文章目录
0 网络通信方式总结
k8s通过CNI接口接入其他插件来实现网络通讯。目前比较流行的插件有flannel, calico等。
CNI插件存放位置: cat /etc/cni/net.d/10-flannel.conflist
插件使用的解决方案如下:
- 虚拟网桥,虚拟网卡,多个容器共用一一个虛拟网卡进行通信。
- 多路复用: MacVLAN,多个容器共用- -个物理网卡进行通信。
- 硬件交换: SR-LOV, 一个物理网卡可以虚拟出多个接口,这个性能最好。
容器间通信:同一个pod内的多个容器间的通信,通过Io即可实现;
pod之间的通信:
- 同一节点的pod之间通过
cni网桥转发数据包。 - 不同节点的pod之间的通信需要
网络插件支持。
pod和service通信:通过 iptables 或 ipvs 实现通信,ipvs取代不了iptables,因为ipvs只能做负载均衡,而做不了nat转换。
pod和外网通信:iptables的MASQUERADE
Service与集群外部客户端的通信: Ingress、 NodePort、 Loadbalancer
1. service与service代理
Service:Kubernetes Service 定义了这样一种抽象:逻辑上的一组 Pod,一种可以访问它们的策略 —— 通常称为微服务。
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。 kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式,而不是 ExternalName 的形式。
1.1 userspace 代理模式
这种模式,
kube-proxy会监视 Kubernetes 控制平面对 Service 对象和 Endpoints 对象的添加和移除操作。 对每个 Service,它会在本地 Node 上打开一个端口(随机选择)。 任何连接到“代理端口”的请求,都会被代理到 Service 的后端Pods中的某个上面(如 Endpoints 所报告的一样)。 使用哪个后端 Pod,是 kube-proxy 基于 SessionAffinity 来确定的。
最后,它配置 iptables 规则,捕获到达该 Service 的 clusterIP(是虚拟 IP) 和 Port 的请求,并重定向到代理端口,代理端口再代理请求到后端Pod。
默认情况下,用户空间模式下的 kube-proxy 通过轮转算法选择后端。
1.2 iptables 代理模式
这种模式,
kube-proxy会监视 Kubernetes 控制节点对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会配置 iptables 规则,从而捕获到达该 Service 的clusterIP和端口的请求,进而将请求重定向到 Service 的一组后端中的某个 Pod 上面。 对于每个 Endpoints 对象,它也会配置 iptables 规则,这个规则会选择一个后端组合。
默认的策略是,kube-proxy 在 iptables 模式下随机选择一个后端。
使用 iptables 处理流量具有较低的系统开销,因为流量由 Linux netfilter 处理, 而无需在用户空间和内核空间之间切换。 这种方法也可能更可靠。
如果 kube-proxy 在 iptables 模式下运行,并且所选的第一个 Pod 没有响应, 则连接失败。 这与用户空间模式不同:在这种情况下,kube-proxy 将检测到与第一个 Pod 的连接已失败, 并会自动使用其他后端 Pod 重试。
你可以使用 Pod 就绪探测器 验证后端 Pod 可以正常工作,以便 iptables 模式下的 kube-proxy 仅看到测试正常的后端。 这样做意味着你避免将流量通过 kube-proxy 发送到已知已失败的 Pod。
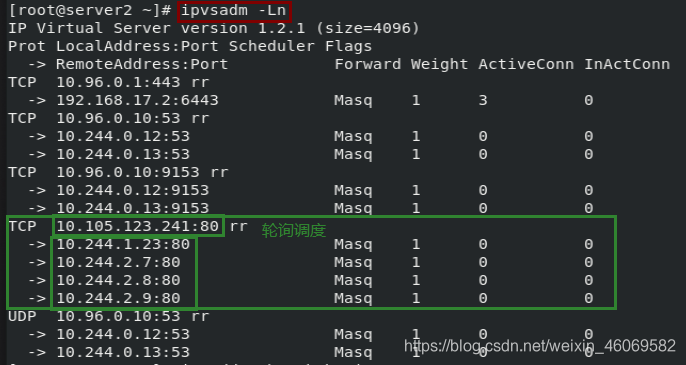
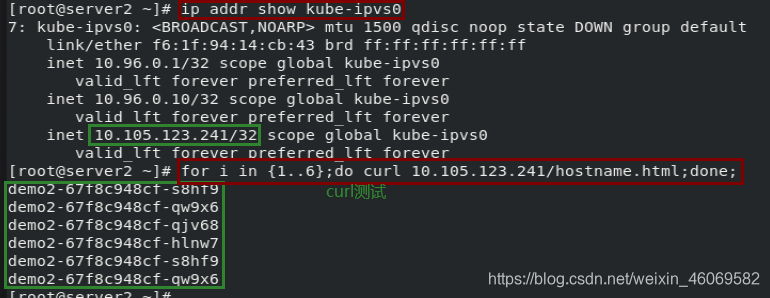
1.3 IPVS模式
在
ipvs模式下,kube-proxy 监视 Kubernetes 服务和端点,调用netlink接口相应地创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。 该控制循环可确保IPVS 状态与所需状态匹配。访问服务时,IPVS 将流量定向到后端Pod之一。
IPVS代理模式基于类似于 iptables 模式的 netfilter 挂钩函数, 但是使用哈希表作为基础数据结构,并且在内核空间中工作。 这意味着,与 iptables 模式下的 kube-proxy 相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。 与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
IPVS 提供了更多选项来平衡后端 Pod 的流量。
要在 IPVS 模式下运行 kube-proxy,必须在启动 kube-proxy 之前使 IPVS 在节点上可用。
当 kube-proxy 以 IPVS 代理模式启动时,它将验证 IPVS 内核模块是否可用。 如果未检测到 IPVS 内核模块,则 kube-proxy 将退回到以 iptables 代理模式运行。
- 所有节点安装:
yum install -y ipvsadm
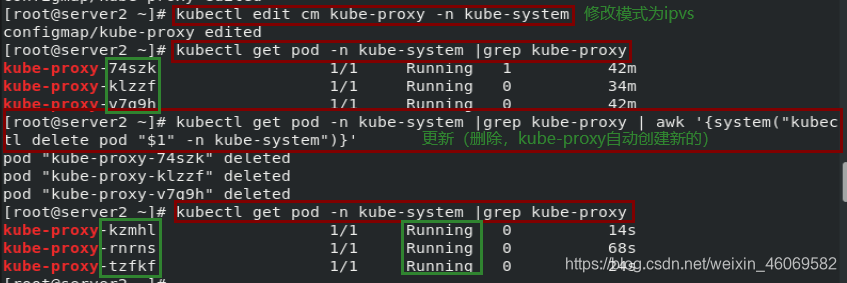
- master端修改为ipvs模式
kubectl edit cm kube-proxy -n kube-system
mode: "ipvs"
- master端更新kube-proxy
kubectl get pod -n kube-system |grep kube-proxy | awk '{system("kubectl delete pod "$1" -n kube-system")}'
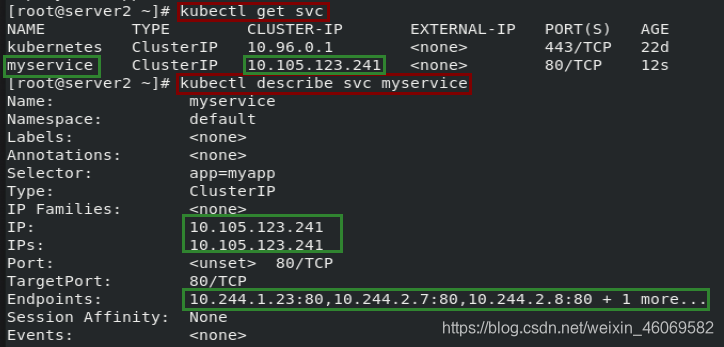
创建ipvs模式的service示例
1.编写资源清单(如下)
vim demo.yml
2.创建
kubectl apply -f demo.yml
# demo.yml
---
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 80
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo2
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:v2
2. 无头服务(Headless Services)
clusterIP: None:Headless Service不需要分配一个IP, 而是直接以DNS记录的方式解析出被代理Pod的IP地址。
对这无头 Service 并不会分配 Cluster IP,kube-proxy 不会处理它们, 而且平台也不会为它们进行负载均衡和路由。 DNS 如何实现自动配置,依赖于 Service 是否定义了选择算符。
域名格式:
$(servicename).$(namespace).svc.cluster.local
示例
vim demo.yml
kubectl apply -f demo.yml
# demo.yml
---
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 80
clusterIP: None
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo2
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:v2
3. 发布服务
Kubernetes ServiceTypes 允许指定你所需要的 Service 类型,默认是 ClusterIP。
3.1 ClusterIP 类型(默认)
通过集群的内部 IP 暴露服务,选择该值时服务只能够在集群内部访问。 这也是默认的 ServiceType。
3.2 NodePort 类型
通过每个节点上的 IP 和静态端口(NodePort)暴露服务。 NodePort 服务会路由到自动创建的 ClusterIP 服务。 通过请求 <节点 IP>:<节点端口>,你可以从集群的外部访问一个 NodePort 服务。
示例
创建:kubectl apply -f demo.yml

# demo.yml
---
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 80
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo2
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:v2
3.3 LoadBalancer 类型
LoadBalancer在【Linux39-5】详细解释
使用云提供商的负载均衡器向外部暴露服务。 外部负载均衡器可以将流量路由到自动创建的 NodePort 服务和 ClusterIP 服务上。
LoadBalancer示例:本例没有云主机,所以状态为 pending
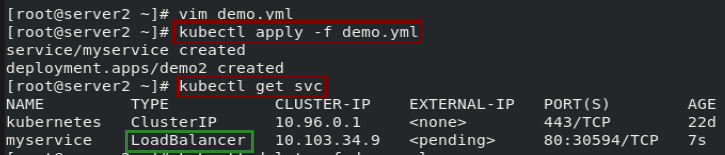
# demo.yml
---
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
之后的资源清单与NodePort中相同
3.4 ExternalName 类型
通过返回 CNAME 和对应值,可以将服务映射到 externalName 字段的内容(例如,foo.bar.example.com)。 无需创建任何类型代理。
示例

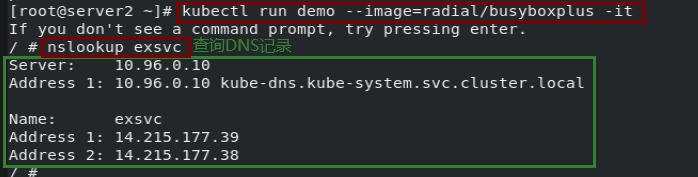
# exsvc.yml
apiVersion: v1
kind: Service
metadata:
name: exsvc
spec:
type: ExternalName
externalName: www.baidu.com
3.5 引入外部IP(externalIPs)
如果外部的 IP 路由到集群中一个或多个 Node 上,Kubernetes Service 会被暴露给这些 externalIPs。 通过外部 IP(作为目的 IP 地址)进入到集群,打到 Service 的端口上的流量, 将会被路由到 Service 的 Endpoint 上。 externalIPs 不会被 Kubernetes 管理,它属于集群管理员的职责范畴。
示例

---
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 80
externalIPs:
- 172.25.17.100
之后的资源清单与NodePort中相同
4. 集群网络
重点为Pod 间通信
4.1 k8s 网络模型
每一个 Pod 都有它自己的IP地址,这就意味着你不需要显式地在每个 Pod 之间创建链接, 你几乎不需要处理容器端口到主机端口之间的映射。 这将创建一个干净的、向后兼容的模型,在这个模型里,从端口分配、命名、服务发现、 负载均衡、应用配置和迁移的角度来看,Pod 可以被视作虚拟机或者物理主机。
Kubernetes 对所有网络设施的实施,都需要满足以下的基本要求(除非有设置一些特定的网络分段策略):
-
节点上的 Pod 可以不通过 NAT 和其他任何节点上的 Pod 通信
-
节点上的代理(比如:系统守护进程、kubelet) 可以和节点上的所有Pod通信(备注:仅针对那些支持 Pods 在主机网络中运行的平台(比如:Linux)
-
那些运行在节点的主机网络里的 Pod 可以不通过 NAT 和所有节点上的 Pod 通信
这个模型不仅不复杂,而且还和 Kubernetes 的实现廉价的从虚拟机向容器迁移的初衷相兼容, 如果你的工作开始是在虚拟机中运行的,你的虚拟机有一个 IP , 这样就可以和其他的虚拟机进行通信,这是基本相同的模型。
Kubernetes 的 IP 地址存在于 Pod 范围内 - 容器共享它们的网络命名空间 - 包括它们的 IP 地址和 MAC 地址。 这就意味着 Pod 内的容器都可以通过 localhost 到达各个端口。 这也意味着 Pod 内的容器都需要相互协调端口的使用,但是这和虚拟机中的进程似乎没有什么不同, 这也被称为“一个 Pod 一个 IP” 模型。
如何实现这一点是正在使用的容器运行时的特定信息。
也可以在 node 本身通过端口去请求你的 Pod (称之为主机端口), 但这是一个很特殊的操作。转发方式如何实现也是容器运行时的细节。 Pod 自己并不知道这些主机端口是否存在。
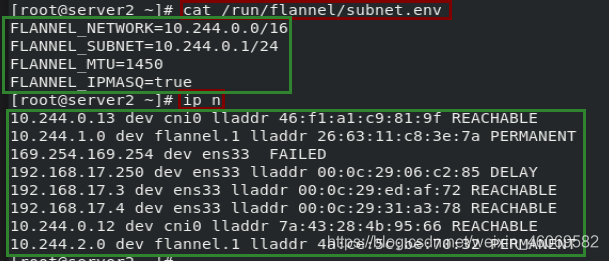
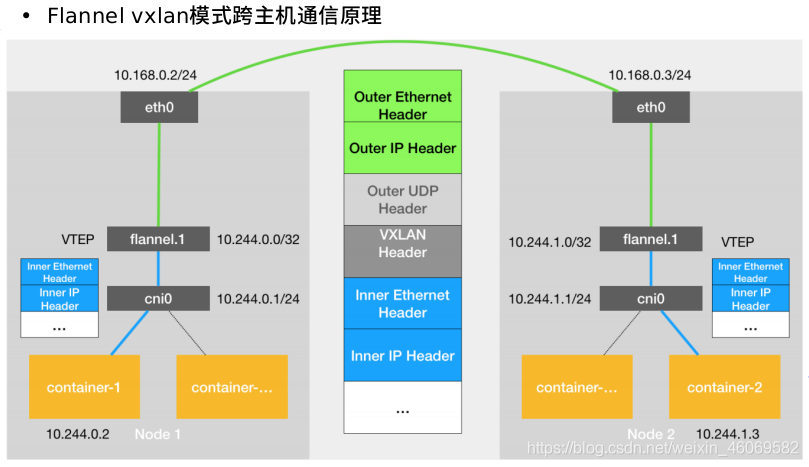
4.2 Flannel 模型
- VXLAN, 即Virtual Extensible LAN (虚拟可扩展局域网),是Linux本身支持的一种网络虚拟化技术。VXLAN可以完全在内核态实现封装和解封装工作,从而通过“隧道”机制,构建出覆盖网络(Overlay Network)。
- VTEP:VXLAN Tunnel End Point (虚拟隧道端点),在Flannel中VNI的默认值是1,这也是为什么宿主机的VTEP设备都叫flannel.1的原因。
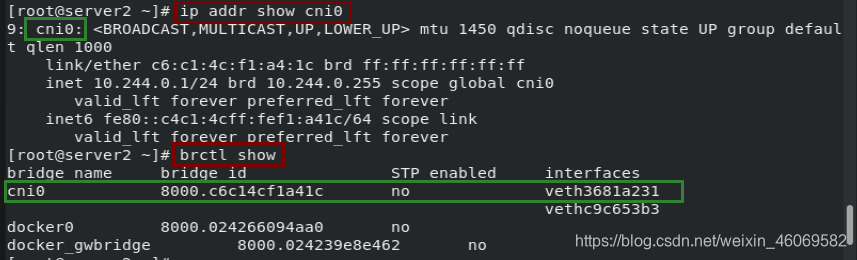
- Cni0:网桥设备,每创建一个pod都会创建一对veth pair。其中一端是pod中的eth0,另一端是Cni0网桥中的端口(网卡)。
- Flannel.1: TUN设备(虚拟网卡),用来进行vxlan报文的处理(封包和解包)。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端。
- Flanneld:flannel在每个主机中运行flanneld作为agent, 它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel. 1设备提供封装数据时必要的mac、ip等 网络数据信息。
4.3 Fannel工作原理

4.4 Fannel 分类
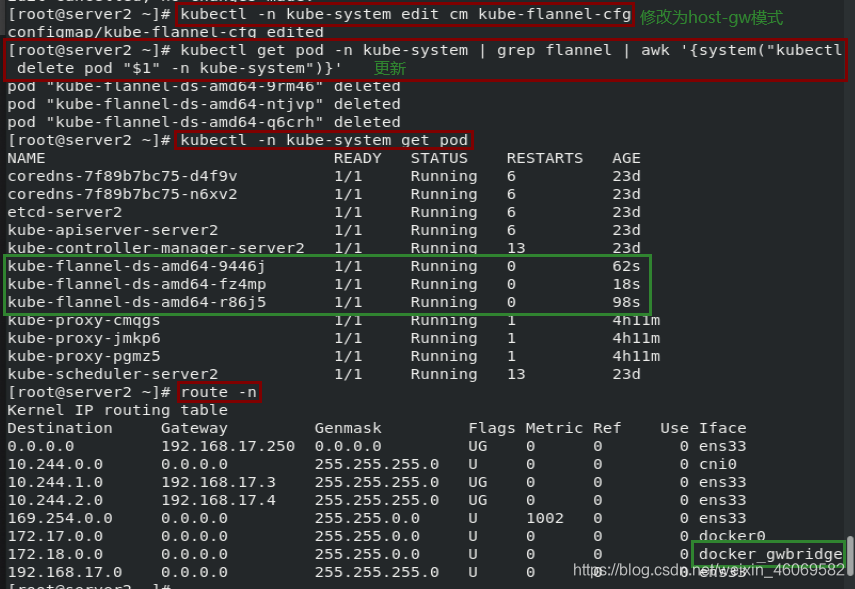
模式1: host-gw:主机网关,性能好,但只能在二层网络中,不支持跨网络,如果有成千上万的Pod,容易产生广播风暴,不推荐
# 修改为host-gw
1.修改
kubectl -n kube-system edit cm kube-flannel-cfg
--->"Type": "host-gw"
2.更新
kubectl get pod -n kube-system | grep flannel | awk '{system("kubectl delete pod "$1" -n kube-system")}'
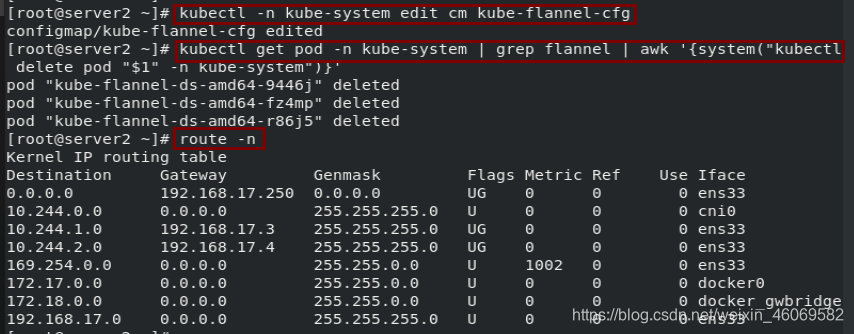
模式2: Vxlan
1.vxlan:报文封装,默认
2.Directrouting:直接路由,跨网段使用vxlan,同网段使用host-gw模式。
# 修改为vxlan Directrouting
1.修改
kubectl -n kube-system edit cm kube-flannel-cfg
---> "Type": "vxlan",
---> "Directrouting": true
2.更新
kubectl get pod -n kube-system | grep flannel | awk '{system("kubectl delete pod "$1" -n kube-system")}'
模式3: UDP:性能差,不推荐