现实生活中时间是很重要的概念,时间可以记录事情发生的时刻、比较事情发生的先后顺序。分布式系统的一些场景也需要记录和比较不同节点间事件发生的顺序,但不同于日常生活使用物理时钟记录时间,分布式系统使用逻辑时钟记录事件顺序关系,下面我们来看分布式系统中几种常见的逻辑时钟。
物理时钟 vs 逻辑时钟
可能有人会问,为什么分布式系统不使用物理时钟(physical clock)记录事件?每个事件对应打上一个时间戳,当需要比较顺序的时候比较相应时间戳就好了。
这是因为现实生活中物理时间有统一的标准,而分布式系统中每个节点记录的时间并不一样,即使设置了 NTP 时间同步节点间也存在毫秒级别的偏差[1][2]。因而分布式系统需要有另外的方法记录事件顺序关系,这就是逻辑时钟(logical clock)。
Lamport timestamps
Leslie Lamport 在1978年提出逻辑时钟的概念,并描述了一种逻辑时钟的表示方法,这个方法被称为Lamport时间戳(Lamport timestamps)[3]。
分布式系统中按是否存在节点交互可分为三类事件,一类发生于节点内部,二是发送事件,三是接收事件。Lamport时间戳原理如下:
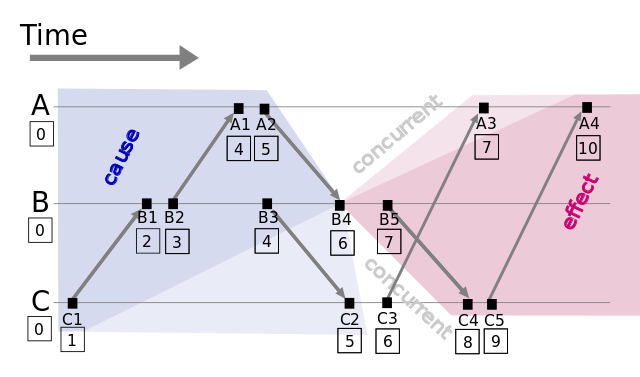
图1: Lamport timestamps space time (图片来源: wikipedia)
- 每个事件对应一个Lamport时间戳,初始值为0
- 如果事件在节点内发生,时间戳加1
- 如果事件属于发送事件,时间戳加1并在消息中带上该时间戳
- 如果事件属于接收事件,时间戳 = Max(本地时间戳,消息中的时间戳) + 1
假设有事件a、b,C(a)、C(b)分别表示事件a、b对应的Lamport时间戳,如果C(a) < C(b),则有a发生在b之前(happened before),记作 a -> b,例如图1中有 C1 -> B1。通过该定义,事件集中Lamport时间戳不等的事件可进行比较,我们获得事件的偏序关系(partial order)。
如果C(a) = C(b),那a、b事件的顺序又是怎样的?假设a、b分别在节点P、Q上发生,Pi、Qj分别表示我们给P、Q的编号,如果 C(a) = C(b) 并且 Pi< Qj,同样定义为a发生在b之前,记作 a => b。假如我们对图1的A、B、C分别编号Ai = 1、Bj = 2、Ck = 3,因 C(B4) = C(C3) 并且 Bj < Ck,则 B4 => C3。
通过以上定义,我们可以对所有事件排序、获得事件的全序关系(total order)。上图例子,我们可以从C1到A4进行排序。
Vector clock
Lamport时间戳帮助我们得到事件顺序关系,但还有一种顺序关系不能用Lamport时间戳很好地表示出来,那就是同时发生关系(concurrent)[4]。例如图1中事件B4和事件C3没有因果关系,属于同时发生事件,但Lamport时间戳定义两者有先后顺序。
Vector clock是在Lamport时间戳基础上演进的另一种逻辑时钟方法,它通过vector结构不但记录本节点的Lamport时间戳,同时也记录了其他节点的Lamport时间戳[5][6]。Vector clock的原理与Lamport时间戳类似,使用图例如下:
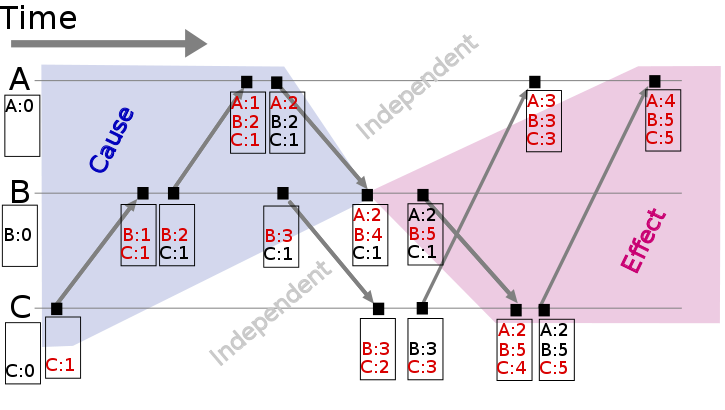
图2: Vector clock space time (图片来源: wikipedia)
假设有事件a、b分别在节点P、Q上发生,Vector clock分别为Ta、Tb,如果 Tb[Q] > Ta[Q] 并且 Tb[P] >= Ta[P],则a发生于b之前,记作 a -> b。到目前为止还和Lamport时间戳差别不大,那Vector clock怎么判别同时发生关系呢?
如果 Tb[Q] > Ta[Q] 并且 Tb[P] < Ta[P],则认为a、b同时发生,记作 a <-> b。例如图2中节点B上的第4个事件 (A:2,B:4,C:1) 与节点C上的第2个事件 (B:3,C:2) 没有因果关系、属于同时发生事件。
Version vector
基于Vector clock我们可以获得任意两个事件的顺序关系,结果或为先后顺序或为同时发生,识别事件顺序在工程实践中有很重要的引申应用,最常见的应用是发现数据冲突(detect conflict)。
分布式系统中数据一般存在多个副本(replication),多个副本可能被同时更新,这会引起副本间数据不一致[7],Version vector的实现与Vector clock非常类似[8],目的用于发现数据冲突[9]。下面通过一个例子说明Version vector的用法[10]:
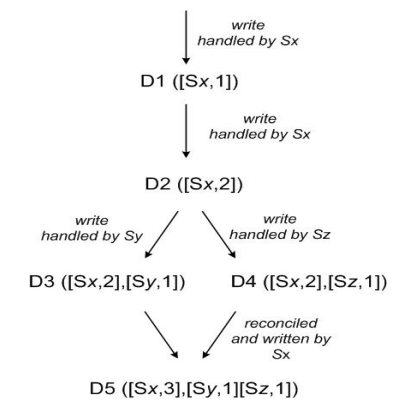
图3: Version vector
- client端写入数据,该请求被Sx处理并创建相应的vector ([Sx, 1]),记为数据D1
- 第2次请求也被Sx处理,数据修改为D2,vector修改为([Sx, 2])
- 第3、第4次请求分别被Sy、Sz处理,client端先读取到D2,然后D3、D4被写入Sy、Sz
- 第5次更新时client端读取到D2、D3和D4 3个数据版本,通过类似Vector clock判断同时发生关系的方法可判断D3、D4存在数据冲突,最终通过一定方法解决数据冲突并写入D5
Vector clock只用于发现数据冲突,不能解决数据冲突。如何解决数据冲突因场景而异,具体方法有以最后更新为准(last write win),或将冲突的数据交给client由client端决定如何处理,或通过quorum决议事先避免数据冲突的情况发生[11]。
由于记录了所有数据在所有节点上的逻辑时钟信息,Vector clock和Version vector在实际应用中可能面临的一个问题是vector过大,用于数据管理的元数据(meta data)甚至大于数据本身[12]。
解决该问题的方法是使用server id取代client id创建vector (因为server的数量相对client稳定),或设定最大的size、如果超过该size值则淘汰最旧的vector信息[10][13]。
True Time
前面我们说了,NTP是有误差的,而且NTP还可能出现时间回退的情况,所以我们不能直接依赖NTP来确定一个事件发生的时间。在Google Spanner里面,通过引入True Time来解决了分布式时间问题。
Spanner通过使用GPS + Atomic Clock来对集群的机器进行校时,精度误差范围能控制在ms级别,通过提供一套TrueTime API给外面使用。
TrueTime API很简单,只有三个函数:
| Method | Return |
|---|---|
| TT.now() | TTinterval: [earliest, latest] |
| TT.after(t) | true if t has definitely passed |
| TT.before(t) | true if t has definitely not arrived |
首先now得到当前的一个时间区间,spanner不能得到精确的一个时间点,只能得到一段区间,但这个区间误差范围很小,也就是ms级别,我们用ε来表示,也就是[t - ε, t + ε]这个范围,
假设事件a发生绝对时间为tt.a,那么我们只能知道tt.a.earliest <= tt.a <= tt.a.latest, 所以对于另一个事件b,只要tt.b.earliest > tt.a.latest,我们就能确定b一定是在a之后发生的,也就是说,我们需要等待大概2ε的事件才能去提交b,这个就是spanner里面说的commit wait time。
可以看到,虽然spanner引入了TrueTime可以得到全球范围的时序一致性,但相关事务在提交的时候会有一个wait时间,只是这个时间很短,而且spanner后续都准备将其优化到 ε < 1ms,也就是对于关联事务,仅仅在上一个事务commit之后等待2ms之后就能执行,性能还是很强悍的。
但spanner有一个最大的问题,TrueTime是基于硬件的,而现在对于很多企业来说,是没有办法搞定这套部署的。所以如果Google能将TrueTime的硬件设计开源,那我觉得更加造福社区了。
Hybrid Logic Clock
既然TrueTime这种硬件方案很多人搞不定,那么我们就采用软件方案了。
Cockroachdb使用了Hybrid Logic Clock(HLC)来解决分布式时间的问题。
HLC是基于NTP的,但它只会读取当前系统时间,而不会去修改,同时HLC又能保证在NTP出现同步问题的时候仍能够很好的进行容错处理。对于一个HLC的时间t来时,它总是大于等于当前的系统时间,并且与其在一个很小的误差范围里面,也就是 |l - pt| < ε。
HLC由两部分组成,physical clock + logic clock,l.j维护的是节点j当前已知的最大的物理时间,c.j则是当前的逻辑时间。那么判断两个事件的先后顺序就很容易了,先判断物理时间pt,在判断逻辑时间ct。
HLC的算法如下,在节点j上面:
-
初始化:
l.j = 0, c.j = 0 -
给另一个进程发送或者处理自己的事件:
l'.j = l.j; // 跟当前系统时间比较,得到pt l.j = max(l'j, pt.j) // 如果pt没有变化,则c.j加1,如果有变化,因为这时候 // 铁定PT变大了,所以我们可以将ct清零 if (l.j = l'.j) { c.j = c.j + 1 } else { c.j = 0 } // Timestamp with l.j, c.j -
接受某一个节点m的消息事件
l'.j = l.j; // 跟当前系统事件以及节点m的pt比较,得到pt l.j = max(l'.j, l.m, pt.j) if (l.j = l'.j = l.m) { // pt一样,获取最大的ct,并加1 c.j = max(c.j, c.m) + 1 } else if (l.j = l'j) { // 这里表明j原来的pt比m大,只需要增加ct c.j = c.j + 1 } else if (l.j = l.m) { // 这里表明m的pt比j原来的要大,所以直接可以用m的ct + 1 c.j = c.m + 1 } else { // pt变化了,ct清零 c.j = 0 } // Timestamp with l.j, c.j
具体的实现算法,可以看cockroachdb的HLC实现。
HLC虽然方便,它毕竟是基于NTP的,所以如果NTP出现了问题,可能导致HLC与当前系统pt的时间误差过大,其实已经不怎么精确了,HLC论文提到对于一些out of bounds的message可以直接忽略,然后加个log让人工后续处理,而cockroachdb是直接打印了一个warning log。
Timestamp Oracle
无论上面的Ture Time还是Hybrid Logic Time,都是为了在分布式情况下获取全局唯一时间,如果我们整个系统不复杂,而且没有spanner那种跨全球的需求,有时候一台中心授时服务没准就可以了。
在Google Percolator系统这,他们就提到使用了一个timestamp oracle(TSO)的服务来提供统一的授时服务,为啥叫oracle,我猜想可能底层用的就是oracle数据库。。。
使用TSO的好处在于因为只有一个中心授时,所以我们一定能确定所有时间的时间,但TSO需要关注几个问题:
- 网络延时,因为所有的事件都需要从TSO获取时间,所以TSO的场景通常都是小集群,不能是那种全球级别的数据库。
- 性能,TSO是一个非常高频的操作,但鉴于它只干一件事情,就是授时,通常一个TSO每秒都能支持1m+ 以上的QPS,而这个对很多应用来说是绰绰有余的。
- 容错,TSO是一个单点,所以不得不考虑容错,而这个现在基于zookeeper,etcd也不是特别困难的事情。
所以,如果我们没法实现TrueTime,同时又觉得HLC太复杂,但又想获取全局时间,TSO没准是一个很好的选择,因为它足够简单高效。
我们现在的数据库产品就使用的是TSO方案,但也不排除以后为了支持全球同步,而考虑使用TureTime或者HLC的方案。
小结
以上介绍了分布式系统里逻辑时钟的表示方法,通过Lamport timestamps可以建立事件的全序关系,通过Vector clock可以比较任意两个事件的顺序关系并且能表示无因果关系的事件,将Vector clock的方法用于发现数据版本冲突,于是有了Version vector。
[1] Time is an illusion, George Neville-Neil, 2016
[2] There is No Now, Justin Sheehy, 2015
[3] Time, Clocks, and the Ordering of Events in a Distributed System, Leslie Lamport, 1978
[4] Timestamps in Message-Passing Systems That Preserve the Partial Ordering, Colin J. Fidge, 1988
[5] Virtual Time and Global States of Distributed Systems, Friedemann Mattern, 1988
[6] Why Vector Clocks are Easy, Bryan Fink, 2010
[7] Conflict Management, CouchDB
[8] Version Vectors are not Vector Clocks, Carlos Baquero, 2011
[9] Detection of Mutual Inconsistency in Distributed Systems, IEEE Transactions on Software Engineering , 1983
[10] Dynamo: Amazon’s Highly Available Key-value Store, Amazon, 2007
[11] Conflict Resolution, Jeff Darcy , 2010
[12] Why Vector Clocks Are Hard, Justin Sheehy, 2010
[13] Causality Is Expensive (and What To Do About It), Peter Bailis ,2014