前言:
在文本分类中,垃圾邮件分类是个二分类任务,比较容易说明文本分类的原理,所以以下以垃圾邮件分类为例,讲述使用朴素贝叶斯算法做评论分类的使用方法及过程,后面有本篇代码链接。
–-----------------------------------------------------------------------------—----------------------------------------
–-----------------------------------------------------------------------------—----------------------------------------
这里是【机器学习】9:朴素贝叶斯算法原理,对贝叶斯原理不清楚的伙伴,可以自主学习。
–-----------------------------------------------------------------------------—----------------------------------------
本篇博客所用到的代码以及《谭松波酒店评论语料》都在这里可以下载
–-----------------------------------------------------------------------------—----------------------------------------
–-----------------------------------------------------------------------------—----------------------------------------
一、朴素贝叶斯如何应用于垃圾邮件分类
1.1、数据准备阶段:
- 在邮件识别中,我们已知有一个训练样本空间集 C = ( X 1 , X 2 , . . . , X n ) C=(X_1,X_2,...,X_n) C=(X1,X2,...,Xn),每条样本数据具有多条属性 X i = ( x i 1 , x i 2 , . . . , x i m ) X_i=(x_{i1},x_{i2},...,x_{im}) Xi=(xi1,xi2,...,xim);
- 样本空间所有类别标签: Y = ( y 1 , y 2 , . . . , y m ) Y=(y_1,y_2,...,y_m) Y=(y1,y2,...,ym);样本空间每一条样本 X X X都有一个类别标签 y y y对应;
- 用结巴分词将每条样本 X X X切成分词的形式: X = ( x 1 , x 2 , . . . , x k ) X=(x_1,x_2,...,x_k) X=(x1,x2,...,xk)
比如我们已知的两条样本如下:<样本,标签>的形式:
- X 1 X_1 X1:需要|为|企业|开具|发票,请|联系|我。 ——垃圾邮件
- X 2 X_2 X2:附件|是|我|做的|报表,如果|可行|,请|批示。 ——非垃圾邮件
–-----------------------------------------------------------------------------—----------------------------------------
1.2、数据处理阶段:词袋模型
词袋模型就是将样本空间所有的样本先切词、再去重后得到的词语大集合,配合one-hot编码格式产生如下的词语模型:

- 青色: X 1 , X 2 , . . . X_1,X_2,... X1,X2,...每一条都是一个样本数据;
- 蓝色:就是我们将样本集 C C C中所有的样本用结巴分词切词并去重得到的大词袋,词袋 X a l l = ( x 1 , x 2 , . . , x k , . . , x n ) X_{all}=(x_1,x_2,..,x_k,..,x_n) Xall=(x1,x2,..,xk,..,xn);
- 橙色:每行的0-1数据就是该样本 X X X的
one-hot编码;
–-----------------------------------------------------------------------------—----------------------------------------
1.3、贝叶斯计算概率——训练阶段:
依照训练样本集 C = ( X 1 , X 2 , . . . , X n ) C=(X_1,X_2,...,X_n) C=(X1,X2,...,Xn)中的数据:
计算1:垃圾邮件的占比、非垃圾邮件的占比:
- P ( C = y i ) P(C=y_i) P(C=yi), y i ∈ y_i \in yi∈ ( 是 , 不 是 ) (是,不是) (是,不是)
计算2:词袋中每个词,在“是/非”垃圾邮件中出现的概率:
- P ( x 1 ∣ y i ) P(x_1|y_i) P(x1∣yi), P ( x 2 ∣ y i ) P(x_2|y_i) P(x2∣yi),…, P ( x k ∣ y i ) P(x_k|y_i) P(xk∣yi),…, P ( x n ∣ y i ) P(x_n|y_i) P(xn∣yi), y i ∈ y_i \in yi∈ ( 是 , 不 是 ) (是,不是) (是,不是)
–-----------------------------------------------------------------------------—----------------------------------------
1.4、贝叶斯计算概率——测试阶段:
有一测试数据 K K K转化为该词袋模型的one-hot编码为: K = ( x 1 , x 2 , . . . , x l ) K=(x_1,x_2,...,x_l) K=(x1,x2,...,xl),计算 m a x ( P ( x 1 , x 2 , . . . , x l ∣ 是 ) , P ( x 1 , x 2 , . . . , x l ∣ 不 是 ) ) max(P(x_1,x_2,...,x_l|是),P(x_1,x_2,...,x_l|不是)) max(P(x1,x2,...,xl∣是),P(x1,x2,...,xl∣不是)),哪个标签的概率大就归入哪个类。
–-----------------------------------------------------------------------------—----------------------------------------
–-----------------------------------------------------------------------------—----------------------------------------
–-----------------------------------------------------------------------------—----------------------------------------

二、举例:朴素贝叶斯做垃圾邮件分类
2.1、数据准备,数据处理阶段

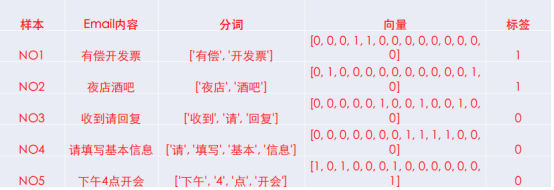
有一数据集如上,样本集 C C C一共切出14个词,组成的词袋如下:
- X a l l = X_{all}= Xall=[‘下午’, ‘酒吧’, ‘开会’, ‘开发票’, ‘有偿’, ‘回复’, ‘4’, ‘信息’, ‘请’, ‘基本’, ‘填写’, ‘收到’, ‘夜店’, ‘点’]
转化得到的one-hot编码矩阵如下:(标签——1:是垃圾邮件; 0:不是垃圾邮件)
–-----------------------------------------------------------------------------—----------------------------------------
2.2、贝叶斯计算概率——训练阶段:
计算1:垃圾邮件的占比、非垃圾邮件的占比:(已做拉普拉斯平滑)
- P ( C = 是 ) = P(C=是)= P(C=是)= 2 + 1 5 + 2 2+1 \over 5+2 5+22+1, P ( C = 不 是 ) = P(C=不是)= P(C=不是)= 3 + 1 5 + 2 3+1 \over 5+2 5+23+1
计算2:词袋中每个词,在“是/非”垃圾邮件中出现的概率如下:(已做拉普拉斯平滑)

举例,“下午”在垃圾邮件的概率=0.25、在非垃圾邮件的概率=0.4是如何计算的:
- 训练集中共有2条垃圾邮件,“下午”在垃圾邮件中出现的次数为0,出现的概率P(下午|是)=0/2,用拉普拉斯修正后=(0+1)/(2+2)=0.25;
- 训练集中共有3条非垃圾邮件,“下午”在非垃圾邮件中出现的次数为1,出现的概率P(下午|不是)=1/3,用拉普拉斯修正后=(1+1)/(3+2)=0.4;
重要说明:
从上表中可以发现,“下午”或其他一个词,在垃圾邮件中出现的概率 + 在非垃圾邮件中出现的概率并不一定等于1,这说明:同一个词语在“是/非”两个标签阵营下并不是完全对立的事件,换句话说 1 − 1- 1− P ( x k ∣ 不 是 ) P(x_k|不是) P(xk∣不是)不一定等于 P ( x k ∣ 是 ) P(x_k|是) P(xk∣是)。——这在下面样本测试阶段的时候就能知道它的重要性了。
–-----------------------------------------------------------------------------—----------------------------------------
2.3、贝叶斯计算概率——测试阶段:
测试: X n o w = X_{now}= Xnow=“请填写开发票信息”–>“请|填写|开发票|信息”–>[0,0,0,1,0,0,0,1,1,0,1,0,0,0]
在 X n o w X_{now} Xnow是垃圾邮件的前提下,新样本出现的概率:
- P ( X n o w ∣ 是 ) = P(X_{now}|是)= P(Xnow∣是)= P ( [ x 1 , x 2 , . . . , x 14 ] ∣ 1 ) = P([x_1,x_2,...,x_{14}]|1)= P([x1,x2,...,x14]∣1)= ( 1 − P ( x 1 ∣ 1 ) ) ∗ ( 1 − P ( x 2 ∣ 1 ) ) ∗ ( 1 − P ( x 3 ∣ 1 ) ) ∗ P ( x 4 ∣ 1 ) ∗ . . . (1-P(x_1|1))*(1-P(x_2|1))*(1-P(x_3|1))*P(x_4|1)*... (1−P(x1∣1))∗(1−P(x2∣1))∗(1−P(x3∣1))∗P(x4∣1)∗...
在 X n o w X_{now} Xnow不是垃圾邮件前提下,新样本出现的概率:
- P ( X n o w ∣ 不 是 ) = P(X_{now}|不是)= P(Xnow∣不是)= P ( [ x 1 , x 2 , . . . , x 14 ] ∣ 0 ) = P([x_1,x_2,...,x_{14}]|0)= P([x1,x2,...,x14]∣0)= ( 1 − P ( x 1 ∣ 0 ) ) ∗ ( 1 − P ( x 2 ∣ 0 ) ) ∗ ( 1 − P ( x 3 ∣ 0 ) ) ∗ P ( x 4 ∣ 0 ) ∗ . . . (1-P(x_1|0))*(1-P(x_2|0))*(1-P(x_3|0))*P(x_4|0)*... (1−P(x1∣0))∗(1−P(x2∣0))∗(1−P(x3∣0))∗P(x4∣0)∗...
最后哪个概率大,就把新样本分属到该类中。
说明:
- 如果 x i x_i xi在测试语句中出现了,就用其本身的条件概率,比如 x 4 , x 8 , x 9 , x 11 x_4,x_8,x_9,x_{11} x4,x8,x9,x11, 如果 x i x_i xi在测试语句中没有出现,就用(1-本身的条件概率)——(1-本身的条件概率)才是对立事件,因为 ( 1 − P ( x 1 ∣ 1 ) ) (1-P(x_1|1)) (1−P(x1∣1))不一定等于 P ( x 1 ∣ 0 ) P(x_1|0) P(x1∣0),所以 P ( X n o w ∣ 是 ) = P(X_{now}|是)= P(Xnow∣是)= P ( [ x 1 , x 2 , . . . , x 14 ] ∣ 1 ) = P([x_1,x_2,...,x_{14}]|1)= P([x1,x2,...,x14]∣1)= P ( x 1 ∣ 0 ) ∗ P ( x 2 ∣ 0 ) ∗ − P ( x 3 ∣ 0 ) ∗ P ( x 4 ∣ 1 ) ∗ . . . P(x_1|0)*P(x_2|0)*-P(x_3|0)*P(x_4|1)*... P(x1∣0)∗P(x2∣0)∗−P(x3∣0)∗P(x4∣1)∗...,这种计算方式是错误的,请务必知悉;
- 一般在计算过程中,为防止数值下逸,会在计算每个 x i x_i xi的概率后做 l o g ( ) log() log()处理。也就是说上式最终形态应该是: P ( X n o w ∣ 是 ) = P(X_{now}|是)= P(Xnow∣是)= P ( [ x 1 , x 2 , . . . , x 14 ] ∣ 1 ) = P([x_1,x_2,...,x_{14}]|1)= P([x1,x2,...,x14]∣1)= l o g ( 1 − P ( x 1 ∣ 1 ) ) ∗ l o g ( 1 − P ( x 2 ∣ 1 ) ) ∗ l o g ( 1 − P ( x 3 ∣ 1 ) ) ∗ l o g ( P ( x 4 ∣ 1 ) ) ∗ . . . log(1-P(x_1|1))*log(1-P(x_2|1))*log(1-P(x_3|1))*log(P(x_4|1))*... log(1−P(x1∣1))∗log(1−P(x2∣1))∗log(1−P(x3∣1))∗log(P(x4∣1))∗...
–-----------------------------------------------------------------------------—----------------------------------------
–-----------------------------------------------------------------------------—----------------------------------------
–-----------------------------------------------------------------------------—----------------------------------------
三、朴素贝叶斯做文本分类
–-----------------------------------------------------------------------------—----------------------------------------
本篇博客所用到的代码以及《谭松波酒店评论语料》都在这里可以下载
–-----------------------------------------------------------------------------—----------------------------------------
从《谭松波酒店评论语料》截取的部分好评、差评数据如下:


–-----------------------------------------------------------------------------—----------------------------------------
3.1、数据预处理
数据预处理阶段包括:整合数据生成样本空间、生成词袋、统计词频生成模型
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing CSDN address:https://blog.csdn.net/zzZ_CMing
# -*- 2019/04/24; 15:19
# -*- python3.6
import pandas as pd
import numpy as np
import jieba
import os
from sklearn.feature_extraction.text import CountVectorizer # 词频计数
from sklearn.feature_extraction.text import TfidfVectorizer # tf-idf 模块
def get_sent_readin_data(outputfile,input_fold,label_name):
"""
读取单个文件整合到一个文件中
:param outputfile: 输出的大文件地址
:param input_fold: 输入的单个小文件地址
:param label_name: 标签
:return: 整合后的两个大文件
"""
file_name_list = [k for i,j,k in os.walk(input_fold)][0]
neg_all = open(outputfile,'w', encoding="UTF-8")
for ifile in file_name_list:
with open(input_fold+ '%s'%ifile, 'r', encoding="UTF-8") as freaddata:
lines = freaddata.readlines()
writeline = ''.join([i.strip() for i in lines])
tlines = label_name + '\t' + writeline + '\n'
neg_all.write(tlines)
neg_all.close()
return 'Done!'
def get_neg_pos_data():
"""
整合正负例文本
:return: 返回正例样本和负例样本
"""
input_fold1='samples/neg/'
outputfile1='samples/neg_all.txt'
label_name1='neg'
get_sent_readin_data(outputfile1, input_fold1, label_name1)
input_fold2='samples/pos/'
outputfile2='samples/pos_all.txt'
label_name2='pos'
get_sent_readin_data(outputfile2, input_fold2, label_name2)
return outputfile1, outputfile2
neg_outfile, pos_outfile = get_neg_pos_data()
neg_data = pd.read_table(neg_outfile, names=['label','chat'])
pos_data = pd.read_table(pos_outfile, names=['label','chat'])
neg_data['labelnum']=-1
pos_data['labelnum']=1
–-----------------------------------------------------------------------------—----------------------------------------
# [1]:查看样本空间
all_data = pd.concat([neg_data, pos_data])
#print("all_data=", all_data.head())

–-----------------------------------------------------------------------------—----------------------------------------
# [2]:生成词袋
corpus=[' '.join(jieba.lcut(all_data.iloc[i,1])) for i in range(len(all_data))]
# print("corpus=", corpus)

–-----------------------------------------------------------------------------—----------------------------------------
# [3]:计数统计,tf-idf模块
vectorizer = CountVectorizer()
corpusTotoken_count = vectorizer.fit_transform(corpus).todense()
vectorizer = TfidfVectorizer()
corpusTotoken_tfidf = vectorizer.fit_transform(corpus).todense()
# print("corpusTotoken_count=", corpusTotoken_count)
# print("corpusTotoken_tfidf=", corpusTotoken_tfidf)
X_data = np.array(corpusTotoken_count)
Y_data = np.array(all_data['labelnum'])
# print(X_data.shape)
# print(Y_data.shape)
–-----------------------------------------------------------------------------—----------------------------------------
–-----------------------------------------------------------------------------—----------------------------------------
3.2、训练阶段
用线性回归和伯努利贝叶斯算法进行预测,并生成预测准确率变化图
# [4]:训练阶段
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # 分割数据集
x_train, x_test, y_train, y_test = train_test_split(X_data, Y_data, test_size = 0.3)
## LR 预测
from sklearn.linear_model.logistic import LogisticRegression
LR = LogisticRegression()
LR.fit(x_train,y_train)
predictions_LR = LR.predict(x_test)
prob_LR=LR.predict_proba(x_test)
## Bernoulli bayes 预测
from sklearn.naive_bayes import BernoulliNB
GB = BernoulliNB()
GB.fit(x_train,y_train)
predictions_GB = GB.predict(x_test)
prob_GB=GB.predict_proba(x_test)
# 准确率变化图
from sklearn.metrics import roc_curve, auc
fpr_LR, tpr_LR, thresholds = roc_curve(y_test, prob_LR[:, 1])
roc_auc_LR = auc(fpr_LR, tpr_LR)
print("roc_auc_LR=", roc_auc_LR)
fpr_GB, tpr_GB, thresholds = roc_curve(y_test, prob_GB[:, 1])
roc_auc_GB = auc(fpr_GB, tpr_GB)
print("roc_auc_GB=", roc_auc_GB)
plt.figure(figsize=(8,6))
plt.title('Receiver Operating Characteristic')
plt.plot(fpr_LR, tpr_LR, 'b', label='LR_AUC = %0.2f'% roc_auc_LR)
plt.plot(fpr_GB, tpr_GB, 'y', label='GB_AUC = %0.2f'% roc_auc_GB)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([-0.1,1.2])
plt.ylim([-0.1,1.2])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
回归预测与伯努利贝叶斯预测生成的准确图如下:

–-----------------------------------------------------------------------------—----------------------------------------
–-----------------------------------------------------------------------------—----------------------------------------
3.3、测试阶段
输入一句新的样本数据sent ,启用模型,生成预测的分类结果
# [5]:测试阶段
sent = '房间较为简单,非常干净.'
sent_cut=jieba.lcut(sent)
sent_cut_input=' '.join(sent_cut)
print("切词结果:", sent_cut_input)
Xpredict=vectorizer.transform([sent_cut_input]).todense()
print("预测的准确率=", GB.predict_proba(Xpredict))
print("预测的标签=", GB.predict(Xpredict))
得到的预测结果如下,可以通过预测的准确率发现,房间较为简单,非常干净百分之99%是一条好评;

–-----------------------------------------------------------------------------—----------------------------------------
本篇博客所用到的代码以及《谭松波酒店评论语料》都在这里可以下载
–-----------------------------------------------------------------------------—----------------------------------------