第一章:
中文分词 jieba
关键词提取 tf-idf #tankage
正则表达式
第二章
- 朴素贝叶斯模型
P( Category | Document) = P ( Document | Category ) * P( Category) / P(Document)
统计垃圾邮件
条件独立假设
词袋子模型
简单粗暴蠢萌,基于统计
sklearn.feature_extraction.text.countVectorizer
多项式模型:重复的词语视为出现多次
伯努利模型:重复的词语视为出现1次

#混合模型:混合
统计词出现次数
概率为0,数据平滑
平滑算法

实际工程问题
计算机精度问题,时间消耗问题:取对数,存hash表
转换为权重
选取topk的关键词#K值 机器学习交叉验证来获取
分割样本权重
位置权重
蜜罐

P(X|Y)似然函数
先验概率是否需要平和
应用
1褒贬分析
工程问题:
否定词进行特别处理
相关情感词出现少则采用伯努利模型
副词对情感评价有一定影响:不很喜欢和很不喜欢
情感表达含蓄
转折性表达
2.
拼写纠错
- N-gram语言模型
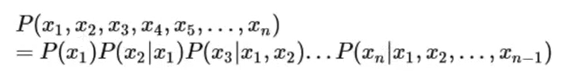
从假设性独立到联合概率链规则
联合概率链规则在实际中无法使用所以我们想办法去近似这个公式
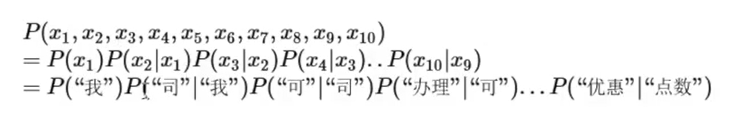
从联合概率链规则到2-gram
拉长依赖词长度
马尔科夫假设:下面的词出现仅仅依赖于它前面的一个或几个词
n的选择
n变大的问题:
训练预料有限,容易数据稀疏
参数空间太大无法实用

一般选3,数据量很大可以取更大
应用:词性标注
垃圾邮件分类升级版
中文分词
机器翻译和语音识别
平滑
拉普拉斯平滑 +1 古德图灵平滑 组合估计平滑
