一、简介
1、Beats是elastic公司的一款轻量级数据采集产品,它包含了几个子产品:
1)packetbeat(用于监控网络流量)
2)filebeat(用于监听日志数据,可以替代logstash-input-file)
3)topbeat(用于搜集进程的信息、负载、内存、磁盘等数据)
4)winlogbeat(用于搜集windows事件日志)
注:社区还提供了dockerbeat等工具(非elastic公司)
2、Filebeat是一个开源的文件收集器,采用go语言开发,重构logstash采集源码,安装在服务器上作为代理来监视日志目录或特定的日志文件,并把它们发送到logstash或elasticsearch等。
3、Filebeat是代替logstash-forwarder的数据采集方案,原因是logstash运行在jvm上,对服务器的资源消耗比较大
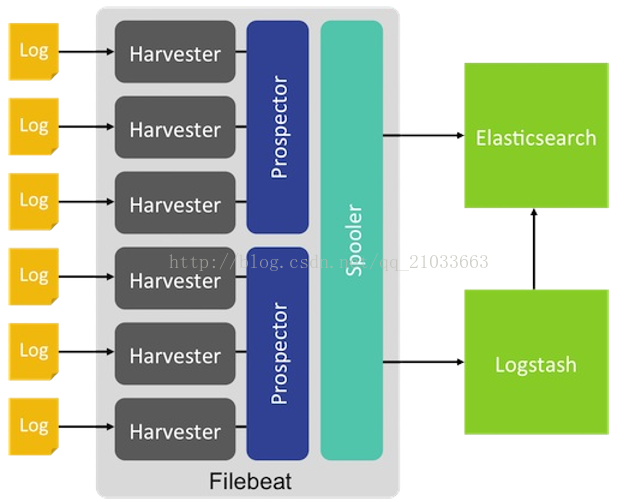
当开启filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测指定的日志目录或文件,对于探测器找出的每一个日志文件,filebeat启动收割进程(harvester),每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的地点。
三、输出方式
1)Elasticsearch(推荐)
2)Logstash(推荐,注:logstash用于过滤)
3)File
4)Console
5)Kafka(网上普遍吐槽)
6)Redis
官方文档:
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-configuration-details.html#configuration-output
四、使用
1、下载、安装
1)源码
wget https://download.elastic.co/beats/filebeat/filebeat-1.3.0-x86_64.tar.gz
tar -zxvf filebeat-1.3.0-x86_64.tar.gz
2)deb
curl -L -Ohttps://download.elastic.co/beats/filebeat/filebeat_1.3.0_amd64.deb
sudo dpkg -i filebeat_1.3.0_amd64.deb
3)rpm
curl -L -Ohttps://download.elastic.co/beats/filebeat/filebeat-1.3.0-x86_64.rpm
sudo rpm -vi filebeat-1.3.0-x86_64.rpm
4)MAC
curl -L -Ohttps://download.elastic.co/beats/filebeat/filebeat-1.3.0-darwin.tgz
tar -xzvf filebeat-1.3.0-darwin.tgz2、安装
5)win
a、下载windows zip文件 点击下载.
b、解压文件到 C:\ProgramFiles.
c、重命名为 Filebeat.
d、打开PowerShell提示符作为管理员(右键单击PowerShell的图标,并选择以管理员身份运行)。如果您运行的是Windows XP,则可能需要下载并安装PowerShell
e、运行以下命令来安装Filebeat作为Windows服务
cd ‘C:\ProgramFiles\Filebeat’
C:\ProgramFiles\Filebeat> .\install-service-filebeat.ps1
2、修改配置文件
Filebeat的配置文件是/etc/filebeat/filebeat.yml,遵循YAML语法。具体可以配置如下几个项目:
Filebeat
Output
Shipper
Logging(可选)
Run Options(可选)
Filebeat主要定义prospector的列表,定义监控哪里的日志文件,关于如何定义的详细信息可以参考filebeat.yml中的注释,下面主要介绍一些需要注意的地方。
paths:指定要监控的日志,目前按照Go语言的glob函数处理。没有对配置目录做递归处理,比如配置的如果是:
/var/log/*/*.log
则只会去/var/log目录的所有子目录中寻找以”.log”结尾的文件,而不会寻找/var/log目录下以”.log”结尾的文件。
encoding:指定被监控的文件的编码类型,使用plain和utf-8都是可以处理中文日志的。
input_type:指定文件的输入类型log(默认)或者stdin。
exclude_lines:在输入中排除符合正则表达式列表的那些行。
include_lines:包含输入中符合正则表达式列表的那些行(默认包含所有行),include_lines执行完毕之后会执行exclude_lines。
exclude_files:忽略掉符合正则表达式列表的文件(默认为每一个符合paths定义的文件都创建一个harvester)。
fields:向输出的每一条日志添加额外的信息,比如“level:debug”,方便后续对日志进行分组统计。默认情况下,会在输出信息的fields子目录下以指定的新增fields建立子目录,例如fields.level。
fields:
level: debug
fields_under_root:如果该选项设置为true,则新增fields成为顶级目录,而不是将其放在fields目录下。自定义的field会覆盖filebeat默认的field。例如添加如下配置:
fields:
level: debug
fields_under_root: true
ignore_older:可以指定Filebeat忽略指定时间段以外修改的日志内容,比如2h(两个小时)或者5m(5分钟)。
close_older:如果一个文件在某个时间段内没有发生过更新,则关闭监控的文件handle。默认1h,change只会在下一次scan才会被发现
force_close_files:Filebeat会在没有到达close_older之前一直保持文件的handle,如果在这个时间窗内删除文件会有问题,所以可以把force_close_files设置为true,只要filebeat检测到文件名字发生变化,就会关掉这个handle。
scan_frequency:Filebeat以多快的频率去prospector指定的目录下面检测文件更新(比如是否有新增文件),如果设置为0s,则Filebeat会尽可能快地感知更新(占用的CPU会变高)。默认是10s。
document_type:设定Elasticsearch输出时的document的type字段,也可以用来给日志进行分类。
harvester_buffer_size:每个harvester监控文件时,使用的buffer的大小。
max_bytes:日志文件中增加一行算一个日志事件,max_bytes限制在一次日志事件中最多上传的字节数,多出的字节会被丢弃。
multiline:适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈。这个配置的下面包含如下配置:
<code class="hljs applescript has-numbering" style="display: block; padding: 0px; color: inherit; box-sizing: border-box; font-family: "Source Code Pro", monospace;font-size:undefined; white-space: pre; border-radius: 0px; word-wrap: normal; background: transparent;">pattern:多行日志开始的那一行匹配的pattern negate:是否需要对pattern条件转置使用,不翻转设为<span class="hljs-constant" style="box-sizing: border-box;">true</span>,反转设置为<span class="hljs-constant" style="box-sizing: border-box;">false</span> match:匹配pattern后,与前面(<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">before</span>)还是后面(<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">after</span>)的内容合并为一条日志 max_lines:合并的最多行数(包含匹配pattern的那一行) <span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">timeout</span>:到了<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">timeout</span>之后,即使没有匹配一个新的pattern(发生一个新的事件),也把已经匹配的日志事件发送出去</code><ul class="pre-numbering" style="box-sizing: border-box; position: absolute; width: 50px; top: 0px; left: 0px; margin: 0px; padding: 6px 0px 40px; border-right-width: 1px; border-right-style: solid; border-right-color: rgb(221, 221, 221); list-style: none; text-align: right; background-color: rgb(238, 238, 238);"><li style="box-sizing: border-box; padding: 0px 5px;">1</li><li style="box-sizing: border-box; padding: 0px 5px;">2</li><li style="box-sizing: border-box; padding: 0px 5px;">3</li><li style="box-sizing: border-box; padding: 0px 5px;">4</li><li style="box-sizing: border-box; padding: 0px 5px;">5</li></ul>tail_files:如果设置为true,Filebeat从文件尾开始监控文件新增内容,把新增的每一行文件作为一个事件依次发送,而不是从文件开始处重新发送所有内容。
backoff:Filebeat检测到某个文件到了EOF之后,每次等待多久再去检测文件是否有更新,默认为1s。
max_backoff:Filebeat检测到某个文件到了EOF之后,等待检测文件更新的最大时间,默认是10秒。
backoff_factor:定义到达max_backoff的速度,默认因子是2,到达max_backoff后,变成每次等待max_backoff那么长的时间才backoff一次,直到文件有更新才会重置为backoff。比如:
如果设置成1,意味着去使能了退避算法,每隔backoff那么长的时间退避一次。
spool_size:spooler的大小,spooler中的事件数量超过这个阈值的时候会清空发送出去(不论是否到达超时时间)。
idle_timeout:spooler的超时时间,如果到了超时时间,spooler也会清空发送出去(不论是否到达容量的阈值)。
registry_file:记录filebeat处理日志文件的位置的文件
config_dir:如果要在本配置文件中引入其他位置的配置文件,可以写在这里(需要写完整路径),但是只处理prospector的部分。
publish_async:是否采用异步发送模式(实验功能)。
3、启动
sudo /etc/init.d/filebeat start
4、停止
1)ps -ef |grepfilebeat
2)kill掉该进程
五、其他数据采集
1)logstash-forwarder(elastic)
2)scribe(FaceBook)
3)chukwa(Apache)
4)flume(Cloudera)
5)fluentd
六、推荐解决方案
1、Filebeat(采集数据)+Elasticsearch(建立索引)+Kibana(展示)
2、Filebeat(采集数据)+Logstash(过滤)+Elasticsearch(建立索引)+Kibana(展示)
3、Filebeat(采集数据)+Kafka/Redis/File/Console(数据传输)+应用程序(处理,存储,展示)
4、Filebeat(采集数据)+Logstash(过滤)+Kafka/Redis/File/Console(数据传输)+应用程序(处理,存储,展示)
注:Redis/File/Console如何判断增量是一个问题
原链接:https://blog.csdn.net/qq_21033663/article/details/70807241?locationNum=7&fps=1