从我的个人感觉来说,这篇文章的内容就是我们平时自己增强数据的方式,所以实际意义不是特别大。另外该算法并不是通用的,他需要你自己根据自身训练集对参数进行修改。
论文地址:
https://arxiv.org/pdf/1909.13719.pdf
GitHub地址:
https://github.com/tensorflow/tpu/blob/master/models/official/efficientnet/autoaugment.py
你的数据还不够强。
玩深度学习的人都知道,AI算法大部分是数据驱动。数据的质量一定程度上决定了模型的好坏。
这就有了深度学习天生的一个短板:数据不够多、不够好。
而数据增强就是解决这一问题的有效办法。
谷歌大脑去年提出了自动数据增强方法(AutoAugment),确实对图像分类和目标检测等任务带来了益处。
但缺点也是明显的:
1、大规模采用这样的方法会增加训练复杂性、加大计算成本;
2、无法根据模型或数据集大小调整正则化强度。
于是乎,谷歌大脑团队又提出了一种数据增强的方法——RandAugment。

这个方法有多好?

谷歌大脑高级研究科学家Barret Zoph表示:
RandAugment是一种新的数据增强方法,比AutoAugment简单又好用。
主要思想是随机选择变换,调整它们的大小。
最后的实验结果表明:
1、在ImageNet数据集上,实现了85.0%的准确率,比以前的水平提高了0.6%,比基线增强了1.0%。
2、在目标检测方面,RandAugment能比基线增强方法提高1.0-1.3%。
值得一提的是,这项研究的通讯作者是谷歌AutoML幕后英雄的Quoc Viet Le大神。

△Quoc Viet Le
这么好的技术当然开源了代码:
https://github.com/tensorflow/tpu/blob/master/models/official/efficientnet/autoaugment.py
RandAugment是怎么做到的?
正如刚才说到的,单独搜索是问题的关键点。
所以研究人员的目标就是消除数据增强过程中对单独搜索的需求。
再考虑到以往数据增强方法都包含30多个参数,团队也将关注点转移到了如何大幅减少数据增强的参数空间。
为了减少参数空间的同时保持数据(图像)的多样性,研究人员用无参数过程替代了学习的策略和概率。
这些策略和概率适用于每次变换(transformation),该过程始终选择均匀概率为1/k的变换。
也就是说,给定训练图像的N个变换,RandAugment就能表示KN个潜在策略。
最后,需要考虑到的一组参数是每个增强失真(augmentation distortion)的大小。
研究人员采用线性标度来表示每个转换的强度。简单来说,就是每次变换都在0到10的整数范围内,其中,10表示给定变换的最大范围。
为了进一步缩小参数空间,团队观察到每个转换的学习幅度(learned magnitude)在训练期间遵循类似的表:

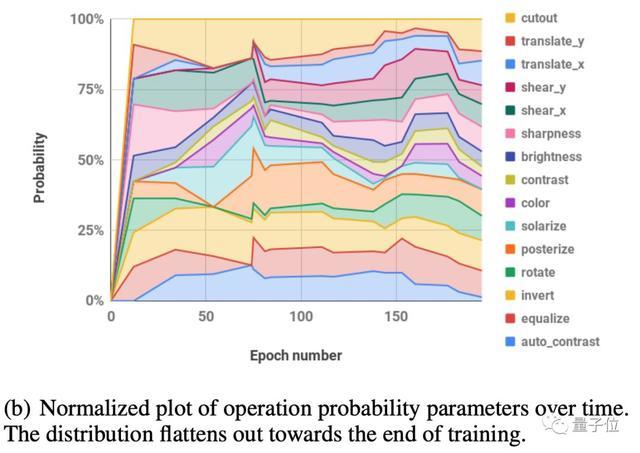
并假设一个单一的全局失真M(global distortion M)可能就足以对所有转换进行参数化。
这样,生成的算法便包含两个参数N和M,还可以用两行Python代码简单表示:

△基于numpy的RandAugment Python代码
因为这两个参数都是可人为解释的,所以N和M的值越大,正则化强度就越大。
可以使用标准方法高效地进行超参数优化,但是考虑到极小的搜索空间,研究人员发现朴素网格搜索(naive grid search)是非常有效的。
实验结果
在实验部分,主要围绕图像分类和目标检测展开。
研究人员较为关注的数据集包括:CIFAR-10、CIFAR-100、SVHN、ImageNet以及COCO。
这样就可以与之前的工作做比较,证明RandAugment在数据增强方面的优势。
数据增强的一个前提是构建一个小的代理任务(proxy task),这个任务可以反映一个较大的任务。
研究人员挑战了这样一个假设:
用小型proxy task来描述问题适合于学习数据的增强。
特别地,从两个独立的维度来探讨这个问题,这两个维度通常被限制为实现小型proxy task:模型大小和数据集大小。
为了探究这一假设,研究人员系统地测量了数据增强策略对CIFAR-10的影响。结果如下图所示:

△最优增强量取决于模型和训练集的大小。
其中:
图(a)表示Wide-ResNet-28-2,Wide-ResNet-28-7和Wide-ResNet-28-10在各种失真幅度(distortion magnitude)下的精度。
图(b)表示在7种Wide-ResNet-28架构中,随着变宽参数(k)的变化,所产生的最佳失真幅度。
图(c)表示Wide-ResNet-28-10的三种训练集大小(1K,4K和10K)在各种失真幅度上的准确性。
图(d)在8个训练集大小上的最佳失真幅度。
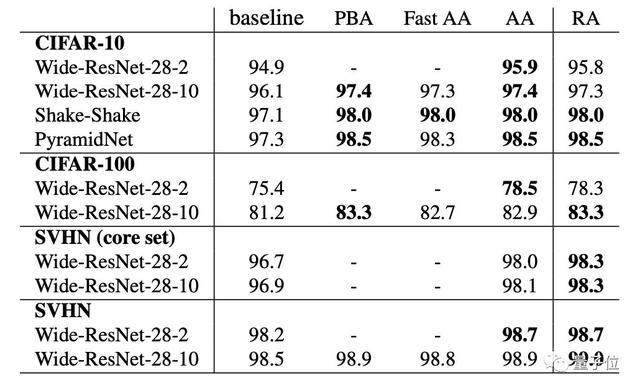
△在CIFAR-10、CIFAR-100、SVHN(core set)和SVHN上的测试精度(%)。
其中,baseline是默认的数据增强方法。
PBA:Population Based Augmentation;
Fast AA:Fast AutoAugment;
AA:AutoAugment;
RA:RandAugment。
但值得注意点的是,改进CIFAR-10和SVHN模型的数据增强方法并不总是适用于ImageNet等大规模任务。
同样地,AutoAugment在ImageNet上的性能提升也不如其他任务。
下表比较了在ImageNet上RandAugment和其他增强方法的性能。

△ImageNet结果。
在最小的模型(ResNet-50)上,RandAugment的性能与AutoAugment和Fast AutoAugment相似,但在较大的模型上,RandAugment的性能显著优于其他方法,比基线提高了1.3%。
为了进一步测试这种方法的通用性,研究人接下来在COCO数据集上进行了大规模目标检测的相关任务。

△目标检测结果。
COCO目标检测任务的平均精度均值(Mean average precision,mAP)。数值越高,结果越好。
下一步工作
我们知道数据增强可以提高预测性能,例如图像分割,3-D感知,语音识别或音频识别。
研究人员表示,未来的工作将研究这种方法将如何应用于其他机器学习领域。
特别是希望更好地了解数据集或任务是否/何时可能需要单独的搜索阶段才能获得最佳性能。
最后,研究人员还抛出了一个悬而未决的问题:
如何针对给定的任务定制一组转换,进一步提高给定模型的预测性能。
对此,你又什么想法?
基于PIL的代码https://github.com/ildoonet/pytorch-randaugment
# code in this file is adpated from rpmcruz/autoaugment
# https://github.com/rpmcruz/autoaugment/blob/master/transformations.py
import random
import PIL, PIL.ImageOps, PIL.ImageEnhance, PIL.ImageDraw
import numpy as np
import torch
from PIL import Image
def ShearX(img, v): # [-0.3, 0.3]
assert -0.3 <= v <= 0.3
if random.random() > 0.5:
v = -v
return img.transform(img.size, PIL.Image.AFFINE, (1, v, 0, 0, 1, 0))
def ShearY(img, v): # [-0.3, 0.3]
assert -0.3 <= v <= 0.3
if random.random() > 0.5:
v = -v
return img.transform(img.size, PIL.Image.AFFINE, (1, 0, 0, v, 1, 0))
def TranslateX(img, v): # [-150, 150] => percentage: [-0.45, 0.45]
assert -0.45 <= v <= 0.45
if random.random() > 0.5:
v = -v
v = v * img.size[0]
return img.transform(img.size, PIL.Image.AFFINE, (1, 0, v, 0, 1, 0))
def TranslateXabs(img, v): # [-150, 150] => percentage: [-0.45, 0.45]
assert 0 <= v
if random.random() > 0.5:
v = -v
return img.transform(img.size, PIL.Image.AFFINE, (1, 0, v, 0, 1, 0))
def TranslateY(img, v): # [-150, 150] => percentage: [-0.45, 0.45]
assert -0.45 <= v <= 0.45
if random.random() > 0.5:
v = -v
v = v * img.size[1]
return img.transform(img.size, PIL.Image.AFFINE, (1, 0, 0, 0, 1, v))
def TranslateYabs(img, v): # [-150, 150] => percentage: [-0.45, 0.45]
assert 0 <= v
if random.random() > 0.5:
v = -v
return img.transform(img.size, PIL.Image.AFFINE, (1, 0, 0, 0, 1, v))
def Rotate(img, v): # [-30, 30]
assert -30 <= v <= 30
if random.random() > 0.5:
v = -v
return img.rotate(v)
def AutoContrast(img, _):
return PIL.ImageOps.autocontrast(img)
def Invert(img, _):
return PIL.ImageOps.invert(img)
def Equalize(img, _):
return PIL.ImageOps.equalize(img)
def Flip(img, _): # not from the paper
return PIL.ImageOps.mirror(img)
def Solarize(img, v): # [0, 256]
assert 0 <= v <= 256
return PIL.ImageOps.solarize(img, v)
def SolarizeAdd(img, addition=0, threshold=128):
img_np = np.array(img).astype(np.int)
img_np = img_np + addition
img_np = np.clip(img_np, 0, 255)
img_np = img_np.astype(np.uint8)
img = Image.fromarray(img_np)
return PIL.ImageOps.solarize(img, threshold)
def Posterize(img, v): # [4, 8]
v = int(v)
v = max(1, v)
return PIL.ImageOps.posterize(img, v)
def Contrast(img, v): # [0.1,1.9]
assert 0.1 <= v <= 1.9
return PIL.ImageEnhance.Contrast(img).enhance(v)
def Color(img, v): # [0.1,1.9]
assert 0.1 <= v <= 1.9
return PIL.ImageEnhance.Color(img).enhance(v)
def Brightness(img, v): # [0.1,1.9]
assert 0.1 <= v <= 1.9
return PIL.ImageEnhance.Brightness(img).enhance(v)
def Sharpness(img, v): # [0.1,1.9]
assert 0.1 <= v <= 1.9
return PIL.ImageEnhance.Sharpness(img).enhance(v)
def Cutout(img, v): # [0, 60] => percentage: [0, 0.2]
assert 0.0 <= v <= 0.2
if v <= 0.:
return img
v = v * img.size[0]
return CutoutAbs(img, v)
def CutoutAbs(img, v): # [0, 60] => percentage: [0, 0.2]
# assert 0 <= v <= 20
if v < 0:
return img
w, h = img.size
x0 = np.random.uniform(w)
y0 = np.random.uniform(h)
x0 = int(max(0, x0 - v / 2.))
y0 = int(max(0, y0 - v / 2.))
x1 = min(w, x0 + v)
y1 = min(h, y0 + v)
xy = (x0, y0, x1, y1)
color = (125, 123, 114)
# color = (0, 0, 0)
img = img.copy()
PIL.ImageDraw.Draw(img).rectangle(xy, color)
return img
def SamplePairing(imgs): # [0, 0.4]
def f(img1, v):
i = np.random.choice(len(imgs))
img2 = PIL.Image.fromarray(imgs[i])
return PIL.Image.blend(img1, img2, v)
return f
def Identity(img, v):
return img
def augment_list(): # 16 oeprations and their ranges
# https://github.com/google-research/uda/blob/master/image/randaugment/policies.py#L57
# l = [
# (Identity, 0., 1.0),
# (ShearX, 0., 0.3), # 0
# (ShearY, 0., 0.3), # 1
# (TranslateX, 0., 0.33), # 2
# (TranslateY, 0., 0.33), # 3
# (Rotate, 0, 30), # 4
# (AutoContrast, 0, 1), # 5
# (Invert, 0, 1), # 6
# (Equalize, 0, 1), # 7
# (Solarize, 0, 110), # 8
# (Posterize, 4, 8), # 9
# # (Contrast, 0.1, 1.9), # 10
# (Color, 0.1, 1.9), # 11
# (Brightness, 0.1, 1.9), # 12
# (Sharpness, 0.1, 1.9), # 13
# # (Cutout, 0, 0.2), # 14
# # (SamplePairing(imgs), 0, 0.4), # 15
# ]
# https://github.com/tensorflow/tpu/blob/8462d083dd89489a79e3200bcc8d4063bf362186/models/official/efficientnet/autoaugment.py#L505
l = [
(AutoContrast, 0, 1),
(Equalize, 0, 1),
(Invert, 0, 1),
(Rotate, 0, 30),
(Posterize, 0, 4),
(Solarize, 0, 256),
(SolarizeAdd, 0, 110),
(Color, 0.1, 1.9),
(Contrast, 0.1, 1.9),
(Brightness, 0.1, 1.9),
(Sharpness, 0.1, 1.9),
(ShearX, 0., 0.3),
(ShearY, 0., 0.3),
(CutoutAbs, 0, 40),
(TranslateXabs, 0., 100),
(TranslateYabs, 0., 100),
]
return l
class Lighting(object):
"""Lighting noise(AlexNet - style PCA - based noise)"""
def __init__(self, alphastd, eigval, eigvec):
self.alphastd = alphastd
self.eigval = torch.Tensor(eigval)
self.eigvec = torch.Tensor(eigvec)
def __call__(self, img):
if self.alphastd == 0:
return img
alpha = img.new().resize_(3).normal_(0, self.alphastd)
rgb = self.eigvec.type_as(img).clone() \
.mul(alpha.view(1, 3).expand(3, 3)) \
.mul(self.eigval.view(1, 3).expand(3, 3)) \
.sum(1).squeeze()
return img.add(rgb.view(3, 1, 1).expand_as(img))
class CutoutDefault(object):
"""
Reference : https://github.com/quark0/darts/blob/master/cnn/utils.py
"""
def __init__(self, length):
self.length = length
def __call__(self, img):
h, w = img.size(1), img.size(2)
mask = np.ones((h, w), np.float32)
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img *= mask
return img
class RandAugment:
def __init__(self, n, m):
self.n = n
self.m = m # [0, 30]
self.augment_list = augment_list()
def __call__(self, img):
ops = random.choices(self.augment_list, k=self.n)
for op, minval, maxval in ops:
val = (float(self.m) / 30) * float(maxval - minval) + minval
img = op(img, val)
return img
if __name__ == "__main__":
a = RandAugment(2, 10)
img = Image.open(r"a.tif")
# img_arr = np.array(img)
import matplotlib.pyplot as plt
aug_img = a(img)
plt.imshow(aug_img)
plt.show()基于opencv的代码
import cv2
import numpy as np
import cv2
## aug functions
def identity_func(img):
return img
def autocontrast_func(img, cutoff=2):
'''
same output as PIL.ImageOps.autocontrast
'''
n_bins = 256
def tune_channel(ch):
n = ch.size
cut = cutoff * n // 100
if cut == 0:
high, low = ch.max(), ch.min()
else:
hist = cv2.calcHist([ch], [0], None, [n_bins], [0, n_bins])
low = np.argwhere(np.cumsum(hist) > cut)
low = 0 if low.shape[0] == 0 else low[0]
high = np.argwhere(np.cumsum(hist[::-1]) > cut)
high = n_bins - 1 if high.shape[0] == 0 else n_bins - 1 - high[0]
if high <= low:
table = np.arange(n_bins)
else:
scale = (n_bins - 1) / (high - low)
offset = -low * scale
table = np.arange(n_bins) * scale + offset
table[table < 0] = 0
table[table > n_bins - 1] = n_bins - 1
table = table.clip(0, 255).astype(np.uint8)
return table[ch]
channels = [tune_channel(ch) for ch in cv2.split(img)]
out = cv2.merge(channels)
return out
def equalize_func(img):
'''
same output as PIL.ImageOps.equalize
PIL's implementation is different from cv2.equalize
'''
n_bins = 256
def tune_channel(ch):
hist = cv2.calcHist([ch], [0], None, [n_bins], [0, n_bins])
non_zero_hist = hist[hist != 0].reshape(-1)
step = np.sum(non_zero_hist[:-1]) // (n_bins - 1)
if step == 0: return ch
n = np.empty_like(hist)
n[0] = step // 2
n[1:] = hist[:-1]
table = (np.cumsum(n) // step).clip(0, 255).astype(np.uint8)
return table[ch]
channels = [tune_channel(ch) for ch in cv2.split(img)]
out = cv2.merge(channels)
return out
def rotate_func(img, degree, fill=(0, 0, 0)):
'''
like PIL, rotate by degree, not radians
'''
H, W = img.shape[0], img.shape[1]
center = W / 2, H / 2
M = cv2.getRotationMatrix2D(center, degree, 1)
out = cv2.warpAffine(img, M, (W, H), borderValue=fill)
return out
def solarize_func(img, thresh=128):
'''
same output as PIL.ImageOps.posterize
'''
table = np.array([el if el < thresh else 255 - el for el in range(256)])
table = table.clip(0, 255).astype(np.uint8)
out = table[img]
return out
def color_func(img, factor=5):
'''
same output as PIL.ImageEnhance.Color
'''
## implementation according to PIL definition, quite slow
# degenerate = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)[:, :, np.newaxis]
# out = blend(degenerate, img, factor)
# M = (
# np.eye(3) * factor
# + np.float32([0.114, 0.587, 0.299]).reshape(3, 1) * (1. - factor)
# )[np.newaxis, np.newaxis, :]
M = (
np.float32([
[0.886, -0.114, -0.114],
[-0.587, 0.413, -0.587],
[-0.299, -0.299, 0.701]]) * factor
+ np.float32([[0.114], [0.587], [0.299]])
)
out = np.matmul(img, M).clip(0, 255).astype(np.uint8)
return out
def contrast_func(img, factor=5):
"""
same output as PIL.ImageEnhance.Contrast
"""
mean = np.sum(np.mean(img, axis=(0, 1)) * np.array([0.114, 0.587, 0.299]))
table = np.array([(
el - mean) * factor + mean
for el in range(256)
]).clip(0, 255).astype(np.uint8)
out = table[img]
return out
def brightness_func(img, factor=2):
'''
same output as PIL.ImageEnhance.Contrast
'''
table = (np.arange(256, dtype=np.float32) * factor).clip(0, 255).astype(np.uint8)
out = table[img]
return out
def sharpness_func(img, factor=2):
'''
The differences the this result and PIL are all on the 4 boundaries, the center
areas are same
'''
kernel = np.ones((3, 3), dtype=np.float32)
kernel[1][1] = 5
kernel /= 13
degenerate = cv2.filter2D(img, -1, kernel)
if factor == 0.0:
out = degenerate
elif factor == 1.0:
out = img
else:
out = img.astype(np.float32)
degenerate = degenerate.astype(np.float32)[1:-1, 1:-1, :]
out[1:-1, 1:-1, :] = degenerate + factor * (out[1:-1, 1:-1, :] - degenerate)
out = out.astype(np.uint8)
return out
def shear_x_func(img, factor, fill=(0, 0, 0)):
H, W = img.shape[0], img.shape[1]
M = np.float32([[1, factor, 0], [0, 1, 0]])
out = cv2.warpAffine(img, M, (W, H), borderValue=fill, flags=cv2.INTER_LINEAR).astype(np.uint8)
return out
def translate_x_func(img, offset=10, fill=(0, 0, 0)):
'''
same output as PIL.Image.transform
'''
H, W = img.shape[0], img.shape[1]
M = np.float32([[1, 0, -offset], [0, 1, 0]])
out = cv2.warpAffine(img, M, (W, H), borderValue=fill, flags=cv2.INTER_LINEAR).astype(np.uint8)
return out
def translate_y_func(img, offset, fill=(0, 0, 0)):
'''
same output as PIL.Image.transform
'''
H, W = img.shape[0], img.shape[1]
M = np.float32([[1, 0, 0], [0, 1, -offset]])
out = cv2.warpAffine(img, M, (W, H), borderValue=fill, flags=cv2.INTER_LINEAR).astype(np.uint8)
return out
def posterize_func(img, bits):
'''
same output as PIL.ImageOps.posterize
'''
out = np.bitwise_and(img, np.uint8(255 << (8 - bits)))
return out
def shear_y_func(img, factor, fill=(0, 0, 0)):
H, W = img.shape[0], img.shape[1]
M = np.float32([[1, 0, 0], [factor, 1, 0]])
out = cv2.warpAffine(img, M, (W, H), borderValue=fill, flags=cv2.INTER_LINEAR).astype(np.uint8)
return out
def cutout_func(img, pad_size, replace=(0, 0, 0)):
replace = np.array(replace, dtype=np.uint8)
H, W = img.shape[0], img.shape[1]
rh, rw = np.random.random(2)
pad_size = pad_size // 2
ch, cw = int(rh * H), int(rw * W)
x1, x2 = max(ch - pad_size, 0), min(ch + pad_size, H)
y1, y2 = max(cw - pad_size, 0), min(cw + pad_size, W)
out = img.copy()
out[x1:x2, y1:y2, :] = replace
return out
### level to args
def enhance_level_to_args(MAX_LEVEL):
def level_to_args(level):
return ((level / MAX_LEVEL) * 1.8 + 0.1,)
return level_to_args
def shear_level_to_args(MAX_LEVEL, replace_value):
def level_to_args(level):
level = (level / MAX_LEVEL) * 0.3
if np.random.random() > 0.5: level = -level
return (level, replace_value)
return level_to_args
def translate_level_to_args(translate_const, MAX_LEVEL, replace_value):
def level_to_args(level):
level = (level / MAX_LEVEL) * float(translate_const)
if np.random.random() > 0.5: level = -level
return (level, replace_value)
return level_to_args
def cutout_level_to_args(cutout_const, MAX_LEVEL, replace_value):
def level_to_args(level):
level = int((level / MAX_LEVEL) * cutout_const)
return (level, replace_value)
return level_to_args
def solarize_level_to_args(MAX_LEVEL):
def level_to_args(level):
level = int((level / MAX_LEVEL) * 256)
return (level, )
return level_to_args
def none_level_to_args(level):
return ()
def posterize_level_to_args(MAX_LEVEL):
def level_to_args(level):
level = int((level / MAX_LEVEL) * 4)
return (level, )
return level_to_args
def rotate_level_to_args(MAX_LEVEL, replace_value):
def level_to_args(level):
level = (level / MAX_LEVEL) * 30
if np.random.random() < 0.5:
level = -level
return (level, replace_value)
return level_to_args
func_dict = {
'Identity': identity_func,
'AutoContrast': autocontrast_func,
'Equalize': equalize_func,
# 'Rotate': rotate_func,
'Solarize': solarize_func,
'Color': color_func,
'Contrast': contrast_func,
'Brightness': brightness_func,
'Sharpness': sharpness_func,
# 'ShearX': shear_x_func,
# 'TranslateX': translate_x_func,
# 'TranslateY': translate_y_func,
'Posterize': posterize_func,
# 'ShearY': shear_y_func,
}
translate_const = 10
# MAX_LEVEL = 10
MAX_LEVEL = 30
replace_value = (128, 128, 128)
arg_dict = {
'Identity': none_level_to_args,
'AutoContrast': none_level_to_args,
'Equalize': none_level_to_args,
# 'Rotate': rotate_level_to_args(MAX_LEVEL, replace_value),
'Solarize': solarize_level_to_args(MAX_LEVEL),
'Color': enhance_level_to_args(MAX_LEVEL),
'Contrast': enhance_level_to_args(MAX_LEVEL),
'Brightness': enhance_level_to_args(MAX_LEVEL),
'Sharpness': enhance_level_to_args(MAX_LEVEL),
# 'ShearX': shear_level_to_args(MAX_LEVEL, replace_value),
# 'TranslateX': translate_level_to_args(
# translate_const, MAX_LEVEL, replace_value
# ),
# 'TranslateY': translate_level_to_args(
# translate_const, MAX_LEVEL, replace_value
# ),
'Posterize': posterize_level_to_args(MAX_LEVEL),
# 'ShearY': shear_level_to_args(MAX_LEVEL, replace_value),
}
class RandomAugment(object):
def __init__(self, N=2, M=10):
self.N = N
self.M = M
def get_random_ops(self):
sampled_ops = np.random.choice(list(func_dict.keys()), self.N)
return [(op, 1., self.M) for op in sampled_ops]
def __call__(self, img):
ops = self.get_random_ops()
for name, prob, level in ops:
if np.random.random() > prob:
continue
args = arg_dict[name](level)
img = func_dict[name](img, *args)
# img = cutout_func(img, 16, replace_value)
return img
if __name__ == '__main__':
import matplotlib.pyplot as plt
a = RandomAugment()
# img = np.random.randn(32, 32, 3)
# a(img)
imgPath = r"a.tif"
img = cv2.imread(imgPath)
img2 = a(img)
plt.subplot(121)
plt.imshow(img[:,:,::-1])
plt.subplot(122)
plt.imshow(img2[:,:,::-1])
plt.show()