一、什么是推荐系统?
推荐系统是啥?
如果你是个多年电商(剁手)党,你会说是这个:
如果你是名充满文艺细胞的音乐发烧友,你会答这个:
没错,猜你喜欢、个性歌单,这些都是推荐系统的输出内容。从这些我们就可以总结出,推荐系统到底是做什么的。
目的1. 帮助用户找到想要的商品(新闻/音乐/……),发掘长尾
帮用户找到想要的东西,谈何容易。商品茫茫多,甚至是我们自己,也经常点开淘宝,面对眼花缭乱的打折活动不知道要买啥。在经济学中,有一个著名理论叫长尾理论(The Long Tail)。
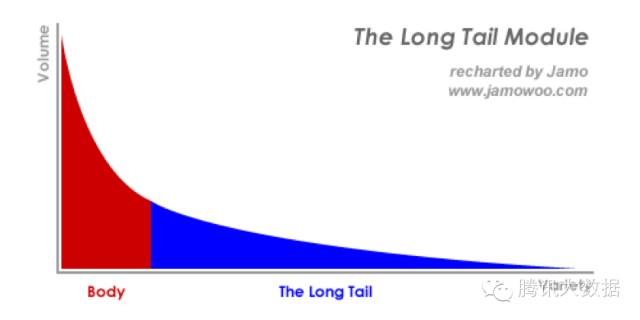
套用在互联网领域中,指的就是最热的那一小部分资源将得到绝大部分的关注,而剩下的很大一部分资源却鲜少有人问津。这不仅造成了资源利用上的浪费,也让很多口味偏小众的用户无法找到自己感兴趣的内容。
目的2. 降低信息过载
互联网时代信息量已然处于爆炸状态,若是将所有内容都放在网站首页上用户是无从阅读的,信息的利用率将会十分低下。因此我们需要推荐系统来帮助用户过滤掉低价值的信息。
目的3. 提高站点的点击率/转化率
好的推荐系统能让用户更频繁地访问一个站点,并且总是能为用户找到他想要购买的商品或者阅读的内容。
目的4. 加深对用户的了解,为用户提供定制化服务
可以想见,每当系统成功推荐了一个用户感兴趣的内容后,我们对该用户的兴趣爱好等维度上的形象是越来越清晰的。当我们能够精确描绘出每个用户的形象之后,就可以为他们定制一系列服务,让拥有各种需求的用户都能在我们的平台上得到满足。
推荐系统的定义
推荐系统有3个重要的模块:用户建模模块、推荐对象建模模块、推荐算法模块。通用的推荐系统模型流程如图。推荐系统把用户模型中兴趣需求信息和推荐对象模型中的特征信息匹配,同时使用相应的推荐算法进行计算筛选,找到用户可能感兴趣的推荐对象,然后推荐给用户。

推荐系统存在的意义
随着当今技术的飞速发展,数据量也与日俱增,人们越来越感觉在海量数据面前束手无策。正是为了解决信息过载(Information overload)的问题,人们提出了推荐系统(与搜索引擎对应,人们习惯叫推荐系统为推荐引擎)。当我们提到推荐引擎的时候,经常联想到的技术也便是搜索引擎。
搜索引擎更倾向于人们有明确的目的,可以将人们对于信息的寻求转换为精确的关键字,然后交给搜索引擎最后返回给用户一系列列表,用户可以对这些返回结果进行反馈,并且是对于用户有主动意识的,但它会有马太效应的问题,即会造成越流行的东西随着搜索过程的迭代会越流行,使得那些越不流行的东西石沉大海。
而推荐引擎更倾向于人们没有明确的目的,或者说他们的目的是模糊的,通俗来讲,用户连自己都不知道他想要什么,这时候正是推荐引擎的用户之地,推荐系统通过用户的历史行为或者用户的兴趣偏好或者用户的人口统计学特征来送给推荐算法,然后推荐系统运用推荐算法来产生用户可能感兴趣的项目列表,同时用户对于搜索引擎是被动的。其中长尾理论(人们只关注曝光率高的项目,而忽略曝光率低的项目)可以很好的解释推荐系统的存在,试验表明位于长尾位置的曝光率低的项目产生的利润不低于只销售曝光率高的项目的利润。推荐系统正好可以给所有项目提供曝光的机会,以此来挖掘长尾项目的潜在利润。
如果说搜索引擎体现着马太效应的话,那么长尾理论则阐述了推荐系统所发挥的价值。
二、推荐系统的分类

三、主要的推荐算法
推荐算法大致可以分为以下几类
- 基于流行度的算法
- 协同过滤算法(user-based CF and item-based CF)
- 基于内容的算法(content-based)
- 基于模型的算法
- 混合算法
1. 基于流行度的算法
可以按照一个项目的流行度进行排序,将最流行的项目推荐给用户。比如在微博推荐中,将最为流行的大V用户推荐给普通用户。微博每日都有最热门话题榜等等。
这种算法的优点是简单,适用于刚注册的新用户。缺点也很明显,它无法针对用户提供个性化的推荐。
2. 基于内容的算法
基于内容的推荐(Content-based Recommendation)是 信息过滤技术的延续与发展,它是建立在项目的内容信息上作出推荐的,而不需要依据用户对项目的评价意见,更多地需要用机 器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。在基于内容的推荐系统中,项目或对象是通过相关的特征的属性来定义,系统基于用户评价对象 的特征,学习用户的兴趣,考察用户资料与待预测项目的相匹配程度。
基于内容的推荐算法(Content-Based Recommendations CB)是最早被使用的推荐算法,它的思想非常简单:根据用户过去喜欢的物品(本文统称为 item),为用户推荐和他过去喜欢的物品相似的物品。而关键就在于这里的物品相似性的度量,这才是算法运用过程中的核心。 CB最早主要是应用在信息检索系统当中,所以很多信息检索及信息过滤里的方法都能用于CB中。
3.协同过滤算法
顾名思义,它是通过集体智慧的力量来进行工作,过滤掉那些用户不感兴趣的项目。协同过滤是基于这样的假设:为特定用户找到他真正感兴趣的内容的好方法是首先找到与此用户有相似兴趣的其他用户,然后将他们感兴趣的内容推荐给此用户。
它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户进行推荐,通常需要用到UI矩阵的信息。协同过滤推荐又可以根据是否运用机器学习的思想进一步划分为基于内存的协同过滤推荐(Memory-based CF)和基于模型的协同过滤推荐(Model-based CF)。
4. 基于模型的算法
协同过滤算法在大数据情况下,由于计算量较大,不能做到实时的对用户进行推荐。基于模型的协同过滤算法有效的解决了这一问题,矩阵分解(Matrix Factorization, MF)是基于模型的协同过滤算法中的一种。在基于模型的协同过滤算法中,利用历史数据训练得到模型,并利用该模型实现实时推荐
5. 混合算法
现实应用中,其实很少有直接用某种算法来做推荐的系统。在一些大的网站如Netflix,就是融合了数十种算法的推荐系统。我们可以通过给不同算法的结果加权重来综合结果,或者是在不同的计算环节中运用不同的算法来混合,达到更贴合自己业务的目的。