本章主要内容
- 探索GAN与对抗训练背后的理论
- 了解GAN与传统神经网络的区别
- Keras中实现GAN并训练它,以生成手写数字
本章将探讨GAN背后的基础理论,然后介绍一些如果深入研究这个领域可能会遇到的常用数学表示。这些描述要么是你在更侧重于理论的出版物中看到的,要么是在关于这个主题的许多学术论文中看到的。本章也为后续章节提供了背景知识,特别是第5章。
但从严格的实用角度来看,你不必为这些形式担心,就像不需要知道发动机如何运转就可以驾车一样。用如Keras和TensorFlow这样的机器学习库提取出基础数学知识,并巧妙地把它们打包成可导入的代码行。
这将是本书中反复出现的主题,在机器学习和深度学习中也是如此。如果你愿意直接进入实践部分,也可以粗略浏览理论部分并跳到代码教程部分(3.4节)。
3.1 GAN的基础:对抗训练
形式上,生成器和鉴别器由可微函数表示如神经网络,它们都有自己的代价函数。这两个网络是利用鉴别器的损失进行反向传播训练。鉴别器努力使真实样本输入和伪样本输入带来的损失最小化,而生成器努力使它生成的伪样本造成的鉴别器损失最大化。
图3.1总结了这一动态过程。它是第1章中GAN结构图的一个更通用的版本——第一次解释了什么是GAN以及它们是如何工作的。与第1章中手写数字的示例不同,在图3.1中,训练数据集理论上可以是任何东西,具有普遍性。
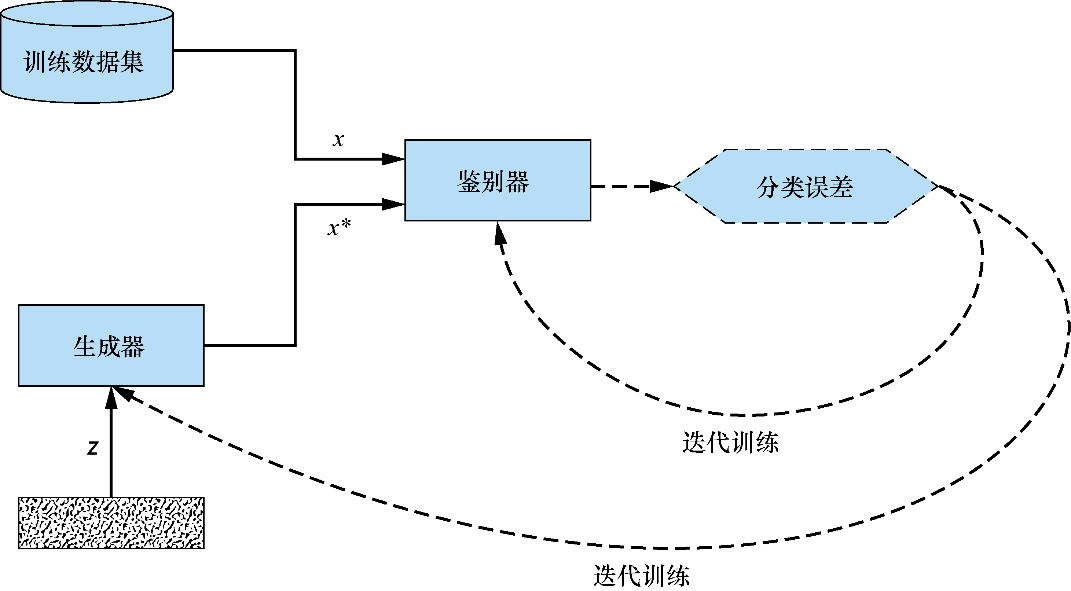
图3.1 在这个GAN结构图中,生成器和鉴别器都利用鉴别器损失进行训练。鉴别器努力使损失最小化,生成器则努力使它产生的伪样本对应的损失最大化
训练数据集决定了生成器要学习模拟的样本类型,例如,目标是生成猫的逼真图像,我们就会给GAN提供一组猫的图像。
用更专业的术语来说,生成器的目标是生成符合训练数据集数据分布的样本。[1] 对计算机来说,图像只是矩阵:灰度图像是二维的,彩色图像是三维的。当在屏幕上呈现时,这些矩阵中的像素值将显示为图像线条、边缘、轮廓等的所有视觉元素。这些值在数据集中的每个图像上遵循复杂的分布,如果没有分布规律,图像将不过是些随机噪声。目标识别模型学习图像中的模式以识别图像的内容,生成器所做的可以认为是相反的过程:它学习合成这些模式,而不是识别这些模式。
3.1.1 代价函数
遵循标准的表示形式,用
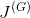
表示生成器的代价函数,用
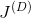
表示鉴别器的代价函数。两个网络的训练参数(权重和偏置)用希腊字母表示:
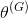
表示生成器,
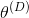
表示鉴别器。
GAN在两个关键方面不同于传统的神经网络。第一,代价函数
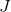
,传统神经网络的代价函数仅根据其自身可训练的参数定义,数学表示为
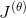
。相比之下,GAN由两个网络组成,其代价函数依赖于两个网络的参数。也就是说,生成器的代价函数是
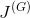
(
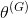
,
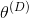
),而鉴别器的成本函数是
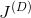
(
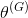
,
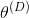
)。[2]
第二,在训练过程中,传统的神经网络可以调整它的所有参数θ。在GAN中,每个网络只能调整自己的权重和偏置。也就是说,在训练过程中,生成器只能调整
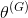
,鉴别器只能调整
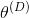
。因此,每个网络只控制了决定损失的部分参量。
为了使上述内容不那么抽象,考虑下面这个类比。想象一下我们正在选择下班开车回家的路线,如果交通不堵塞,最快的选择是高速公路,但在交通高峰期,优选是走一条小路。尽管小路更长更曲折,但当高速公路上交通堵塞时,走小路可能会更快地回家。
让我们把它当作一道数学题——
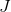
作为代价函数,并定义为回家所需的时间。我们的目标是尽量减小
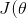
。为简单起见,假设离开办公室的时间是固定的,既不能提前离开,也不能为了避开高峰时间而晚走。所以唯一能改变的参数是路线θ。
如果我们所拥有的是路上唯一的车,代价将类似于一个常规的神经网络:它将只取决于路线,且优化
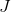
)完全在我们的能力范围内。然而,一旦将其他驾驶员引入方程式,情况就会变得更加复杂。突然之间,我们回家的时间不仅取决于自己的决定,还取决于其他驾驶员的行路方案,即
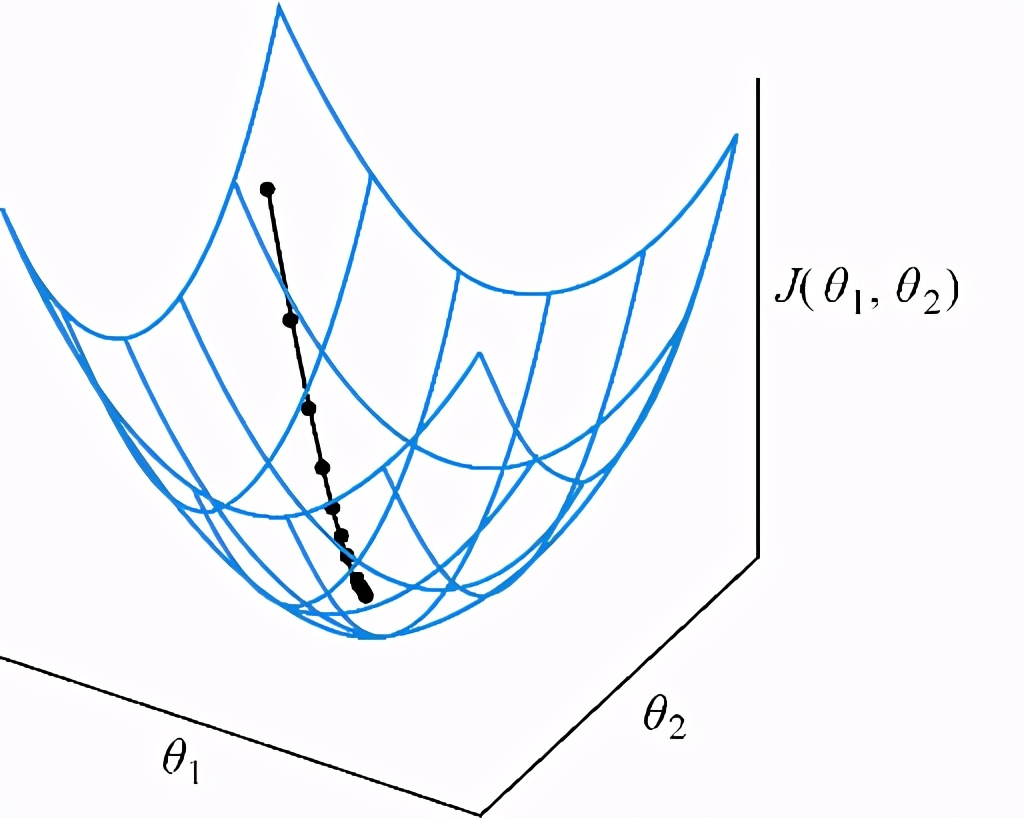
(θ 我们, θ 其他驾驶员)。就像生成器网络和鉴别器网络一样,“代价函数”将取决于各种因素的相互作用,其中一些因素在我们的掌控之下,而另一些因素则不在。
3.1.2 训练过程
上面所描述的两个差异对GAN的训练过程有着深远的影响。传统神经网络的训练是一个优化问题,通过寻找一组参数来最小化代价函数,移动到参数空间中的任何相邻点都会增加代价。这可能是参数空间中的局部或全局最小值,由寻求最小化使用的代价函数所决定。最小化代价函数的优化过程如图3.2所示。
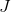
(来源:Adversarial Machine Learning, by Ian Goodfellow, ICLR Keynote, 2019.)
图3.2 碗形网格表示参数空间θ1和θ2中的损失
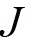
。黑色点线表示通过优化使参数空间中的损失最小化
因为生成器和鉴别器只能调整自己的参数而不能相互调整对方的参数,所以GAN训练可以用一个博弈过程来更好地描述,而非优化。[3] 该博弈中的对手是GAN所包含的两个网络。
回顾第1章,当两个网络达到纳什均衡时GAN训练结束,在纳什均衡点上,双方都不能通过改变策略来改善自己的情况。从数学角度来说,发生在这样的情况下——生成器的可训练参数
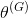
对应的生成器的代价函数
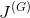
(
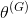
,
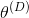
)最小化;同时,对应该网络参数
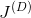
下的鉴别器的代价函数
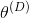
(
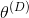
,
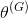
)也得到最小化。[4] 图3.3说明了二者零和博弈的建立和达到纳什均衡的过程。
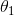
图3.3 玩家1(左)试图通过调整
来最小化
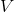
。玩家2(中间)试图通过调整
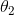
来(最大化
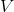
)最小化
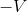
。鞍形网格(右)显示了参数空间
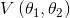
中的组合损失。虚线表示在鞍形中心收敛到纳什均衡
回到我们的类比,对于我们和可能在路上遇到的所有其他驾驶员来说,当每一条回家的路线所花费的时间都完全相同时,纳什均衡将会发生。任何更快的路线都会被交通拥堵量的成比例增长所抵消,从而减缓了每个人的速度。而这种状态在现实生活中几乎是无法实现的,即便使用像谷歌地图这样提供实时流量更新的工具,也不可能完美地评估出回家的最佳路径。
这同样适用于训练GAN网络时的高维、非凸情况。即使是像MNIST数据集中的那些小到只有28×28像素的灰度图像,也有28×28=784维。如果它们被着色(RGB),它们的维数将增加到3倍变成2352。在训练数据集中的所有图像上捕获这种分布非常困难,特别是当最好的学习方法是从对手(鉴别器)那里学习时。
成功地训练GAN需要反复试验,尽管有最优方法,但它是一门科学的同时也是一门艺术。第5章详细讨论了GAN的收敛问题。现在大可放心,情况并没有听起来那么糟。正如在第1章中预告的那样,也正如本书将展示的那样,无论是近似生成分布的巨大复杂性,还是对GAN收敛条件理解的缺乏,都没有阻碍GAN的实际可用性和生成真实数据样本的能力。
3.2 生成器和鉴别器
现在通过引入更多的表示概括所学的内容。生成器
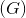
接收随机噪声向量
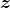
并生成一个伪样本
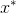
。数学上来说,
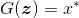
。鉴别器
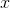
的输入要么是真实样本
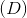
,要么是伪样本
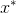
;对于每个输入,它输出一个介于0和1之间的值,表示输入是真实样本的概率。图 3.4用刚才介绍的术语和符号描述了GAN架构。
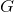
图3.4 生成器网络
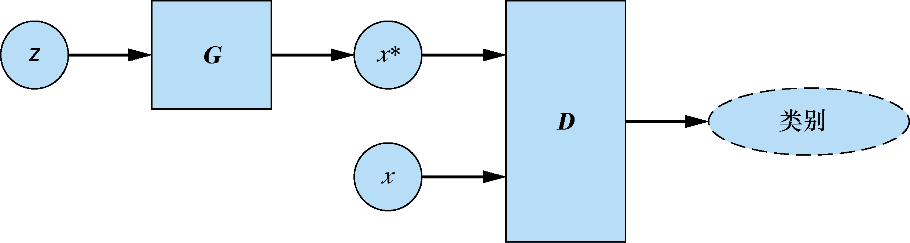
将随机向量

转换为伪样本
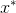
:
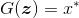
。鉴别器网络
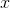
对输入样本是否真实进行分类并输出。对于真实样本
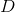
,鉴别器力求输出尽可能接近1的值;对于伪样本
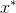
,鉴别器力求输出尽可能接近0的值。相反,生成器希望
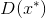
尽可能接近1,这表明鉴别器被欺骗,将伪样本分类为真实样本
3.2.1 对抗的目标
鉴别器的目标是尽可能精确。对于真实样本
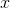
,
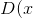
)力求尽可能接近1(正的标签);对于伪样本
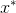
,
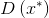
力求尽可能接近0(负的标签)。
生成器的目标正好相反,它试图通过生成与训练数据集中的真实数据别无二致的伪样本
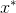
来欺骗鉴别器。从数学角度讲,即生成器试图生成假样本
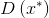
,使得
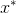
尽可能接近1。
3.2.2 混淆矩阵
鉴别器的分类可以用混淆矩阵来表示,混淆矩阵是二元分类中所有可能结果的表格表示(表3.1)。鉴别器的分类结果如下:
(1)真阳性(true positive)——真实样本正确分类为真
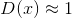
;
(2)假阴性(false negative)——真实样本错误分类为假
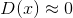
;
(3)真阴性(true negative)——伪样本正确分类为假
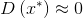
;
(4)假阳性(false positive)——伪样本错误分类为真
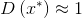
。
表3.1 鉴别器结果的混淆矩阵
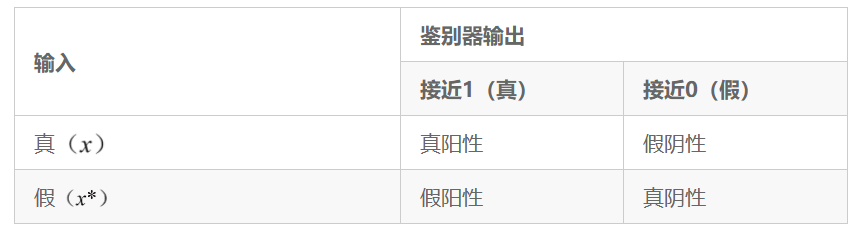
使用混淆矩阵的术语,鉴别器试图最大化真阳性和真阴性分类,这等同于最小化假阳性和假阴性分类。相反,生成器的目标是最大化鉴别器的假阳性分类,这样生成器才能成功地欺骗鉴别器,使其相信伪样本是真的。生成器不关心鉴别器对真实样本的分类效果如何,只关心对伪样本的分类。
3.3 GAN训练算法
回顾一下第1章中的GAN训练算法,并使用本章介绍的符号将其规范化。与第1章中的算法不同,这里介绍的算法使用小批量(mini-batch)而不是一次使用一个样本。
GAN训练算法
对于每次训练迭代,执行
(1)训练鉴别器。
a. 取随机的小批量的真实样本
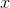
。
b. 取随机的小批量的随机噪声
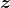
,并生成一小批量伪样本:
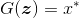
。
c. 计算
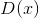
和
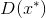
的分类损失,并反向传播总误差以更新
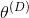
来最小化分类损失。
(2)训练生成器。
a. 取随机的小批量的随机噪声
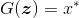
生成一小批量伪样本:
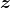
。
b. 用鉴别器网络对
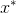
进行分类。
c. 计算
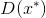
的分类损失,并反向传播总误差以更新
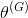
来最大化分类损失。
结束
注意,在步骤1中训练鉴别器时,生成器的参数保持不变;同样,在步骤2中,在训练生成器时保持鉴别器的参数不变。之所以只允许更新被训练网络的权重和偏置,是因为要将所有更改隔离到仅受该网络控制的参数中。这可以确保每个网络都能获得如何进行更新的相关信号,而不受其他网络更新的干扰。你可以把这想象成两个对手在轮流比赛。
当然,你还可以想象这样一种场景,如果每个玩家只不过是在撤销对方的进度,那么即使是回合制游戏,也不能保证产生有用的结果。(前面有没有说过GAN训练起来非常棘手?)第5章还将讨论最大限度地提高成功机会的技术。
理论就是这些,现在把学到的付诸实践,实现我们的第一个GAN吧!
3.4 教程:生成手写数字
本节将实现一个GAN,它将学习生成外观逼真的手写数字,用的是带有TensorFlow后端的Python神经网络库Keras。图3.5显示了将实现的GAN的高级架构。
本教程中使用的大部分代码,特别是训练循环中使用的样板,都是Erik Linder Norén创建的开源Github存储库Keras-GAN改编而来的。存储库还包括几个高级的GAN变体,其中一些将在本书后面介绍。在代码和网络架构方面,我们对其进行了很大的修改和简化并重命名了变量,使它们与本书中使用的表示方法一致。
Jupyter Notebook版的完整实现,包括对训练进度的可视化,可在配套资源的第3章文件夹中找到。代码用Python 3.6.0、Keras 2.1.6和TensorFlow 1.8.0版本测试过。
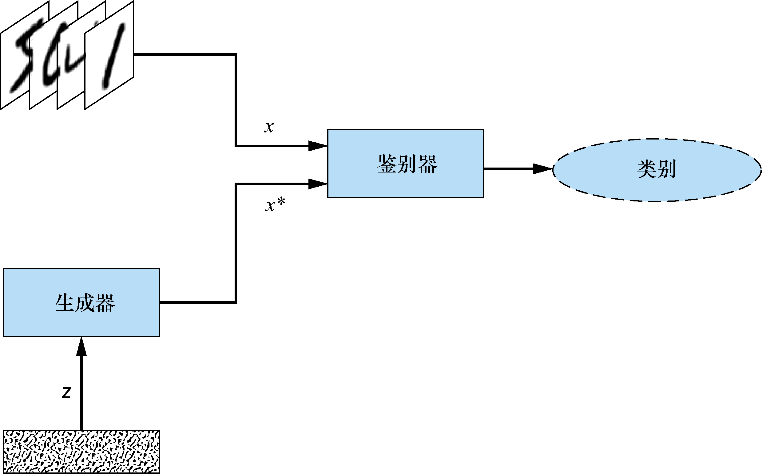
图3.5 在训练迭代过程中,生成器学习将输入的随机噪声转换为看起来像训练数据集(MNIST手写数字数据集)中的图像;同时,鉴别器学习区分由生成器生成的伪图像和来自训练数据集的真实图像
3.4.1 导入模块并指定模型输入维度
首先导入运行模型所需的所有包和库,如清单3.1所示。注意:此处还直接从keras.datasets导入了MNIST手写数字数据集。
清单3.1 Import statements
%matplotlib inlineimport matplotlib.pyplot as pltimport numpy as npfrom keras.datasets import mnistfrom keras.layers import Dense, Flatten, Reshapefrom keras.layers.advanced_activations import LeakyReLUfrom keras.models import Sequentialfrom keras.optimizers import Adam
然后指定模型和数据集的输入维度,如清单3.2所示。MNIST中的每个图像都是28×28像素的单通道图像(灰度图)。变量z_dim设置了噪声向量
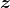
的大小。
清单3.2 模型输入维度
img_rows = 28img_cols = 28channels = 1img_shape = (img_rows, img_cols, channels) ⇽--- 输入图片的维度z_dim = 100 ⇽--- 噪声向量的大小用作生成器的输入
接下来实现生成器和鉴别器网络。
3.4.2 构造生成器
简而言之,生成器是一个只有一个隐藏层的神经网络。如清单3.3所示,生成器以
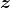
为输入,生成28×28×1的图像。在隐藏层中使用LeakyReLU激活函数。与将任何负输入映射到0的常规ReLU函数不同,LeakyReLU函数允许存在一个小的正梯度,这样可以防止梯度在训练过程中消失,从而产生更好的训练效果。
在输出层使用tanh激活函数,它将输出值缩放到范围[–1, 1]。之所以使用tanh(与sigmoid不同,sigmoid会输出更为典型的0到1范围内的值),是因为它有助于生成更清晰的图像。
清单3.3 生成器
def build_generator(img_shape, z_dim): model = Sequential() model.add(Dense(128, input_dim=z_dim)) ⇽--- 全连接层 model.add(LeakyReLU(alpha=0.01)) ⇽--- LeakyReLU激活函数 model.add(Dense(28 * 28 * 1, activation='tanh')) ⇽--- 带tanh激活函数的输出层 model.add(Reshape(img_shape)) ⇽--- 生成器的输出改变为图像尺寸 return model
3.4.3 构造鉴别器
鉴别器接收28×28×1的图像,并输出表示输入是否被视为真而不是假的概率。鉴别器由一个两层神经网络表示,其隐藏层有128个隐藏单元及激活函数为LeakyReLU。
为简单起见,我们构造的鉴别器网络看起来与生成器几乎相同,但并非必须如此。实际上,在大多数GAN的实现中,生成器和鉴别器网络体系结构的大小和复杂性都相差很大。
注意,与生成器不同的是,清单3.4中鉴别器的输出层应用了sigmoid激活函数。这确保了输出值将介于0和1之间,可以将其解释为生成器将输入认定为真的概率。
清单3.4 鉴别器
def build_discriminator(img_shape): model = Sequential() model.add(Flatten(input_shape=img_shape)) ⇽--- 输入图像展平 model.add(Dense(128)) ⇽--- 全连接层 model.add(LeakyReLU(alpha=0.01)) ⇽--- LeakyReLU激活函数 model.add(Dense(1, activation='sigmoid')) ⇽--- 带sigmoid激活函数的输出层 return model
3.4.4 搭建整个模型
在清单3.5中构建并编译先前实现的生成器模型和鉴别器模型。注意:在用于训练生成器的组合模型中,通过将discriminator.trainable设置为False来固定鉴别器参数。还要注意的是,组合模型(其中鉴别器设置为不可训练)仅用于训练生成器。鉴别器将用单独编译的模型训练。(当回顾训练循环时,这一点会变得很明显。)
使用二元交叉熵作为在训练中寻求最小化的损失函数。二元交叉熵(binary cross-entropy)用于度量二分类预测计算的概率和实际概率之间的差异;交叉熵损失越大,预测离真值就越远。
优化每个网络使用的是Adam优化算法。该算法名字源于adaptive moment estimation,这是一种先进的基于梯度下降的优化算法,对其工作原理的阐释超出了本书的范围,但可以说Adam凭借其通常优异的性能已经成为大多数GAN的首选优化器。
清单3.5 构建并编译GAN
def build_gan(generator, discriminator): model = Sequential() model.add(generator) ⇽--- 生成器模型和鉴别器模型结合到一起 model.add(discriminator) return model discriminator = build_discriminator(img_shape) ⇽--- 构建并编译鉴别器discriminator.compile(loss='binary_crossentropy', optimizer=Adam(), metrics=['accuracy']) generator = build_generator(img_shape, z_dim) ⇽--- 构建生成器discriminator.trainable = False ⇽--- 训练生成器时保持鉴别器的参数固定gan = build_gan(generator, discriminator) ⇽--- 构建并编译鉴别器固定的GAN模型,以训练生成器gan.compile(loss='binary_crossentropy', optimizer=Adam())
3.4.5 训练
清单3.6实现了GAN训练算法。首先,取随机小批量的MNIST图像为真实样本,从随机噪声向量
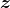
中生成小批量伪样本,然后在保持生成器参数不变的情况下,利用这些伪样本训练鉴别器网络。其次,生成一小批伪样本,使用这些图像训练生成器网络,同时保持鉴别器的参数不变。算法在每次迭代中都重复这个过程。
我们使用独热编码(one-hot-encoded)标签:1代表真实图像,0代表伪图像。
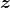
从标准正态分布(平均值为0、标准差为1的钟形曲线)中取样得到。训练鉴别器使得假标签分配给伪图像,真标签分配给真图像。对生成器进行训练时,生成器要使鉴别器能将真实的标签分配给它生成的伪样本。
注意:训练数据集中的真实图像被重新缩放到了−1到1。如前例所示,生成器在输出层使用tanh激活函数,因此伪样本同样将在范围(−1,1)内。相应地,就得将鉴别器的所有输入重新缩放到同一范围。
清单3.6 GAN训练循环
losses = []accuracies = []iteration_checkpoints = []def train(iterations, batch_size, sample_interval):
(X_train, _), (_, _) = mnist.load_data() ⇽--- 加载MINST数据集
X_train = X_train / 127.5 - 1.0 ⇽--- 灰度像素值[0, 255]缩放到[−1,1]
X_train = np.expand_dims(X_train, axis=3)
real = np.ones((batch_size, 1)) ⇽--- 真实图像的标签都是1
fake = np.zeros((batch_size, 1)) ⇽--- 伪图像的标签都是0
for iteration in range(iterations):
idx = np.random.randint(0, X_train.shape[0], batch_size) ⇽--- 随机噪声采样
imgs = X_train[idx]
z = np.random.normal(0, 1, (batch_size, 100)) ⇽--- 获取随机的一批真实图像
gen_imgs = generator.predict(z)
d_loss_real = discriminator.train_on_batch(imgs, real) ⇽--- 图像像素缩放到[0,1]
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss, accuracy = 0.5 * np.add(d_loss_real, d_loss_fake)
z = np.random.normal(0, 1, (batch_size, 100)) ⇽--- 生成一批伪图像
gen_imgs = generator.predict(z)
g_loss = gan.train_on_batch(z, real) ⇽--- 训练鉴别器
if (iteration + 1) % sample_interval == 0:
losses.append((d_loss, g_loss))
accuracies.append(100.0 * accuracy) ⇽--- 生成一批伪图像训练生成器
iteration_checkpoints.append(iteration + 1)
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % ⇽--- 输出训练过程
(iteration + 1, d_loss, 100.0 * accuracy, g_loss))
sample_images(generator) ⇽--- 输出生成图像的采样
3.4.6 输出样本图像
在生成器训练代码中,你可能注意到调用了 sample_images()函数。该函数在每次sample_interval迭代中调用,并输出由生成器在给定迭代中合成的含有4×4幅合成图像的网格,如清单3.7所示。运行模型后,你可以使用这些图像检查临时和最终的输出情况。
清单3.7 显示合成图像
def sample_images(generator, image_grid_rows=4, image_grid_columns=4):
z = np.random.normal(0, 1, (image_grid_rows * image_grid_columns, z_dim)) ⇽--- 样本随机噪声
gen_imgs = generator.predict(z) ⇽--- 从随机噪声生成图像
gen_imgs = 0.5 * gen_imgs + 0.5 ⇽--- 将图像像素值重缩放至[0, 1]内
fig, axs = plt.subplots(image_grid_rows, ⇽--- 设置图像网格
image_grid_columns,
figsize=(4, 4),
sharey=True,
sharex=True)
cnt = 0
for i in range(image_grid_rows):
for j in range(image_grid_columns):
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray') ⇽--- 输出一个图像网格
axs[i, j].axis('off')
cnt += 1
3.4.7 运行模型
这是最后一步,如清单3.8所示,设置训练超参数——迭代次数和批量大小,然后训练模型。目前没有一种行之有效的方法来确定正确的迭代次数或正确的批量大小,只能观察训练进度,通过反复试验来确定。
也就是说,对这些数有一些重要的实际限制:每个小批量必须足够小,以适合内存器处理(典型使用的批量大小是2的幂:32、64、128、256和512)。迭代次数也有一个实际的限制:拥有的迭代次数越多,训练过程花费的时间就越长。像GAN这样复杂的深度学习模型,即使有了强大的计算能力,训练时长也很容易变得难以控制。
为了确定合适的迭代次数,你需要监控训练损失,并在损失达到平稳状态(这意味着我们从进一步的训练中得到的改进增量很少,甚至没有)的次数附近设置迭代次数。(因为这是一个生成模型,像有监督的学习算法一样,也需要担心过拟合问题。)
清单3.8 运行模型
iterations = 20000 ⇽--- 设置训练超参数 batch_size = 128 sample_interval = 1000 train(iterations, batch_size, sample_interval) ⇽--- 训练GAN直到指定迭代次数
3.4.8 检查结果(略)
本文截选自《GAN实战》
 本书主要介绍构建和训练生成对抗网络(GAN)的方法。全书共12 章,先介绍生成模型以及GAN 的工作原理,并概述它们的潜在用途,然后探索GAN 的基础结构(生成器和鉴别器),引导读者搭建一个简单的对抗系统。
本书主要介绍构建和训练生成对抗网络(GAN)的方法。全书共12 章,先介绍生成模型以及GAN 的工作原理,并概述它们的潜在用途,然后探索GAN 的基础结构(生成器和鉴别器),引导读者搭建一个简单的对抗系统。
本书给出了大量的示例,教读者学习针对不同的场景训练不同的GAN,进而完成生成高分辨率图像、实现图像到图像的转换、生成对抗样本以及目标数据等任务,让所构建的系统变得智能、有效和快速。