next;
}
} -
单链表的查找(带头结点)
Int num=1;
Node p=head,q=head.next;
while(num<pos){
p=q;
q=q.next;
num++;
} -
单链表的插入结点s
Step 1:s->next=p->next;
Step 2:p->next=s; -
单链表的删除
T x=q.data;
p.next=q.next; -
头结点的判空条件:
不带头结点:head == null;
带头结点:head.next == null;
栈和队列
栈(stack):仅在表尾(栈顶)进行插入和删除操作的线性表。
顺序栈(sequenceStack):利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素,定义top指向栈顶元素。
-
入栈
top++;
stackArray[top]=obj; -
出栈
T x=stackArray[top];
top–; -
链栈(不带空的头结点)
向一个栈顶指针为HS的链栈中插入一个s所指结点
s next= HS;
HS=s; -
从一个栈顶指针为HS的链栈中删除一个结点
x=HS data;
HS= HS. next;
一个栈的入栈序列a,b,c,d,e,则栈的不可能的输出序列是 C
A edcba B. decba C. dceab D abcde
什么叫“假溢出” ?如何解决?
在顺序队列中,当尾指针已经到了数组的上界,不能再有入队操作,但其实数组中还有空位置,这就叫“假溢出”。解决假溢出的途径———采用循环队列
队列:队尾插入,队头删除的线性表。
顺序队列:用一组地址连续的存储单元依次存放从队头到队尾的元素,定义front和rear分别指示队列的队头元素和队尾元素。
-
入队
rear=(rear+1)%queueArray.length;
queueArray[rear]=obj; -
出队
front=(front+1)%queueArray.length;
return queueArray[front]; -
判空
rear == front -
判满
(rear+1)%queueArray.length == front
树和二叉树
树:若干个结点组成的有限集合。
二叉树:每个结点最多拥有两棵子树的树。
满二叉树:在一颗二叉树中,所有分支结点都有左子树和右子树,并且所有叶子结点都在同一层上。
完全二叉树:叶子结点只能出现在最下层和次下层且最下层的叶子结点集中在树的左边。
二叉树的性质
性质1: 在二叉树的第i层上至多有2i-1个结点。
性质2: 深度为k的二叉树至多有2k-1个结点。
性质3: 对于任何一棵二叉树,若2度的结点数有n个,则叶子结点数必定为n+1
性质4: 具有n个结点的完全二叉树的深度必为(log2n)+1
性质5: 对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2i,其右孩子编号为2i+1;其双亲的编号必为i/2(i!=1)。
二叉树的遍历:一棵二叉树由根节点、根结点的左子树和根结点的右子树三部分组成。因此只要依次遍历这三个部分,就可以遍历整个二叉树。
DLR(先序遍历)
LDR(中序遍历)
LRD(后序遍历)
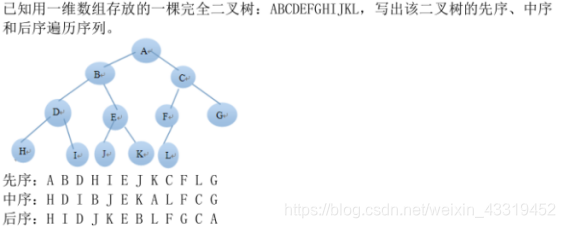
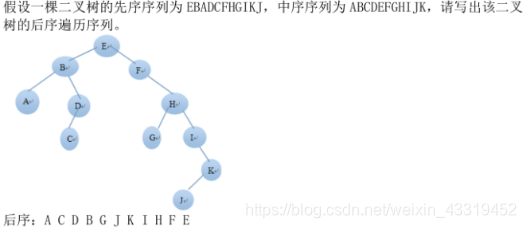
图
图:由顶点集合及顶点之间的关系集合组成的一种数据结构。
记为G=(V,E),其中V是G的顶点集合,是有穷非空集;E是G的边集合,是有穷集。
有向图:<x,y>表示从顶点x发向顶点y的边。
路径:两个顶点之间的顶点序列。路径上边的数目为长度。
简单路径:顶点序列中顶点不重复出现的路径。
连通图:图中任意两个顶点都是连通的。
- 无向图的顶点个数为n,则此图最多包含有n(n-1)/2条边。
有向图的顶点个数为n,若要使任意两点间可以互相到达,则至少需要n条边。
n个顶点的连通图的生成树含有n-1条边。
图的遍历:
深度优先搜索
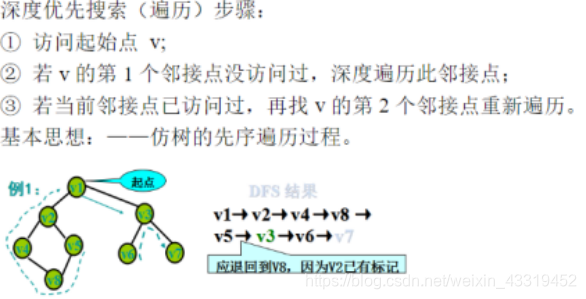
广度优先搜索

最小生成树:所有生成树中边的权值总和最小的生成树。
Prime(普里姆)算法特点: 集合到集合的最小权值,适于稠密网。

Kruskal(克鲁斯卡尔)算法特点:最小权值之和且不能成环,适于求稀疏网的最小生成树。
