注意:这是一个完整的项目,建议您按照完整的博客顺序阅读。
目录
三、训练和优化CNN模型
搭建好CNN模型的计算图之后,我们就可以来训练和优化该CNN模型了,即运行计算图。
1、搭建训练主循环
众所周知,TensorFlow是基于计算图的框架,想要使用计算图来训练神经网络,我们只需要通过TensorFlow的会话运行它的优化器即可,注意要feed数据,即训练CNN模型的核心就是如下代码:
# 开始训练
for i in range(num_iteration):
# 获取训练集中的数据
x_batch, y_true_batch, _, cls_batch = data.train.next_batch(batch_size)
# 构建feed计算图的字典
feed_dict_tr = {self.x: x_batch, self.y_true: y_true_batch}
# 执行优化器操作
self.session.run(self.optimizer, feed_dict=feed_dict_tr)
# To Do 1
在上述代码中,首先我们获取到读取到的DataSets对象,然后访问它的训练集部分即可得到训练集数据:data.train.next_batch(batch_size),这在数据预处理部分介绍过DataSets对象。
接下来我们要运行self.session.run(self.optimizer, feed_dict=feed_dict_tr)
这个self.session是之前创建CNN模型时生成的,这里依然使用它,run的是self.optimizer,需要feed一个feed_dict,即我们在运行计算图时,要给变量不断赋值,我们之前是使用占位符定义的输入输出变量,此时它们并没有存储数据,所以在训练时要feed。
有了这个主要结构我们基本就可以训练CNN模型了,但是仅有这个还是不够的。
因为这样子我们无法得知训练的实时情况,所以最常见的是我们要定时输出一些信息,所以我们需要加一个判断条件,由于我们的训练集比较小,所以这里我们检查它跑完一次训练集就输出一次信息,顺便计算一次损失值、精度、保存一次CNN模型等,所以我们在上述代码的"To Do 1"下继续添加代码:
# 定期计算损失、保存模型、打印信息
if i % int(data.train.num_examples / batch_size) == 0:
# 使用验证集计算损失
val_loss = self.session.run(self.cost, feed_dict=feed_dict_val)
# 使用训练集计算损失
tr_loss = self.session.run(self.cost, feed_dict=feed_dict_tr)
# 计算回合数
epoch = int(i / int(data.train.num_examples / batch_size))
# 保存CNN模型
saver.save(self.session, './dogs-cats-model/dog-cat.ckpt', global_step=i)
# 打印信息
self.__show_pregress(epoch, feed_dict_tr, feed_dict_val, val_loss, tr_loss,i)
# To do 2
上述代码中,我们使用self.session.run(self.cost, feed_dict)来计算损失值
使用tf.train.saver.save(self.session,)来保存CNN模型,注意,这里使用了一种技巧来计算和判断是否训练完整个训练集:
| i % int(data.train.num_examples / batch_size) == 0 |
i是否是(训练集总数/批次大小)的倍数 |
| int(i / int(data.train.num_examples / batch_size)) |
i里面有几个(训练集总数/批次大小) |
打印信息使用我们自定义的方法:
# 显示训练进度信息
def __show_pregress(self,epoch, feed_dict_train, feed_dict_validata, val_loss,tr_loss, i):
tra_acc = self.session.run(self.accuracy, feed_dict=feed_dict_train)
val_acc = self.session.run(self.accuracy, feed_dict=feed_dict_validata)
msg = "训练回合数:{0}-迭代次数:{1},训练精度:{2:>6.1%},验证精度:{3:>6.1%},验证损失值:{4:.3f}"
print(msg.format(epoch + 1, i, tra_acc, val_acc, val_loss))
self.train_acc_list.append(tra_acc*100) # 训练精度列表
self.val_acc_list.append(val_acc*100) # 验证精度列表
self.train_loss_list.append(tr_loss) # 验证精度列表
self.val_loss_list.append(val_loss) # 验证精度列表
self.iter_list.append(epoch) # 迭代次数列表
最终,我们会打印出如下信息:

2、训练时间的记录
训练时间的记录,就是记录训练一共花费了多少时间,这不是一个必备项,但是相关代码也放出来:
# 记录开始训练的时刻
start_time = time.time()
(........)
# 计算训练花费的时间并打印
end_time = time.time()
time_dif = end_time - start_time
print("本次训练总共花费的Time: " + str(timedelta(seconds=int(round(time_dif)))))
3、早期终止机制
假设我们直接训练10000回合,而模型在8000回合时基本就达到最佳性能,那么剩余的2000次都基本是性能的一种浪费,所以我们考虑引入早期终止机制。
早期终止机制就是记录下训练的最小损失值,如果每次计算出的损失值连续n次都没有超过这个最小损失值,那么我们就停止训练,这个n是我们可以设置的一个超参数。这种设置可以通过以下技巧实现:
# 早期终止机制所需的变量
early_stopping = None # 定义None表示不启用,启用设置为数字
best_val_loss = float("inf")
patience = 0
(........)
# 判断是否进行早期终止
if early_stopping:
if val_loss < best_val_loss:
best_val_loss = val_loss
patience = 0
else:
patience += 1
if patience == early_stopping:
break
4、训练数据的可视化
我们将使用TensorFlow搭建一个CNN模型,这个CNN模型
import matplotlib.pyplot as plt
from matplotlib.ticker import MultipleLocator
plt.rcParams['font.sans-serif']=['SimHei'] #使用中文字符
plt.rcParams['axes.unicode_minus'] = False #显示负数的负号
# 创建画布
fig = plt.figure(figsize=(12, 6)) # 创建一个指定大小的画布
fig.canvas.set_window_title('猫狗识别器的训练情况')
# 添加第1个窗口
ax1 = fig.add_subplot(121) # 添加一个1行2列的序号为1的窗口
# 添加标注
ax1.set_title('训练中的损失变化', fontsize=14) # 设置标题
ax1.set_xlabel('x(训练次数)', fontsize=14, fontfamily='sans-serif', fontstyle='italic')
ax1.set_ylabel('y(损失大小)', fontsize=14, fontstyle='oblique')
ax1.set_ylim(0, 1)
ax1.xaxis.set_major_locator(MultipleLocator(1)) # 设置x轴的间隔
# 绘制函数
line1, = ax1.plot(self.iter_list, self.train_loss_list, color='blue', label="训练集")
line2, = ax1.plot(self.iter_list, self.val_loss_list, color='red', label="验证集")
ax1.legend(handles=[line1, line2], loc=2) # 绘制图例说明
# plt.grid(True)#启用表格
# 添加第2个窗口
ax2 = fig.add_subplot(122) # 添加一个1行2列的序号为1的窗口
# 添加标注
ax2.set_title('训练中的正确率变化', fontsize=14) # 设置标题
ax2.set_xlabel('x(训练次数)', fontsize=14, fontfamily='sans-serif', fontstyle='italic')
ax2.set_ylabel('y(正确率%)', fontsize=14, fontstyle='oblique')
ax2.set_ylim(0, 100)
ax2.xaxis.set_major_locator(MultipleLocator(1))# 设置x轴的间隔
# 绘制函数
line1, = ax2.plot(self.iter_list, self.train_acc_list, color='blue', label="训练集")
# 绘制函数
line2, = ax2.plot(self.iter_list, self.val_acc_list, color='red', label="验证集")
ax2.legend(handles=[line1, line2], loc=1) # 绘制图例说明
# plt.grid(True) #启用表格
最终显示效果:
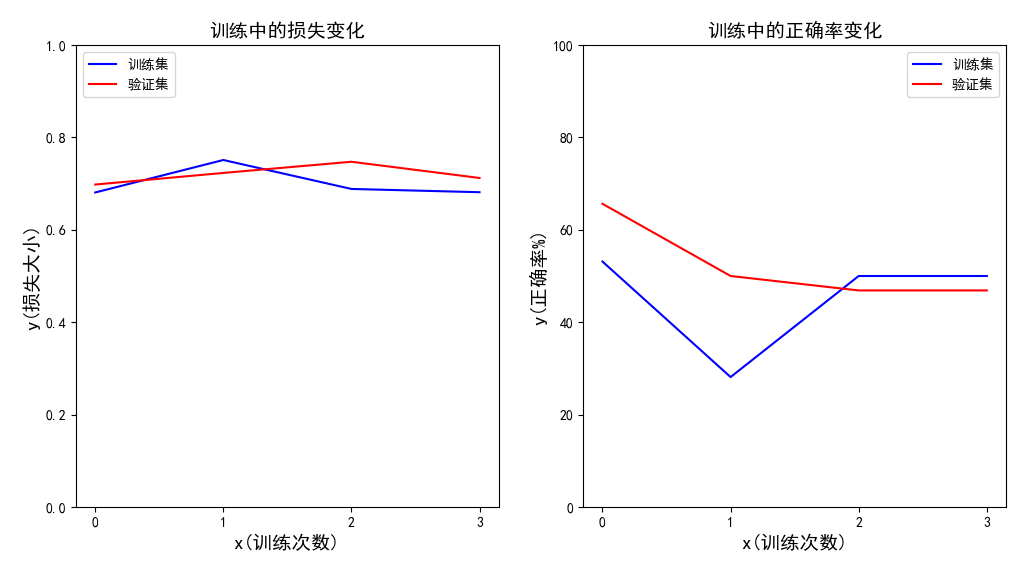
5、训练数据的保存与加载
保存数组数据的相关代码:
data = {"train_acc_list": [w.tolist() for w in self.train_acc_list],
"val_acc_list": [w.tolist() for w in self.val_acc_list],
"train_loss_list": [w.tolist() for w in self.val_acc_list],
"val_loss_list": [w.tolist() for w in self.val_loss_list],
"iter_list": [w for w in self.iter_list]}
f = open(filename, "w")
json.dump(data, f) # 将Python数据结构编码为JSON格式并且保存至文件中
f.close() # 关闭文件
print("训练检测数据成功保存至{}文件".format(filename))
加载数组数据的相关代码:
f = open(filename, "r")
data = json.load(f) # 将文件中的JSON格式解码为Python数据结构
f.close()
self.train_acc_list = [np.array(w) for w in data["train_acc_list"]]
self.val_acc_list = [np.array(w) for w in data["val_acc_list"]]
self.train_loss_list = [np.array(w) for w in data["train_loss_list"]]
self.val_loss_list = [np.array(w) for w in data["val_loss_list"]]
self.iter_list = [ w for w in data["iter_list"]]
print("训练检测数据已成功读取到构造器中...")
四、测试和运用CNN模型
1、加载训练好的模型
使用TensorFlow加载一个保存的CNN模型,并重建其中的变量:
# 加载训练好的模型
self.sess = tf.Session()
saver = tf.train.import_meta_graph('./dogs-cats-model/dog-cat.ckpt-9975.meta')
saver.restore(self.sess, './dogs-cats-model/dog-cat.ckpt-9975')
graph = tf.get_default_graph()
# 重建变量
self.x = graph.get_tensor_by_name("x:0")
self.y_true = graph.get_tensor_by_name("y_true:0")
self.y_pred = graph.get_tensor_by_name("y_pred:0")
self.y_pred_cls = tf.argmax(self.y_pred, axis=1)
2、调用训练好的模型
使用模型预测输入:
# 运行模型得出结果
feed_dict_test = {
self.x: images,
self.y_true: np.zeros((len(images),2))
}
result = self.sess.run(self.y_pred, feed_dict=feed_dict_test)
res_label = ['dogs', 'cats']
result = [res_label[r.argmax()] for r in result]
3、查看TensorBoard
训练完后保存训练信息的代码:
# 输出训练信息到日志中
writer = tf.summary.FileWriter(self.log_path, self.session.graph)
writer.close()
path = os.path.dirname(os.path.abspath(__file__))+"\\"+self.log_path
print("训练日志已经保存至路径:{} ".format(path))
查看TensorBoard:

主要的是如下的代码:
tensorboard --logdir=path/to/log-directory