最近想入门推荐算法,下了许多源码算法,跑了跑。又觉得很多代码理解不同,于是想要从头开始学起。
首先是推荐算法有许多是基于机器学习的,所以我就从小B站上找了些学习视频看。
下面这个尚硅谷机器学习和推荐系统项目实战教程感觉挺好的,由于机器学习基础有了,所以我直接从算法、项目开始看起。顺便想通过博客记录一下给自己复习,具体内容可以直接点链接进去学习。
https://www.bilibili.com/video/BV1R4411N78S?p=34
推荐算法入门
1. 常用推荐算法分类:
① 按系统是否实时可以划分为:实时推荐系统、离线推荐系统。
② 基于人口统计学的推荐与用户画像可划分为:根据不同用户的标签(是否个性化)——用户画像
(这里根据用户的角度,可以根据用户近期对某类物品的点击/购买/…划分标签,还可以根据用户定位给以推荐)
③ 基于内容的推荐与特征工程:根据统计化标签(物品被用户划分标签、有专门人员给用户划分标签)、物品本身的热度。
④ 基于模型划分:有一堆的用户特征(喜欢的类别、点击量、购买量……)一堆物品特征(例如热度、分类……)丢给机器学习,根据特征分析给用户推荐哪些物品。
⑤ 基于数据源划分:基于用户信息②、基于内容③(特征工程)、基于行为数据④(协同过滤)
2. 基于人口统计学的推荐算法
实际上,根据系统本身数据,我们可以统计系统中用户的不同属性/类别。例如年龄、性别、兴趣、性格……然后就可以对用户进行分类,加入用户A和用户B 是同一类,那么用户A喜欢物品1,用户B就也有可能喜欢物品1。
所以基于人口统计学的推荐算法,最重要的信息就是要大量收集到用户的信息,然后通过算法发现用户之间的相关程度。
用户信息可以划分为,有明确含义和没有明确含义的。
例如,假如有个短视频APP使用人口统计学的推荐算法系统。那么我们设定系统中,通过聚类算法发现喜欢半夜刷视频的人普遍喜欢看吃播,那就给他们打上爱看美食的标签。然后就给他们推荐美食视频。有明确含义的就是,用户在个人信息中表明他的兴趣爱好是看小姐姐跳舞,那么系统就根据标签给他推荐小姐姐跳舞的视频,或者其他跟小姐姐跳舞相关联的视频。(根据预设规则或者模型规定)
用户信息标签化的过程一般又称为用户画像。(UserProfiling)
用户画像就是企业通过收集与分析消费者社会属性、生活习惯、消费行为等主要信息的数据之后,完美地抽象出一个用户的商品全貌作是企业应用大数据技术的基本方式。
用户画像为企业提供了足够的信息基础,能够帮助企业快速找到精准用户群体以及用户需求等更为广泛的反馈信息。
3. 基于内容的推荐算法
每种物品都有本身的标签。比如衣服会有各种风格属性,例如JK,潮牌,日系,韩系……假如用户A喜欢潮牌和日系的服饰,那么我们肯定推荐一些和潮牌、日系相关的产品。
Content-based Recommendations(CB) 根据推荐物品或内容的元数据,发现物品相关性。再基于用户过去的喜好记录(或标签),为用户推荐相似的物品。
通过抽取物品内在或外在的特征值,实现相似度计算。
将用户个人信息的特征(基于喜好记录或者预设兴趣标签),和物品的特征相匹配,就能得到用户对物品感兴趣的程度。
但是由于一个物品的特征有非常的多,其中有些特征并不能为我们推荐提供帮助。所以我们可以根据物品的本身特征,提取有用的信息(打标签)。
打标签的方法有:基于模型:可以通过模型进行特征提取,输出分类标签。基于人工:人工对物品打标签。(有些模型提取的标签并不是很好。)
基于内容的推荐算法又可以分成两种:
① 对于物品的特征提取——打标签(tag)——专家标签(PGC)、用户自定义标签(UGC)、降维分析数据,提取隐语义标签(LFM)
② 对于文本信息的特征提取——关键词——分词、语义处理和情感分析(NLP)、潜在语义分析(LSA)
(1)基于内容推荐系统的高层次结构
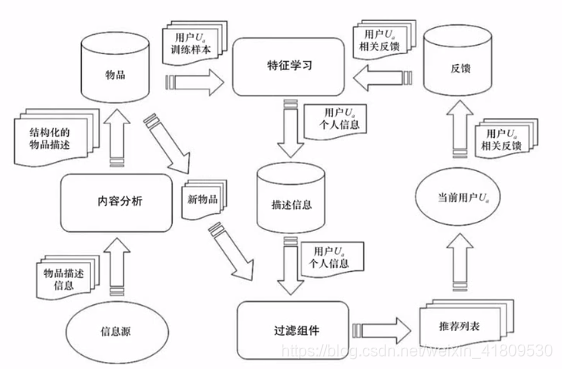
① 信息源就是我们整个系统中的物品信息,又非常多的物品以及特征内容。
② 内容分析的本质就是数据预处理,数据清洗,选择有用数据等。(也就是进行特征工程,筛选出特征学习中有用的信息)
③ 特征学习的本质就是提取物品的特征和用户反馈的信息作匹配——即物品特征:用户特征:匹配度。
④ 再经过过滤组件对物品进行筛选,得到推荐列表,然后推荐给用户。
⑤ 用户得到推荐列表后,我们又可以将用户观看推荐物品后的信息反馈回模型进行重复学习,更新推荐列表。(用户反馈的过程也要经过特征工程筛选出有用的反馈信息)
特征工程
特征:数据中抽取出来对结果预测有用的信息。
特征的个数就是数据的观测维度。
特征工程是使用专业背景知识和技巧处理数据,使得特征能再机器学习算法上发挥更好的作用的过程。
特征工程一般包括特征清洗(采用、清洗异常样本),特征处理和特征选择。
(2) 基于UGC的推荐
用户用标签来描述对物品的看法,所以用户生成标签
(UGC)是联系用户和物品的纽带,也是反应用户兴趣的重要数据源。
用户打标签的行为——(用户,物品,标签),即系统中的一天记录为(u,i,b)代表用户u给物品i打上了标签b。
问题 1 :一个物品可能有多个标签,(不能只打一个标签);一个物品可能得到多个标签(一千个人眼里有一千个哈姆雷特)
解决:
- 统计每个用户最常用的标签。
- 对于每个标签,统计被打过这个标签次数最多的物品。
- 对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门的物品,推荐给他。
- 所以就可以通过公司得到用户u对物品i的兴趣公式:
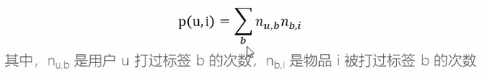
问题 2 :这种方法倾向于给热门标签、热门商品笔记打的权重。容易使得系统上热门的东西持续在热门上,推荐给用户。个性化、新颖度降低。
引申问题:不同的文章,出现词频最多的可能都是些语气助词,介词……但是我们希望根据不同文章的文字能够提取出文章内容的关键成分。
解决:TF-IDF 词频-逆文档频率。
词频 - 逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)是一种用于咨询检索与文本挖掘的常用加权技术。
TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时回随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有更好的类别区分能力,适合用来分类。
TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
(3)TF-IDF对基于UGC推荐的改进
基本思想:为了避免热门标签和热门物品得到更多的权重,需要对热门的东西进行惩罚。即所有物品标签出现的频率加上逆文档频率的惩罚项。
使得热门程度越高,兴趣度就会成反比降低。
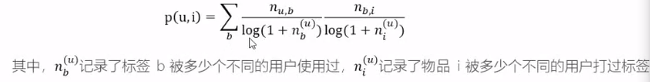
4.基于协同过滤的推荐算法(Collaborative Filtering,CF)
- 基于近邻的协同过滤:① 基于用户(User-CF)、② 基于物品(Item-CF)
- 基于模型的协同过滤:① 奇异值分解(SVD)、② 潜在语义分析(LSA)、③ 支撑向量机(SVM)
基于内容主要利用用户评价过的物品的内容,它只能根据用户本身对物品的感兴趣程度作推荐。但是CF方法还可以利用其他用户评分过的物品内容。(基于用户的行为)
这就解决了基于内容推荐算法中的一些局限性:
① 物品内容不完全或者难以获得时,依然可以通过其他用户的反馈给出推荐。
② CF基于用户之间对物品的评价质量,避免了CB仅依赖内容可能造成的对物品质量判定的干扰。
③ CF推荐不受内容限制,只要其他类似用户给出了对不同物品的兴趣,CF就可以给用户推荐出内容差异很大的物品,(基于某种内在联系)
举个例子:用户A喜欢的东西和不喜欢的东西和用户B都很相似,那么即使有些东西用户A喜欢,用户B不知道喜欢不喜欢,但是系统还是会因为用户A和用户B的行为相似推荐给用户B。
CF存在的问题:无法解决冷启动的问题。即如果系统一开始没有用户行为数据,本身也没有数据,那么就无法推荐。因此一开始可能基于内容,后面用CF。两种算法相结合用。