题目:A COARSE-TO-FINE FACE HALLUCINATION METHOD BY EXPLOITING FACIAL PRIORKNOWLEDGE
中文:利用面部先验知识的从粗到细面部识别方法

总结:这篇文章借鉴了FSRNet,思路完全是一样的,不同点就是使用了多尺度放大因子(x4,x8,x16)
摘要
- 幻觉技术从低分辨率(LR)的图像生成高分辨率(HR)的面部图像。在本文中,
我们建议通过构造一个两分支网络,使用从粗糙到精细的方法进行面部幻觉,这充分利用了面部图像的特定先验知识以及常规图像超分辨率(SR)方法的优点。具体来说,我们共同构建了具有人脸图像SR分支和语义人脸分析分支的深度神经网络(DNN)。前一个分支使用级联的卷积层实现图像上采样和特征提取。后一个分支提取面部语义分析作为先验知识。然后,我们结合图像特征和先验知识来重建HR人脸图像。最后,我们通过对抗训练和感知损失来优化DNN,以获得较高的真实感。大量实验表明,该方法在准确性和真实性方面均优于最新的方法。
背景:使用先验知识进行人脸超分辨
方法:共同构建了具有人脸图像SR分支和语义人脸分析分支的深度神经网络(DNN),前一个分支使用级联的卷积层实现图像上采样和特征提取。后一个分支提取面部语义分析作为先验知识。然后,我们结合图像特征和先验知识来重建HR人脸图像。
结论:该方法在准确性和真实性方面均优于最新的方法。
引言
- 面部幻觉是从低分辨率(LR)推断高分辨率(HR)面部图像的特定领域超分辨率(S-R)问题。它被广泛用于各种现实生活中,例如视频监视[1]和人脸识别[2,3]。
传统方法和缺点
- Baker和Kanada [4]首先从事关于面部幻觉的研究。从此以后,提出了许多面部幻觉方法[5-12]。 Wang等。 [6]通过应用本征变换,在LR和HR脸部之间进行了映射。刘等。 [7]引入了两步法,包括全局图像重建和残差补偿。但是,
这些全局方法[6,7]无法有效地重建局部细节。为此,提出了通过采用位置先验的基于补丁的局部方法。等。 [10]通过线性组合训练图像的斑块在相同位置重建HR面部图像斑块。Wang等。 [13]实现自适应稀疏正则化位置表示权重
。杨等。 [12]通过根据面部标志和姿势估计结果将面部图像划分为不同的组,来进行幻觉之前的面部结构。然而,当人脸未精确对准时,这些方法的重建结果[10,12,13]通常是不准确的。
基于深度学习的方法,和缺点
- 近来,基于深度学习的方法[14-17]在通用图像SR问题中得到了非常有效的体现。董等。 [14]首先提出了使用三个卷积层的超分辨率卷积神经网络(SRCNN),以学习LR和HR图像之间的端到端映射。 Ledig等。 [15]采用残差学习[18]来构建深度神经网络(SRResNet)并实现出色的性能。至于面部幻觉[5、8、9、11],Zhou等。 [5]在没有任何先验知识的情况下,使用BCCNN预测HR图像。朱等。 [8]结合估计的密集人脸对应字段和深层级联双网络(CBN)逐步对人脸图像进行采样。不幸的是,[8]
过于复杂,有效的建模训练需要大量的人工预处理。
GAN网络,的缺点
- 生成对抗网络(GAN)[19]提供了一个强大的框架,用于生成可感知的图像。 Yu等。 [20]构建GAN来超分辨LR人脸图像(URDGN)。在[21]中,提出了一种变换判别式自动编码器(TDAE),以使微小的未对准且嘈杂的人脸图像产生幻觉。尽管这些基于GAN的方法[20,21]在某些情况下可以生成更逼真的人脸图像,但它们却遭受
网络训练和图像生成结果的不稳定性的困扰。另外,这些方法中没有考虑先验知识。
提出我们的解决方案
- 为了克服上述方法的缺点,本文提出了一种高保真度的从粗糙到精细的幻觉方法。具体来说,通过结合通用图像SR方法和有益的面部先验知识(语义面部分析)来设计两分支网络。本文的主要贡献如下。
- 1)与传统的双通道网络体系结构[5,8]不同,我们的网络继承了通用图像SR方法[15,17]的优点,同时受益于人脸解析结果。面部的整体结构和轮廓以及面部区域的形状和位置被认为是有用的先验知识。因此,所提出的网络具有更高的幻觉质量和更多信息。【结合通用图像超分辨和人脸先验知识的优点】
- 2)与现有方法[8、14、20]相比,我们的方法可以将小脸图像(16×16像素大小或s-maller)超分辨率放大为更大的版本,并具有多个放大倍率(4×,8×或3)我们进一步引入对抗训练以生成更逼真的面部图像。大量的实验表明,我们的方法在准确性和真实性方面都优于最新的替代方法。

图1:所建议方法的概述。
2、proposed method
将语义解析图作为先验信息。
- 疑问:如何使用先验信息?
- 受到基于深度学习的SR方法[14-17]成功的启发,提出了一种从粗到细的幻觉方法,将语义人脸解析作为先验知识。如图1所示,该方法包括四个模块:图像上采样,特征提取,面部语义分析和图像重建。然后设计一个包含这些模块的两分支网络(请参见图2),以充分利用DNN和先验知识。
2.1网络结构
- 我们提出了一种基于双分支网络的从粗到精的方法。从概念上讲,两分支网络类似于[5],其中构建了双通道CNN。但是,我们的网络在两个方面与[5]根本不同。首先,文献BCCNN[5]中的双通道网络使用三个卷积层来提取第一通道中的特征,而原始LR图像作为网络体系结构中的第二通道,而我们的两分支网络可以使用级联的残差块来提取高级特征。 [18]在第一分支中使用卷积层和反卷积层[22]来利用语义信息。第二,在[5]中没有考虑先验知识,而我们所提出的方法受益于残差学习和面部语义解析提供更多的监督信息。
2.1.1. Face image SR branch
https://blog.csdn.net/qq_27009517/article/details/84028568
上面链接中的文章主要讲了残差,shortcut connection、inception等等。可以帮助理解
虽然说DNN的方法是双分支结构,但是仔细看来其实和FSRNet的机结构基本是一样的。也是使用了三个子网络。
- 事实证明,更深层的网络可以提取更多有利于图像处理的高级功能[3,18],而shortcut connection已显示出特殊优势。因此,基于具有残差学习和跳过连接的DNN设计了人脸图像SR分支,以实现更具描述性的人脸表示。如图2(a)所示,该分支由三个子网络组成,即图像上采样,特征提取和图像重建。具体来说,当给出LR人脸图像时,第一个子网最初会提取脸部特征并以有效的子像素卷积[24]生成粗糙的脸部图像。随后,通过第二子网中的全局和局部残差学习[17]提取更高级别的面部特征。最后,通过将获得的面部特征与下一个分支提取的先验知识进行串联,可以在最后一个子网络中重建精细的面部图像。因此,这三个子网以粗糙到精细的方式实现了幻觉,并且针对HR图像一步一步地学习了输入的LR图像。

图2:固定的两分支网络。 (a):面部图像SR分支。 (b):语义人脸解析分支
2.1.2. Semantic face parsing branch
其实仔细一看,发现和FSRnet没什么两样,就是图画的不一样而已。也是先恢复一个粗糙的SR图像,再提取先验信息。
- 语义人脸分析分支从由图像上采样子网产生的粗糙人脸图像中提取先验知识。具体来说,我们将人脸解析地图作为通过编码器-解码器方法提取的先验知识,这是受到[22]中的反卷积网络的启发。尽管如此,已经设计了不同的方案以简化网络结构并减少输出类别的数量。如图2(b)所示,我们的网络由级联的卷积层和反卷积层组成,并被一些最大池化层和向上采样层分开。输出的脸部解析图覆盖脸部皮肤,头发,眼睛,眉毛,鼻子,嘴巴和背景。解析图被发送到图像重建子网,以促进对精细面部图像的推断。
2.2. Facial prior knowledge
- 我们之前已经介绍了运用面部先验知识来提高幻觉质量的合理性。在这项工作中,语义人脸分析分支利用了作为先验知识的人脸分析图。

图3:语义面孔解析分支的实例。从左至右:地面真相,语义面孔,背景,头发,面部皮肤,眉毛,眼睛,鼻子和嘴巴。
这图中的语义模块是自己训练网络划分得到的
- 是否能够找到代码自己提取语义信息。
- 从概念上讲,语义面部分析是将类别标签分配给面部图像中的每个像素的问题。需要成功的语义人脸解析模型来提供定位提示,以
将人脸图像的空间域分解为互斥的语义区域,例如人脸皮肤,头发和任何其他人脸成分。这些不同的语义区域(即,解析地图)包含大量信息,包括面部的整体结构和轮廓以及面部区域的形状和位置。具体来说,我们使用Helen人脸数据集[25]来训练语义人脸解析分支。每个图像都标有11段注解[26]:背景,头发,面部皮肤,左眉,右眼眉,左眼,右眼,鼻子,上唇,下唇和内口。此外,左眼和右眼(眉毛)标签组合在一起以创建单眼(眉毛)标签。类似地,将上唇,下唇和内嘴合在一起以生成单嘴标签。结果,总共获得了7个标签(背景,头发,面部皮肤,眉毛,眼睛,鼻子和嘴巴)。最后,选择softmax交叉熵损失来训练整个数据集上的该分支。图3说明了语义人脸分析分支结果的一些实例。
2.3. Training
- 人脸超分辨就是学习SR和LR之间的映射函数,MSE定义公式(1)

- 正如许多论文[15,27]所论证的那样,仅将MSE损失减到最小并不能产生令人满意的感知结果。因此,我们基于预先训练的VGG-Face模型[3]将VGG损失作为一种感知损失引入。表示为:
引入新的损失函数VGG_loss
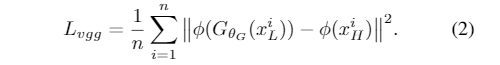
- 另外,我们进一步使用GAN [19]引入对抗性损失,以改善视觉质量。我们将判别器网络DθD和先前的网络定义为生成器网络GθG。因此训练GAN就是要解决对抗最小-最大问题:
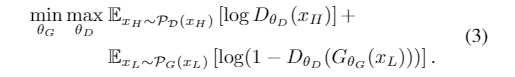
- 然后,将对抗损失函数定义为
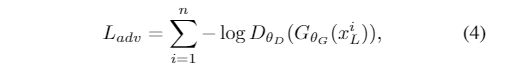
- 其中DθD(GθG(xiL))表示生成的图像GθG(xiL)是真实人脸HR图像的概率。最后,统一损失函数为:
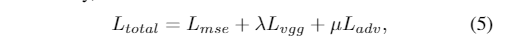
实验
- 我们证明了我们提出的方法在2个数据集上的优越性:CelebA [28]和Helen [25]。用于实验的工作站具有Intel i7-7700K 4.2G,32G内存和NVIDIA GTX1080 Ti。
3.1. Implementation details
- CelebA包含202,599张脸部图像,而Helen具有2,330张图像。遵循标准评估协议,使用CelebA图像中的19,200张图像进行训练,使用CelebA中的500张图像中的500图像来自Helen的图像进行评估。对齐的[29]图像的中心部分被裁剪并调整为HR脸部图像大小为128×128。然后将HR图像分别下采样为8×8、16×16和32×32,作为对应的LR图像。最后,我们在三种不同情况下应用我们的方法:(8×8,16×),(16×16,8×)和(32×32,4×),其中(m×m,n×)表示m×m输入分辨率放大倍数。
3.2 实验结果
- 为了证明引入先验知识进行人脸幻觉的有效性和实用性,分别对有和没有的人脸解析分支进行了训练。【消融研究】而且,可以扩展两分支网络以包含对抗训练。如图4所示,比较了不同设置的视觉结果,包括没有先验信息的单分支网络,具有先验和先验的两分支网络。具有对抗损失的两分支网络。此外,在表1的测试集上使用平均PSNR(dB)和SSIM对这些设置进行了定量评估和比较。
对比
- 我们在CelebA [28]和Helen [25]数据集上与最先进的通用和基于面部特定进行比较。

图5:与最新技术在倍率上的比较。 (a):8×8输入尺寸和16×放大倍率。 (b):16×16输入尺寸,放大倍数8倍。 (c):32x32输入大小,4倍放大率

图4:各种输入分辨率的结果。 (a):8×8输入尺寸和16×放大倍率。 (b):16倍×16倍输入尺寸,放大倍数8倍。 (c):32倍×32倍输入尺寸,放大倍数4倍。
比较实验效果

- 对于一般的SR方法,选择SRCNN [14]和SRResNet [15]是最有代表性的SR方法。在实践中,我们在CelebA数据集上对它们进行了重新训练,以使其更适合人脸图像。至于面部特有的SR方法,将CBN [8],URDGN [20]和TDAE [21]与我们的方法进行比较。 CBN在密集的对应域估计的帮助下将面孔幻化为空间先验。 URDGN预测HR人脸图像会遭受对抗损失。 TDAE通过自动编码器网络超级解析低分辨率的面部图像。使用与我们相同的训练数据来训练所有特定于面部的SR方法。如图5所示,我们的方法生成具有更高对比度和形状纹理的HR图像。专业训练提供了更具真实感的结果,并且在视觉上更接近地面真实性。定量结果报告在表2中。它表明我们的方法在多倍放大下的性能优于其他方法。

图中加粗的几个试验结果可以看出,加入GAN网络之后,PSNR和SSIM明显变小。但是效果比没有GAN要好。
结论
- 本文提出了一种以粗糙到精细的方式进行人脸幻觉的两分支网络,该网络
结合了作为先验知识的语义人脸解析和通用图像超分辨率方法的优点。实验结果表明,我们的方法可以有效地超大分辨率放大超低分辨率人脸图像。与最新方法的比较证明了所提方法在准确性和真实性方面的优越性。对于未来的工作,我们计划利用更多的先验知识,例如地标热图,以提高性能。 - 借鉴这一篇论文。
- 跳跃连接(残差函数):
https://www.pianshen.com/article/2567156882/