标题:PARSING MAP GUIDED MULTI-SCALE ATTENTION NETWORK FOR FACE

中文:解析图指导的多尺度注意力网络人脸超分辨
摘要
- 旨在将低分辨率(LR)的人脸图像转换为高分辨率(HR)的人的幻觉是活动领域特定的图像超分辨率问题。现有方法的性能通常不能令人满意,尤其是在放大系数较大(例如8倍)时。在本文中,我们提出了一种基于深度神经网络的有效两步幻觉方法,该神经网络具有多尺度通道和空间注意机制。具体来说,我们开发了一个解析网络来提取输入LR面孔的先验知识,然后将其输入经过精心设计的FishSRNet中以恢复目标HR面孔。实验结果表明,在定量指标和视觉质量方面,我们的方法优于最新技术。
背景:现有方法的性能通常不能令人满意,尤其是在放大系数较大(例如8倍)时。
方法:提出了一种基于深度神经网络的有效两步幻觉方法,该神经网络具有多尺度通道和空间注意机制。开发了一个解析网络来提取输入LR面孔的先验知识,然后将其输入经过精心设计的FishSRNet中以恢复目标HR面孔。
结论:实验结果表明,在定量指标和视觉质量方面,我们的方法优于最新技术。
引言
面部检测和识别,情绪分析等与面部相关的任务中有广泛应用
- 从特定的低分辨率(LR)图像生成高分辨率(HR)面部图像的面部幻觉是一种典型的领域特定图像超分辨率技术。在许多实际场景中,由于低成本相机的限制,捕获的面部图像通常处于低分辨率状态。因此,幻觉在诸如面部检测和识别,情绪分析等与面部相关的任务中具有广泛的应用。
传统方法在放大因子很大时效果不佳
- 在文献中,Baker和Kanade [1]首次尝试通过从训练集中搜索局部特征来幻化来自父代结构的面部图像,这启发了许多创新方法。例如,刘等。 [2]首先用全局模型重建人脸图像,然后他们使用局部模型进行细化。 Wang等。 [3]利用特征变换来获得从LR到HR的映射。另外,引入了一些基于位置补丁的方法[4、5、6、7],这些方法具有不同的正则化,以逐块地重构目标HR人脸。 [8]通过将面部分为面部成分,轮廓和光滑区域,来利用局部图像结构进行面部幻觉。但是,当放大系数较大(例如8倍)时,所有这些方法似乎都难以生成出色的HR面部图像。
深度学习方法应用于人脸超分辨。忽略了人脸先验知识。
- 得益于其出色的表示能力,深度学习技术近年来已成功应用于图像超分辨率任务,并且比基于传统浅层学习的方法具有更好的性能。 Dong等人提出的SRCNN [9]。首次使用深度模型解决图像超分辨率问题。 VDSR [10]是另一种著名的算法,它引入了残差学习并加深了网络以获得更好的性能。从那时起,已经提出了许多方法通过设计更深或更复杂的网络结构,例如EDSR [11],RCAN [12]等。
由于这些方法都是针对自然图像而设计的,因此它们在面部图像上的性能较差,尤其是在放大系数较大时。然后针对面部幻觉量身定制一些深层模型。朱等。文献[13]使用两分支网络分别超分辨低频纹理细节和高级频率纹理细节。 Yu等。 [14]引入了生成对抗性网络(GAN)进行幻觉,[15]提出了可转换判别式自编码器,以幻化非常低分辨率的未对准且嘈杂的人脸图像。在[16]中,提出了一种用于面部幻觉的深CNN去噪器。尽管这些方法可显着提高面部幻觉的性能,但**它们忽略了与面部图像相关的一些重要先验信息,例如面部结构,面部界标等。**为此,FSRNet [17]和[18]都提出首先将超幻觉图像超级解析LR脸部图像以获得中间HR脸部图像或超分辨特征,然后从中检测出脸部界标,热图或解析图。通过结合中间结果和先验知识获得最终的重构人脸。
需要考虑的问题
- 尽管这些用于人脸图像的超分辨率方法取得了令人印象深刻的性能,但仍需要仔细考虑以下问题:
- i)中间结果的先验知识直接受到中间结果质量的影响,通常这是有限的,导致掌握不良甚至错误的先验知识。
- ii)在一般的图像超分辨率方法中[19,20],已证明通道和空间注意信息对于提高图像重建的性能很有用。然而,作为一种特定的图像超分辨率方法,大多数现有的幻觉方法都忽略了注意力机制。
- iii)当前的深脸图像超分辨率网络始终是前上采样或后上采样。但是,低分辨率的功能不适合像素级任务,高分辨率的浅层功能不能直接用于像素级任务[21]‘
我们提出的方法。通过LR图像直接提取先验信息。由于从中间结果提取先验信息会导致中间结果对其产生影响。
但是如果直接从LR图像提取先验信息,那么很小的LR图像无法提取有效的人脸先验信息。
- 考虑到上述缺点,本文提出了一种解析地图引导的多尺度注意力网络用于幻觉。如图 1所示,我们提出的网络包括两个子网。第一个是ParsingNet,它旨在学习人脸图像的先验知识。
为了减少错误对中间结果的影响,我们直接从输入LR面上提取先验知识,即解析图,而不是像[17,18]那样提取中间结果。第二个子网(称为FishSRNet)将解析图和LR面部图像都作为输入来生成HR面部图像。总体而言,我们的FishSRNet(鱼形网络)可以生成和利用各种分辨率的特征,从而充分利用了来自不同层的信息并促进了它们之间的协作。具体来说,为了利用空间和通道的相关性,我们构建了一个多尺度的通道和空间注意块(MSAB),以将通道和空间注意与ResBlock相结合[22]。结果表明,我们的方法实现了最新的面部幻觉性能。所提出的方法的主要贡献概括如下:- •我们提出了由ParsingNet和FishSRNet组成的两步深幻觉。
- •FishSRNet是源自FishNet的改进的鱼形网络,能够生成各种分辨率的特征并利用来自不同层的信息。
- •我们介绍了一种新颖的MSAB,它可以提取多尺度信息并利用特征的通道和空间相关性。

图1.我们方法的总体框架
图2. FishSRNet架构

方法
- 如图1所示,我们的方法由两个子网组成:i)从LR面孔学习解析图的ParsingNet,以及ii)利用LR面孔和相应的解析图恢复HR面孔的FishSRNet。接下来,我们将详细介绍它们。
2.1 ParsingNet
- 与自然图像不同,面部图像具有自己独特的结构先验知识,这更有可能促进面部幻觉。常用的先验知识包括面部热图,地标和解析图。在我们的方法中,我们选择一个人脸解析地图作为辅助信息,并设计一个名为ParsingNet的子网来从输入LRfaces中学习人脸解析地图。特别是,我们
将面部图像分为六个部分:眼睛,眉毛,鼻子,嘴巴,皮肤和其他。我们的解析图是一个蒙皮矩阵,其蒙皮区域为0,而覆盖其他五个组件的区域为255,这是基于以下事实:蒙皮是光滑的,而其他组件包含更丰富的纹理和结构信息。我们的ParsingNet是由顺序Resblocks组成的常见卷积神经网络[22]。 ,因此在此省略其详细信息。
2.2 FishSRNet
- 受FishNet [21]的启发,我们提出了一个称为FishSRNet的修改版本。如图2所示,FishSRNet是鱼形网络,由特征提取层,鱼头,身体,尾巴和重建层组成。为了从LR图像中恢复HR面部图像,我们的FishSRNet
首先对输入进行升采样,然后再次对图像进行降采样和升采样。在相邻的升采样模块(卷积和pixelshuffle [23],UM)之间或降采样模块之间( FishSRNet中的inv-pixelshuffle和convolution [24],DM),有两个级联的MSAB。详细地,我们将输入faceILR和解析mappas连接到FishSRNet的输入,然后使用特征提取层从输入中提取特征。【先升采样、再降采样、再升采样】
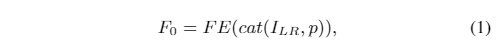
- 其中FE(·)是特征提取操作,cat(·)表示沿通道维数的级联操作,然后将F0用于深层。
- 然后鱼头对特征图进行3次向上采样,以提高接收区域和分辨率特征
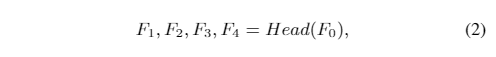
- 其中Head(·)表示我们的鱼头,F4是最后一层鱼头的特征。鱼头由三个顺序的UM-MSAB-MSAB组成。为了充分利用来自不同层的信息,我们保留了三个UM的特征并将其分别表示为F1,F2,F3,并引入了从鱼头到身体的直接连接,如图2所示。 -在鱼体内取样以提高分辨率的多样性。同时,鱼体利用鱼头保留的特征产生新特征。
2.3. Multi-scale attention block (MSAB)
- 近年来,在以往的一般图像超分辨率方法研究中,通道注意力和空间注意力已被证明非常有效地提取LR图像的特征并重建HR。考虑到人脸图像是一种特殊的自然图像,我们将注意机制引入人脸半透明任务中。另外,由于多尺度卷积可以提取多尺度信息,因此我们提出了如图3所示的MSAB,它包括三个主要模块:

图3:MSAB
-
卷积-ReLU:MSAB首先采用卷积-ReLU提取inputFin的特征以进行多尺度卷积。
-
多尺度卷积:我们的多尺度卷积由四个具有不同过滤器大小和不同参数的卷积组成,有助于提取多尺度信息。N表示特征通道的数量。为了避免引入过多的参数,每个卷积的入通道数和出通道数分别为n和n / 4。然后,将n通道的所有特征馈入四个卷积,并生成4个n / 4通道特征。接下来的步骤是将四个卷积中的特征连接起来。这样,我们可以获取多尺度特征,并保持特征的通道数量不变,而无需增加太多参数。
-
通道注意机制:为了捕获通道统计信息,平均池通常用于跨各个特征通道空间尺寸。 Max-pooling收集了关于独特对象特征的另一个重要线索,以推断出更精细的通道注意[25]。我们假设方差合并可以捕获更多丰富的纹理信息。因此,我们选择对合并方法同时使用平均值,最大值和方差。然后使用两个完全连接的层,然后再加上一个S型函数来制作通道注意遮罩。【平均池化、最大池化、方差池化】
-
空间注意机制:无需提取通道维度上各个空间区域的统计信息,我们直接使用两个1×1卷积和一个S型函数来捕获两个通道之间的相互关系空间区域,然后生成一个空间注意蒙版。
-
通道和空间注意蒙版分别用于通过通道和空间乘以重新缩放功能。然后,MSAB将两个重新缩放的特征沿通道维级联以生成Fcs。最后,MSAB结合Fin和Fcs,以产生MSAB的输出。【Fcs就是通过注意力机制注意得到的特征】

图4.我们不同组成部分的影响图示:(a)LR。 (b)模型2的结果。 (c)模型3的结果。 (d)模型4的结果。 (e)基本事实。
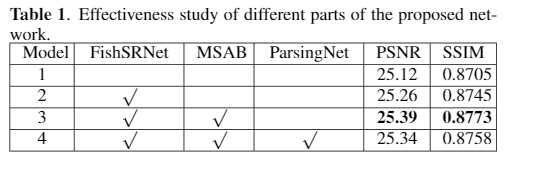
此处其实就是一个消融实验。通过加入不同的功能网络,探索各个网络的效果。实验证明,最终网络效果最好
实验
3.1. Datasets and Metrics
- 我们在两个数据集上训练我们的模型:CelebA [26]和CelebAMask-HQ [27],它们具有解析地图的真实性。对于CelebAMask-HQ,我们首先选择20000张脸,然后将它们的尺寸调整为16×16以进行训练。对于CelebA,我们选择头18000张面孔进行训练,另外选择260张面孔进行评估。我们**将人脸图像的尺寸调整为128×128作为HR人脸图像,将16×16作为LR人脸图像。**引入峰值信噪比(PSNR)和结构相似性(SSIM)[28]指标作为评估指标。
3.2 实验细节
- 我们首先用CelebAMask-HQ训练ParsingNet,目标函数表示为:
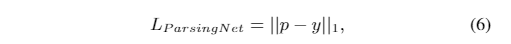
- 这是事实的基础,是ParsingNet的输出。然后用CelebA联合训练两个子网,损失函数为
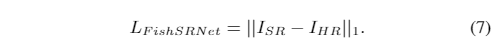
- 我们的模型由ADAM训练,其中β1= 0.9,β2= 0.99和= 1e-8。当分别训练ParsingNet时,学习率(lr)为1e−4。然后,我们联合训练FishSRNet(lr = 1e-4)和微调ParsingNet(lr = 1e-5)。
3.3 消融研究
- 这里我们通过实验分析了网络中不同组成部分的贡献,结果如表1所示。首先,去除鱼头和鱼体中的UM和DM,然后该网络成为常见的后采样网络(如model-1所示)。模型1性能最差,这意味着FishSRNet的设计更适合于幻觉。然后,我们使用带有Resblocks [22]的FishSRNet作为基线,称为模型2。配备了MSAB而不是Resblocks(表示为Model-3),网络可以具有更好的性能。然后,我们将ParsingNet添加到Model-3(表示为Model-4)中,在定量指标方面不超过其他任何产品。为了强调ParsingNet的有效性,我们在图4中展示了Model-2,Model-3,Model-4的可视结果。 Model-3和Model-4的面孔比Model-2的面孔清晰得多,并且Model-4的面孔比其他面孔最清晰,最真实。因此,我们的Pars-ingNet有助于视觉质量。为了在量化指标和视觉质量之间做出权衡,Model-4是最佳模型。


图6.我们方法的失败案例:(a)我们的方法和(b)人力资源。
3.4比较
-
这一段话,可以在论文中引用。
-
为了说明我们的方法在定量和视觉质量方面的优越性,我们将我们的方法与五种最先进的方法进行了比较,包括早期的幻觉方法,UR-DGN [14],传统方法和深度方法的结合。学习方法[16],利用人脸解析图和界标的FSRNet [17]以及两个代表性的通用超分辨率方法SRCNN [9]和VDSR [10]。我们还介绍了三次三次插值。为了公平比较,我们用数据集重新训练了除FSRNet之外的所有模型。对于FSRNet,我们使用其已发布的预训练模型,因为我们的训练数据集与其相同。
-
表2显示了比较方法和我们方法的定量比较结果。显然,我们的方法可以以更高的PSNR和SSIM生成结果。至于视觉质量,从图5可以看出,与其他方法相比,我们的方法可以产生更准确,更清晰的图像,尤其是在面部组件上。传统的基于深度学习的通用图像超分辨率方法**(即SRCNN和VDSR)的性能较差,因为它们没有考虑面部的先验知识。** URDGN主要关注视觉效果,因此量化指标没有竞争力。基于面部知识的模型已经取得了良好的性能,但是次优比较方法的PSNR和SSIM分别比我们提出的方法低0.26 dB和0.088。定量和定性比较都证明了我们提出的方法的优越性。
我们的方法在处理特殊面孔时也效果不好。
- 但是,我们的方法在遇到特殊面孔时表现不佳。图6中描述了一些故障情况,包括闭眼或极端姿势的情况。对于前者,我们的方法生成睁开的眼睛,而地面真相却闭着的眼睛。我们假设我们的方法能够生成面部成分,但无法区分睁眼和闭眼。至于后者,我们的结果远非事实。
结论
- 提出了一种解析地图引导的多尺度关注人脸幻觉方法,该方法利用人脸先验知识,将关注机制引入人脸幻觉中。另外,受FishNet [21]的启发,我们提出了一个高级版本FishSRNet,它继承了FishNet [21]的优势,并利用来自不同层的各种分辨率和信息中的特征来幻化脸部图像。与现有方法相比,我们的方法可以获得良好的性能。将来,我们计划利用更多的人脸图像信息(例如人脸属性和身份)来提高超分辨率性能。