1. 推荐系统的意义
” role=”presentation” style=”position: relative;”>互联网大爆炸时期的信息过载的解决方案:
” role=”presentation” style=”position: relative;”>对用户而言:找到好玩的东西,帮助决策,发现新鲜事物。
” role=”presentation” style=”position: relative;”>对商家而言:提供个性化服务,提高信任度和粘性,增加营收。
2. 推荐系统的构成
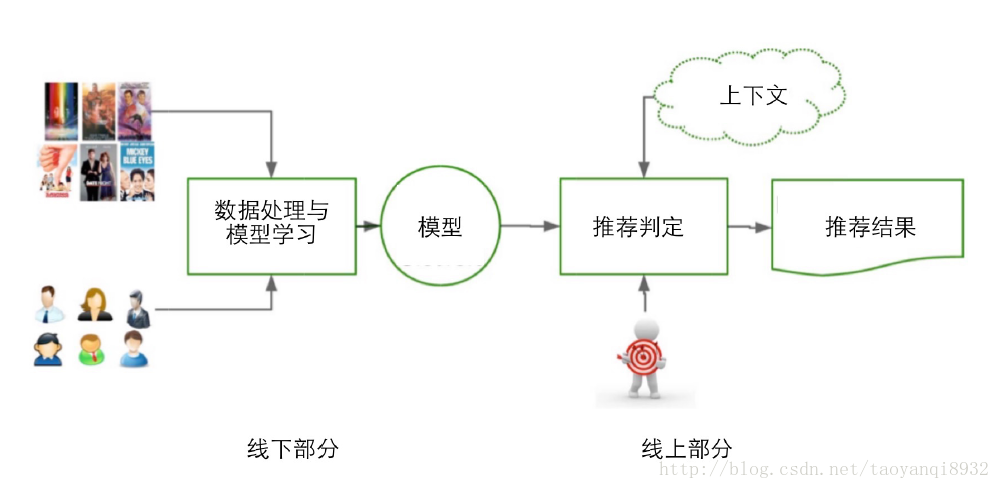
” role=”presentation” style=”position: relative;”>前台的展示页面,后台的日志系统,推荐算法等部分组成,如下图所示:
3. 推荐系统的评测
3.1 离线实验
即线下的部分,用于训练模型
优点:
不需要有对实际系统的控制权;
不需要用户参与体验;
速度快,可以测试大量算法;
缺点:
无法计算商业上关心的指标;
扫描二维码关注公众号,回复: 1464062 查看本文章
离线实验的指标和商业指标存在差距;
3.2 用户调查
优点:
获得很多体现用户主观感受的指标;
实验风险很低,出现错误后很容易弥补;
缺点:
1.招募测试用户代价较大;
2.设计双盲实验困难,在测试环境下收集的测试指标可能在真实环境下无法重现;
一般一个新的推荐算法最终上线都需要经历以上3个实验:
1) 通过离线实验证明它在很多离线指标上优于现有的算法;
2) 通过用户调查确定它的用户满意度不低于现有的算法;
3) 通过在线的AB测试确定它在我们关心的指标上优于现有的算法;
4 推荐系统的评估
4.1 准确度
RMSE(均方根误差),MAE(平均绝对误差)
Top N推荐
” role=”presentation” style=”position: relative;”>主要为:准确率precison,召回率recall指标
” role=”presentation” style=”position: relative;”>准确率说的是推荐的10条信息中用户真正感兴趣的条数,召回率说的是用户真正感兴趣的你推荐条数占比。
下图中R(U)为推荐,T(U)为用户选择的:
” role=”presentation” style=”position: relative;”>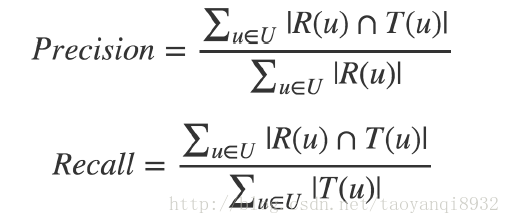
关于更多可以参考:深度探讨机器学习中的ROC和PR曲线
4.2 覆盖率
” role=”presentation” style=”position: relative;”>推荐出来的物品占总物品集合的比例;
4.3 多样性
” role=”presentation” style=”position: relative;”>推荐列表中物品两两之间的差异性;
4.4 新颖性,惊喜度,实时性,商业目标等
5. 推荐算法
5.1 基于内容的推荐算法
优点:
- 基于用户喜欢的物品的属性/内容进行推荐
- 需要分析内容,无需考虑用户与用户之间的关联
缺点:
- 要求内容容易抽取成有意义的特征,特征内容具有良好的结构性;
- 不能很好的处理一词多义和一义多词带来的语义问题;
步骤:
- 对于要推荐的物品建立一份特征
- 对于用户喜欢的物品建立一份特征
- 计算相似度
比如说在文档中常用的余弦相似度:
5.2 协同过滤
5.2.1 基于用户的协同过滤(UserCF)
算法步骤:
- 找到和目标用户兴趣相似的用户集合,计算用户的相似度;
- 找到“近邻”,对近邻在新物品的评价(打分)加权推荐
下图一个非常直观的例子:

兔子和米老鼠最相似,则给米老鼠推荐兔子喜欢的物品:
5.2.2 基于物品的协同过滤(ItemCF)
算法步骤:
- 对于有相同用户交互的物品,计算物品相似度;
- 找到物品“近邻”,进行推荐
相似性的度量:

协同过滤的对比:
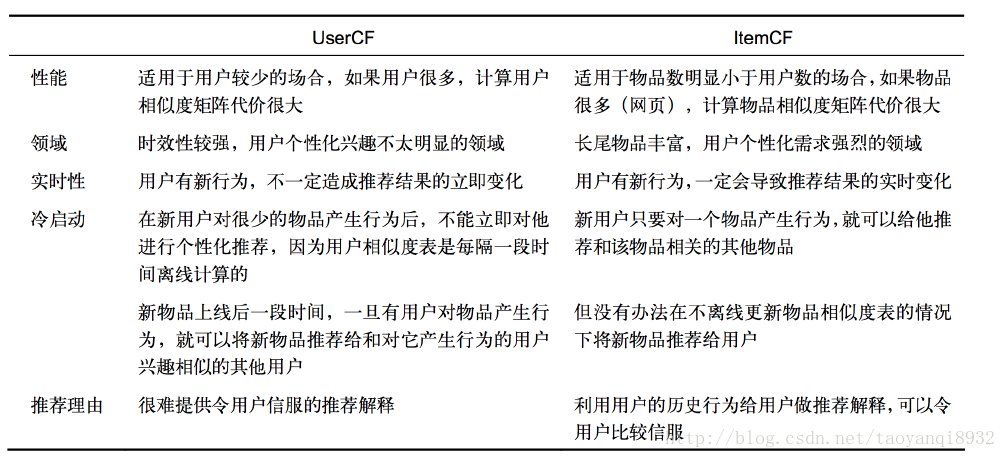
其中ItemCF一定情况下可以缓解冷启动的现象,而且其更加稳定,而且其更有说服了。
协同过滤优点
- 基于用户行为,因此对推荐内容无需先验知识
- 只需要用户和商品关联矩阵即可,结构简单
- 在用户行为丰富的情况下,效果好
协同过滤缺点
- 需要大量的显性/隐性用户行为
- 需要通过完全相同的商品关联,相似的不行
- 假定用户的兴趣完全取决于之前的行为,而和当前上下文环境无关
- 在数据稀疏的情况下受影响。可以考虑二度关联。
冷启动问题
对于新用户
- 所有推荐系统对于新用户都有这个问题
- 推荐非常热门的商品
- 收集一些信息 在用户注册的时候收集一些信息
- 在用户注册完之后,用一些互动游戏等确定喜欢与不喜欢
对于新商品
- 根据本身的属性,求与原来商品的相似度。
- Item-based协同过滤可以推荐出去。
5.3 基于矩阵分解的推荐算法
” role=”presentation” style=”position: relative;”>原理:根据已有的评分矩阵(非常稀疏),分解为低维的用户特征矩阵(评分者对各个因子的喜好程度)以及商品特征矩阵(商品包含各个因子的程度),最后再反过来分析数据(用户特征矩阵与商品特征矩阵相乘得到新的评分矩阵)得出预测结果;

SVD
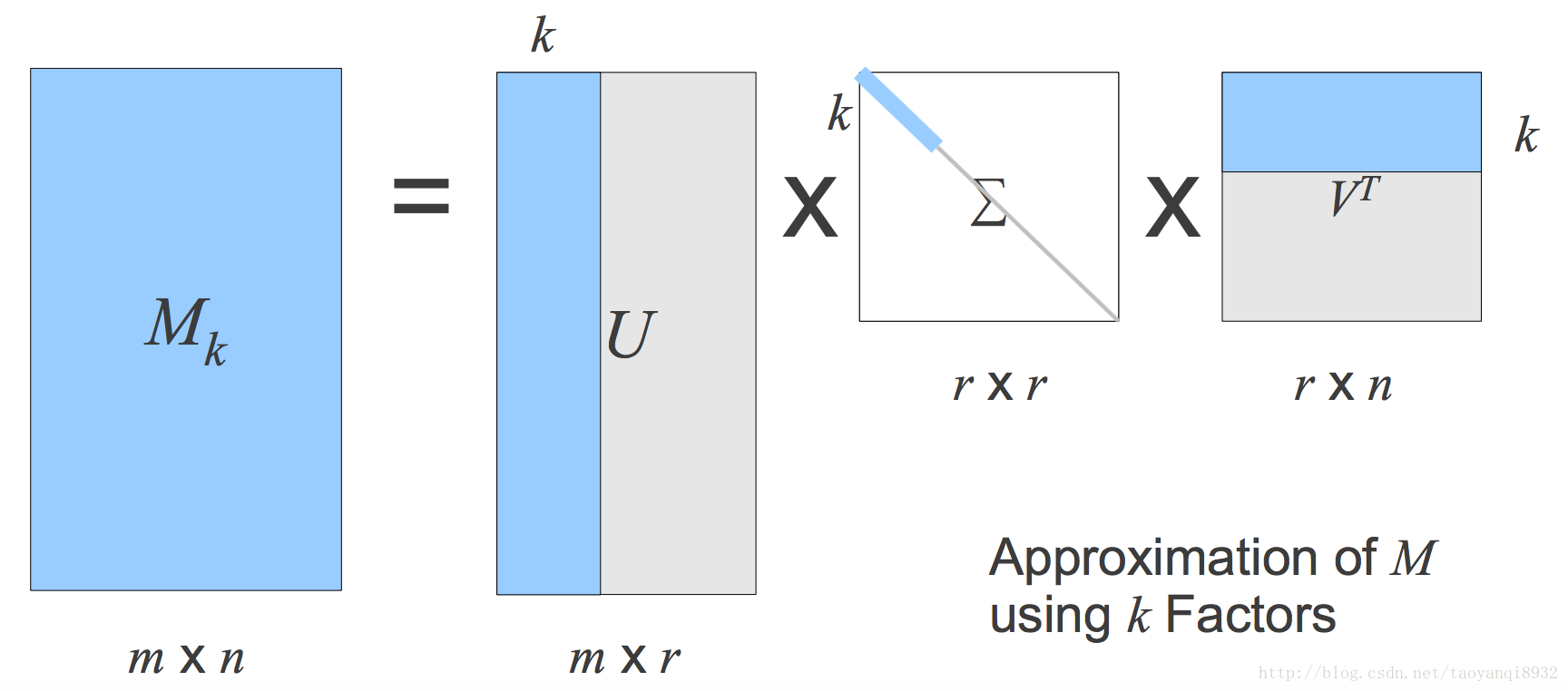
” role=”presentation” style=”position: relative;”>SVD的时间复杂度为O(m^3),M经常是稀疏且有空缺值的,简单的做法是将空缺值补上随机值,那么就可以svd分解了,但是推荐效果一般,因此一般将该问题转化为优化问题;同时原始矩阵中0很多,不宜用0填补。
矩阵分解

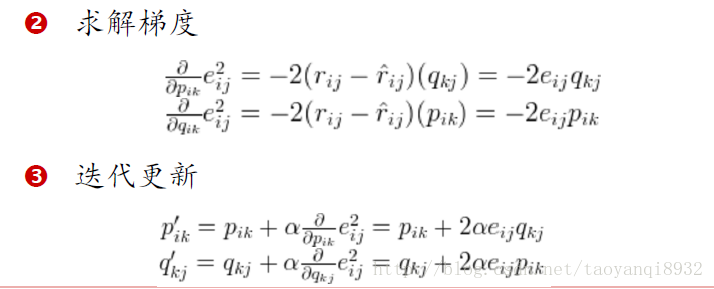
即给定一个损失函数然后最优化的过程
5.4 混合推荐
(1)加权的混合: 用线性公式将几种不同的推荐按照一定权重组合起来,具体权重的值需要在测试数据集上反复实验,从而达到最好的推荐效果;
(2)切换的混合:对于不同的情况(数据量,系统运行状况,用户和物品的数目等),推荐策略可能有很大的不同,那么切换的混合方式,就是允许在不同的情况下,选择最为合适的推荐机制计算推荐;
(3)分区的混合:采用多种推荐机制,并将不同的推荐结果分不同的区显示给用户;其实,Amazon,当当网等很多电子商务网站都是采用这样的方式,用户可以得到很全面的推荐,也更容易找到他们想要的东西;
(4)分层的混合:采用多种推荐机制,并将一个推荐机制的结果作为另一个的输入,从而综合各个推荐机制的优缺点,得到更加准确的推荐;
参考资料:
1. 《推荐系统原理与应用》七月在线
2. 推荐系统
<link rel="stylesheet" href="http://csdnimg.cn/release/phoenix/production/markdown_views-68a8aad09e.css">
</div>
1. 推荐系统的意义
” role=”presentation” style=”position: relative;”>互联网大爆炸时期的信息过载的解决方案:
” role=”presentation” style=”position: relative;”>对用户而言:找到好玩的东西,帮助决策,发现新鲜事物。
” role=”presentation” style=”position: relative;”>对商家而言:提供个性化服务,提高信任度和粘性,增加营收。
2. 推荐系统的构成
” role=”presentation” style=”position: relative;”>前台的展示页面,后台的日志系统,推荐算法等部分组成,如下图所示:
3. 推荐系统的评测
3.1 离线实验
即线下的部分,用于训练模型
优点:
不需要有对实际系统的控制权;
不需要用户参与体验;
速度快,可以测试大量算法;
缺点:
无法计算商业上关心的指标;
离线实验的指标和商业指标存在差距;
3.2 用户调查
优点:
获得很多体现用户主观感受的指标;
实验风险很低,出现错误后很容易弥补;
缺点:
1.招募测试用户代价较大;
2.设计双盲实验困难,在测试环境下收集的测试指标可能在真实环境下无法重现;
一般一个新的推荐算法最终上线都需要经历以上3个实验:
1) 通过离线实验证明它在很多离线指标上优于现有的算法;
2) 通过用户调查确定它的用户满意度不低于现有的算法;
3) 通过在线的AB测试确定它在我们关心的指标上优于现有的算法;
4 推荐系统的评估
4.1 准确度
RMSE(均方根误差),MAE(平均绝对误差)
Top N推荐
” role=”presentation” style=”position: relative;”>主要为:准确率precison,召回率recall指标
” role=”presentation” style=”position: relative;”>准确率说的是推荐的10条信息中用户真正感兴趣的条数,召回率说的是用户真正感兴趣的你推荐条数占比。
下图中R(U)为推荐,T(U)为用户选择的:
” role=”presentation” style=”position: relative;”>
关于更多可以参考:深度探讨机器学习中的ROC和PR曲线
4.2 覆盖率
” role=”presentation” style=”position: relative;”>推荐出来的物品占总物品集合的比例;
4.3 多样性
” role=”presentation” style=”position: relative;”>推荐列表中物品两两之间的差异性;
4.4 新颖性,惊喜度,实时性,商业目标等
5. 推荐算法
5.1 基于内容的推荐算法
优点:
- 基于用户喜欢的物品的属性/内容进行推荐
- 需要分析内容,无需考虑用户与用户之间的关联
缺点:
- 要求内容容易抽取成有意义的特征,特征内容具有良好的结构性;
- 不能很好的处理一词多义和一义多词带来的语义问题;
步骤:
- 对于要推荐的物品建立一份特征
- 对于用户喜欢的物品建立一份特征
- 计算相似度
比如说在文档中常用的余弦相似度:
5.2 协同过滤
5.2.1 基于用户的协同过滤(UserCF)
算法步骤:
- 找到和目标用户兴趣相似的用户集合,计算用户的相似度;
- 找到“近邻”,对近邻在新物品的评价(打分)加权推荐
下图一个非常直观的例子:
兔子和米老鼠最相似,则给米老鼠推荐兔子喜欢的物品:
5.2.2 基于物品的协同过滤(ItemCF)
算法步骤:
- 对于有相同用户交互的物品,计算物品相似度;
- 找到物品“近邻”,进行推荐
相似性的度量:
协同过滤的对比:
其中ItemCF一定情况下可以缓解冷启动的现象,而且其更加稳定,而且其更有说服了。
协同过滤优点
- 基于用户行为,因此对推荐内容无需先验知识
- 只需要用户和商品关联矩阵即可,结构简单
- 在用户行为丰富的情况下,效果好
协同过滤缺点
- 需要大量的显性/隐性用户行为
- 需要通过完全相同的商品关联,相似的不行
- 假定用户的兴趣完全取决于之前的行为,而和当前上下文环境无关
- 在数据稀疏的情况下受影响。可以考虑二度关联。
冷启动问题
对于新用户
- 所有推荐系统对于新用户都有这个问题
- 推荐非常热门的商品
- 收集一些信息 在用户注册的时候收集一些信息
- 在用户注册完之后,用一些互动游戏等确定喜欢与不喜欢
对于新商品
- 根据本身的属性,求与原来商品的相似度。
- Item-based协同过滤可以推荐出去。
5.3 基于矩阵分解的推荐算法
” role=”presentation” style=”position: relative;”>原理:根据已有的评分矩阵(非常稀疏),分解为低维的用户特征矩阵(评分者对各个因子的喜好程度)以及商品特征矩阵(商品包含各个因子的程度),最后再反过来分析数据(用户特征矩阵与商品特征矩阵相乘得到新的评分矩阵)得出预测结果;
SVD
” role=”presentation” style=”position: relative;”>SVD的时间复杂度为O(m^3),M经常是稀疏且有空缺值的,简单的做法是将空缺值补上随机值,那么就可以svd分解了,但是推荐效果一般,因此一般将该问题转化为优化问题;同时原始矩阵中0很多,不宜用0填补。
矩阵分解
即给定一个损失函数然后最优化的过程
5.4 混合推荐
(1)加权的混合: 用线性公式将几种不同的推荐按照一定权重组合起来,具体权重的值需要在测试数据集上反复实验,从而达到最好的推荐效果;
(2)切换的混合:对于不同的情况(数据量,系统运行状况,用户和物品的数目等),推荐策略可能有很大的不同,那么切换的混合方式,就是允许在不同的情况下,选择最为合适的推荐机制计算推荐;
(3)分区的混合:采用多种推荐机制,并将不同的推荐结果分不同的区显示给用户;其实,Amazon,当当网等很多电子商务网站都是采用这样的方式,用户可以得到很全面的推荐,也更容易找到他们想要的东西;
(4)分层的混合:采用多种推荐机制,并将一个推荐机制的结果作为另一个的输入,从而综合各个推荐机制的优缺点,得到更加准确的推荐;
参考资料:
1. 《推荐系统原理与应用》七月在线
2. 推荐系统
<link rel="stylesheet" href="http://csdnimg.cn/release/phoenix/production/markdown_views-68a8aad09e.css">
</div>