刘伟 360云计算
女主宣言
最近因为云原生日志收集的需要,我们打算使用Filebeat作为容器日志收集工具,并对其进行二次开发,因此笔者将谈谈 Filebeat 收集日志的那些事儿。本文不涉及过具体的源码分析,希望通过阅读您可以了解filebeat的基本使用方法和原理,姑且算是filebeat的入门吧。
PS:丰富的一线技术、多元化的表现形式,尽在“360云计算”,点关注哦!
1
前言
开源日志收集组件众多,之所以选择Filebeat,主要基于以下几点:
功能上能满足我们的需求:收集磁盘日志文件,发送到Kafka集群;支持多行收集和自定义字段等;
性能上相比运行于jvm上的logstash和flume优势明显;
Filebeat基于golang 技术栈,二次开发对于我们来说有一定的技术积累;
部署方便,没有第三方依赖;
2
Filebeat 能做什么
简单来说Filebeat就是数据的搬运工,只不过除了搬运还可以对数据作一些深加工,为业务增加一些附加值。
Filebeat可以从多种不同的上游input 中接受需要收集的数据,其中我们最常用的就是 log input,即从日志中收集数据;
Filebeat对收集来的数据进行加工,比如:多行合并,增加业务自定义字段,json等格式的encode;
Filebeat将加工好的数据发送到被称为output的下游,其中我们最常用的就是 Elasticsearch 和 Kafka;
Filebeat具有ACK反馈确认机制,即成功发送到output后,会将当前进度反馈给input, 这样在进程重启后可以断点续传;
Filebeat在发送output失败后,会启动retry机制,和上一次ACK反馈确认机制一起,保证了每次消息至少发送一次的语义;
Filebeat在发送output时,由于网络等原因发生阻塞,则在input上游端会减慢收集,自适应匹配下游output的状态。
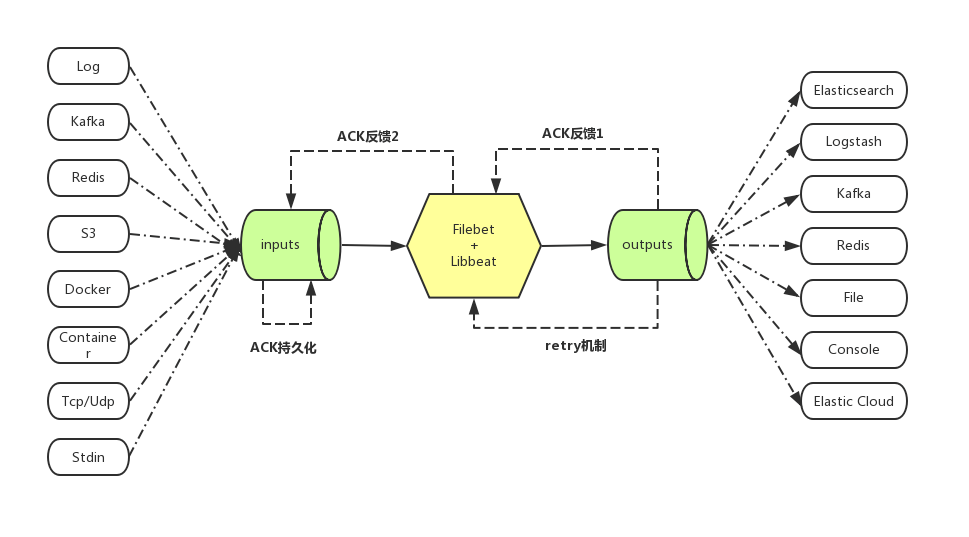
一图以蔽之。
3
Filebeat 背后的“老大”
说到Filebeat,它其实只是 beats 家族众多成员中的一个。除了Filebeat, 还有很多其他的beat小伙伴:
| beat |
功能 |
| Filebeat | 收集日志文件 |
| Metricbeat | 收集各种指标数据 |
| Packetbeat | 收集网络数据包 |
| Auditbeat | 收集审计数据 |
| Heartbeat | 收集服务运行状态监测数据 |
| ... |
... |
如果你愿意的话,你也可以按照beat的规范来写自己的beat。
能实现以上这些beat,都离不开beats家族真正的“老大”—— libbeat, 它是beat体系的核心库。我们接下来看一下libbeat到底都做了些什么:
libbeat提供了publisher组件,用于对接input;
收集到的数据在进入到libbeat后,首先会经过各种 processor的加工处理,比如过滤添加字段,多行合并等等;
input组件通过publisher组件将收集到的数据推送到publisher内部的队列;
libbeat本身实现了前面介绍过的多种output, 因此它负责将处理好的数据通过output组件发送出去;
libbeat本身封装了retry的逻辑;
libbeat负责将ACK反馈通过到input组件 ;
由此可见,大部分活儿都是libbeat来做,当“老大”不容易啊~。
input仅需要做两件事:
从不同的介质中收集数据后投递给libbeat;
接收libbeat反馈回来的ACK, 作相应的持久化;
4
Filebeat 的简单使用示例
Filebeat本身的使用很简单,我们只需要按需写好相应的input和output配置就好了。下面我们以一个收集磁盘日志文件到Kafka集群的例子来讲一下。
1. 配置inputs.d目录
在filebeat.yml添加如下配置,这样我们可以将每一种等收集的路径写在单独的配置文件里,然后将这些配置文件统一放到inputs.d目录,方便管理
filebeat.config.inputs:enabled: truepath: inputs.d/*.yml
2. 在inputs.d目录下创建test1.yml,内容如下
- type: log # Change to true to enable t enabled: true # Paths that should be crawl paths: - /home/lw/test/filebeat/*.log fields: log_topic: lw_filebeat_t_2
这个配置说明会收集所有匹配/home/lw/test/filebeat/*.log的文件内容,并且我们添加了一个自定义的filed: log_topic: lw_filebeat_t_2, 这个我们后面会讲到。
3. 在filebeat.yml中配置kafka output:
output.kafka: hosts: ["xxx.xxx.xxx.xxx:9092", "xxx.xxx.xxx.xxx:9092", "xxx.xxx.xxx.xxx:9092"] version: 0.9.0.1 topic: '%{[fields.log_topic]}' partition.round_robin: reachable_only: true compression: none required_acks: 1 max_message_bytes: 1000000 codec.format: string: '%{[host.name]}-%{[message]}'
其中:
hosts是kafka集群的broker list;
topic: '%{[fields.log_topic]}' : 这项指定了我们要写入kafka集群哪个topic, 可以看到它实现上是引用了上面test.yml配置中我们自定义的filed字段,通过这种方式我们就可以将收集的不同路径的数据写入到不同的topic中,但是这个有个限制就是只能写到一个kafka集群,因为当前版本的filebeat不允许同时配置多个output。
codec.format: 指定了写入kafka集群的消息格式,我们在从日志文件中读取的每行内容前面加上了当前机器的hostname。
启动就很简单了,filebeat和filebeat.yml, inputs.d都在同一目录下,然后 ./filebeat run就好了。
filebeat本身有很多全局的配置,每种input和output又有很多各自的配置,关乎日志收集的内存使用,是不是会丢失日志等方方面面,大家在使用时还需要仔细阅读,这里不赘述。
5
Log input 是如何从日志文件中收集日志的
input的创建:
根据配置文件内容创建相应的Processors, 用于前面提到的对从文件中读取到的内容的加工处理;
创建Acker, 用于持久化libbeat反馈回来的收集发送进度;
使用libbeat提供的
Pipeline.queue.Producer创建producer,用于将处理好的文件内容投递到libbeat的内部队列;
收集文件内容:
input会根据配置文件中的收集路径(正则匹配)来轮询是否有新文件产生,文件是否已经过期,文件是否被删除或移动;
针对每一个文件创建一个Harvester来逐行读取文件内容;
将文件内容封装后通过producer发送到libbeat的内部队列;

处理文件重命名,删除,截断:
获取文件信息时会获取文件的device id + indoe作为文件的唯一标识;
前面我们提过文件收集进度会被持久化,这样当创建Harvester时,首先会对文件作openFile, 以 device id + inode为key在持久化文件中查看当前文件是否被收集过,收集到了什么位置,然后断点续传;
在读取过程中,如果文件被截断,认为文件已经被同名覆盖,将从头开始读取文件;
如果文件被删除,因为原文件已被打开,不影响继续收集,但如果设置了CloseRemoved, 则不会再继续收集;
如果文件被重命名,因为原文件已被打开,不影响继续收集,但如果设置了CloseRenamed , 则不会再继续收集;
6
日志如何被发送
发送流程简述:
input将日志内容写入libbeat的内部队列后,剩下的事件就都交由libbeat来做了;
libbeat会创建consumer, 复现作libbeat的队列里消费日志event, 封装成Batch对象;
针对每个Batch对象,还会创建ack Channel, 用来将ACK反馈信息写入这个channel;
Batch对象会被源源不断地写入一个叫workQueue的channel中;
以kafka output为例,在创kafka output时首先会创建一个outputs.Group,它内部封装了一组kafka client, 同时启动一组goroutine;
上面创建的每个goroutine都从workQueue队列里读取Batch对象,然后通过kafka client发送出去,这里相当于多线程并发读队列后发送;
若kafka client发送成功,写入信息到ack channel, 最终会通过到input中;
若kafka client发送失败,启动重试机制;

重试机制:
以kafka output为例,如果msg发送失败,通过读取 ch <-chan *sarama.ProducerError可以获取到所有发送失败的msg;
针对ErrInvalidMessage, ErrMessageSizeTooLarge 和 ErrInvalidMessageSize这三种错误,无需重发;
被发送的 event都会封装成 Batch, 这里重发的时候也是调用Batch.RetryEevnts;
最后会调用到retryer.retry将需要重新的events再次写入到上图中黄色所示的 workQueue中,重新进入发送流程;
关于重发次数,可以设置max retries, 但从代码中看这个max retries不起作用,目前会一直重试,只不过在重发次数减少到为0时,会挑选出设置了Guaranteed属性的event来发送;
如果重发的events数量过多,会暂时阻塞住从正常发送流程向workQueue中写入数据,优先发送需要重发的数据;
7
后记