1.项目数据及源码
可在github下载:
https://github.com/chenshunpeng/Handwritten-numeral-generation-based-on-GAN
2.GAN介绍
参考自:传送门
先介绍一下生成模型(Generative model)与判别模型(Discriminative mode)的概念:
- 生成模型:对联合概率进行建模,从统计的角度表示数据的分布情况,刻画数据是如何生成的,收敛速度快,例如朴素贝叶斯,GDA,HMM等
- 判别模型:对条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X)进行建模,不关心数据如何生成,主要是寻找不同类别之间的最优分类面,例如LR,SVM等
判别模型在深度学习乃至机器学习领域取得了巨大成功,其本质是将样本的特征向量映射成对应的label;而生成模型由于需要大量的先验知识去对真实世界进行建模,且先验分布的选择直接影响模型的性能,因此此前人们更多关注于判别模型方法
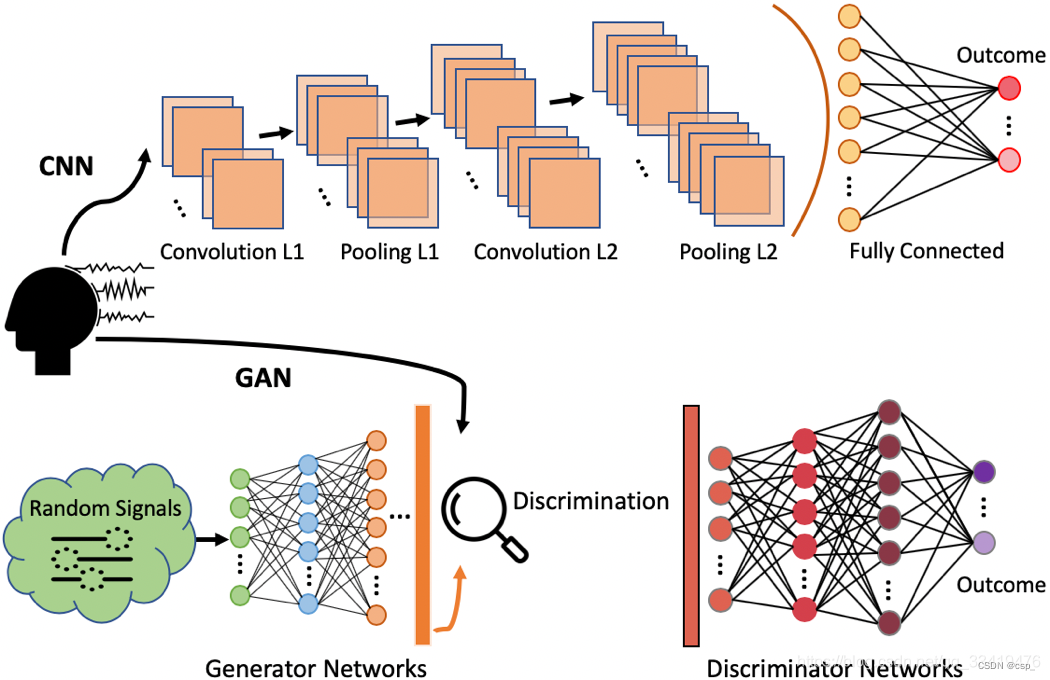
生成式对抗网络(Generative Adversarial Networks,GAN)是蒙特利尔大学的Goodfellow Ian于2014年提出的一种生成模型, 在之后引起了业内人士的广泛关注与研究
GAN中包含了两个模型,一个是生成模型 G G G ,另一个是判别模型 D D D ,下面通过一个生成图片的例子来解释两个模型的作用:
- 生成模型 G G G :不断学习训练集中真实数据的概率分布,目标是将输入的随机噪声转化为可以以假乱真的图片(生成的图片与训练集中的图片越相似越好)
- 判别模型 D D D :判断一个图片是否是真实的图片,目标是将生成模型 G G G 产生的“假”图片与训练集中的“真”图片分辨开
GAN的实现方法是让 D D D 和 G G G 进行博弈,训练过程中通过相互竞争让这两个模型同时得到增强。由于判别模型 D D D 的存在,使得 G G G 在没有大量先验知识以及先验分布的前提下也能很好的去学习逼近真实数据,并最终让模型生成的数据达到以假乱真的效果(即 D D D 无法区分 G G G 生成的图片与真实图片,从而 G G G 和 D D D 达到某种纳什均衡)
示意图如下:
3.设计网络并训练
3.1.定义训练参数
设置GPU环境
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
# 打印显卡信息,确认GPU可用
print(gpus)
设置参数
from tensorflow.keras import layers, datasets, Sequential, Model, optimizers
from tensorflow.keras.layers import LeakyReLU, UpSampling2D, Conv2D
import matplotlib.pyplot as plt
import numpy as np
import sys,os,pathlib
# 定义图像大小(28, 28, 1),输入噪声大小200*1
img_shape = (28, 28, 1)
latent_dim = 200
3.2.构建判别器和生成器
构建生成器,输入一串随机数字,之后生成图片
整个tf.layer.dense()参数如下:
注意定义第一层的时候需要制定数据输入的形状,即input_dim,这样才能让数据正常传进网络
dense(
inputs, #tf.layers.dense 的Tensor输入,该层的输入
units, #整数或长整数,输出空间的维数,输出的大小(维数),整数或long
activation=None, #激活功能(可调用),将其设置为“None”以保持线性激活
use_bias=True,#Boolean,表示该层是否使用偏差;使用bias为True(默认使用),不用bias改成False即可
kernel_initializer=None,#权重矩阵的初始化函数;如果为None(默认),则使用tf.get_variable
bias_initializer=tf.zeros_initializer(),#偏置的初始化函数
kernel_regularizer=None,#权重矩阵的正则化函数
bias_regularizer=None,#正规函数的偏差
activity_regularizer=None,#输出的正则化函数
trainable=True,#Boolean,如果为True,还将变量添加到图集合
name=None,#String,图层的名称;具有相同名称的图层将共享权重,但为了避免错误,在这种情况下,我们需要reuse=True
reuse=None#Boolean,是否以同一名称重用前一层的权重
)
np.prod()函数用来计算所有元素的乘积,对于有多个维度的数组可以指定轴(如axis=1指定计算每一行的乘积)
代码:
def build_generator():
model = Sequential([
layers.Dense(256, input_dim=latent_dim), # 全连接层,节点大小是256
layers.LeakyReLU(alpha=0.2), # 激活函数
layers.BatchNormalization(momentum=0.8), # 归一化
layers.Dense(512),
layers.LeakyReLU(alpha=0.2),
layers.BatchNormalization(momentum=0.8),
layers.Dense(1024),
layers.LeakyReLU(alpha=0.2),
layers.BatchNormalization(momentum=0.8),
layers.Dense(np.prod(img_shape), activation='tanh'),
layers.Reshape(img_shape)
])
noise = layers.Input(shape=(latent_dim,)) # 输入的初始图层
img = model(noise)
return Model(noise, img)
构建判别器,判别输入图片的真假
keras.layers.Flatten()用于将输入层的数据压成一维的数据,一般用在卷积层和全连接层之间(因为全连接层只能接收一维数据,而卷积层可以处理二维数据,就是全连接层处理的是向量,而卷积层处理的是矩阵),在这里把(28, 28, 1)压缩成(784, 1)
代码
def build_discriminator():
model = Sequential([
layers.Flatten(input_shape=img_shape),
layers.Dense(512),
layers.LeakyReLU(alpha=0.2),
layers.Dense(256),
layers.LeakyReLU(alpha=0.2),
layers.Dense(1, activation='sigmoid')
])
img = layers.Input(shape=img_shape)
validity = model(img)
return Model(img, validity)
3.3.构建模型
# 创建判别器
discriminator = build_discriminator()
# 定义优化器
optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# 创建生成器
generator = build_generator()
gan_input = layers.Input(shape=(latent_dim,))
img = generator(gan_input)
# 在训练generate的时候不训练discriminator
discriminator.trainable = False
# 对生成的假图片进行预测
validity = discriminator(img)
combined = Model(gan_input, validity)
combined.compile(loss='binary_crossentropy', optimizer=optimizer)
查看参数类型:
3.4.查看mnist数据集图片
本例判别器是以mnist数据集为模板的,其加载方法可看:Pythontf.keras.datasets.mnist.load_data用法及代码示例
tf.keras.datasets.mnist.load_data()的返回值是NumPy数组元组:(x_train, y_train), (x_test, y_test)
(train_images1,_), (_,_) = tf.keras.datasets.mnist.load_data()
from matplotlib import pyplot
import numpy as np
pyplot.imshow(train_images1[0].reshape((28, 28)), cmap="gray")
print(train_images1[0].shape)
输出:
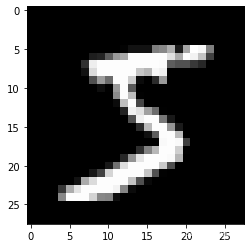
3.5.进行训练
定义保存样例图片的函数:
def sample_images(epoch):
"""
保存样例图片
"""
row, col = 4, 4
noise = np.random.normal(0, 1, (row*col, latent_dim))
gen_imgs = generator.predict(noise)
fig, axs = plt.subplots(row, col)
cnt = 0
for i in range(row):
for j in range(col):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%05d.png" % epoch)
plt.close()
定义训练函数:
def train(epochs, batch_size=128, sample_interval=50):
# 加载数据
# 文件位置:C:\Users\HP ZBook15\.keras\datasets
(train_images,_), (_,_) = tf.keras.datasets.mnist.load_data()
# 将图片标准化到 [-1, 1] 区间内
train_images = (train_images - 127.5) / 127.5
# 数据
train_images = np.expand_dims(train_images, axis=3)
# 创建标签
true = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
# 进行循环训练
for epoch in range(epochs):
# 随机选择 batch_size 张图片
idx = np.random.randint(0, train_images.shape[0], batch_size)
imgs = train_images[idx]
# 生成噪音
noise = np.random.normal(0, 1, (batch_size, latent_dim))
# 生成器通过噪音生成图片,gen_imgs的shape为:(128, 28, 28, 1)
gen_imgs = generator.predict(noise)
# 训练鉴别器
d_loss_true = discriminator.train_on_batch(imgs, true)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
# 返回loss值
d_loss = 0.5 * np.add(d_loss_true, d_loss_fake)
# 训练生成器
noise = np.random.normal(0, 1, (batch_size, latent_dim))
g_loss = combined.train_on_batch(noise, true)
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# 保存样例图片
if epoch % sample_interval == 0:
sample_images(epoch)
进行训练:
train(epochs=50000, batch_size=512, sample_interval=500)
结果:
16/16 [==============================] - 1s 3ms/step
0 [D loss: 0.564433, acc.: 55.57%] [G loss: 0.615958]
1/1 [==============================] - 0s 87ms/step
16/16 [==============================] - 0s 2ms/step
1 [D loss: 0.428365, acc.: 61.04%] [G loss: 0.601898]
16/16 [==============================] - 0s 2ms/step
2 [D loss: 0.390525, acc.: 64.84%] [G loss: 0.629429]
16/16 [==============================] - 0s 2ms/step
3 [D loss: 0.376864, acc.: 69.53%] [G loss: 0.637371]
16/16 [==============================] - 0s 2ms/step
4 [D loss: 0.368233, acc.: 70.31%] [G loss: 0.672757]
16/16 [==============================] - 0s 2ms/step
5 [D loss: 0.353537, acc.: 74.02%] [G loss: 0.707676]
.....
16/16 [==============================] - 0s 2ms/step
49995 [D loss: 0.703495, acc.: 51.46%] [G loss: 0.787212]
16/16 [==============================] - 0s 2ms/step
49996 [D loss: 0.684776, acc.: 57.23%] [G loss: 0.798816]
16/16 [==============================] - 0s 2ms/step
49997 [D loss: 0.706813, acc.: 50.78%] [G loss: 0.793404]
16/16 [==============================] - 0s 2ms/step
49998 [D loss: 0.703113, acc.: 50.10%] [G loss: 0.774067]
16/16 [==============================] - 0s 2ms/step
49999 [D loss: 0.694413, acc.: 53.81%] [G loss: 0.783364]
4.显示结果
绘制动图:
import imageio
def compose_gif():
# 图片地址
data_dir = r"E:\demo_study\jupyter\Jupyter_notebook\Handwritten-numeral-generation-based-on-GAN\images"
data_dir = pathlib.Path(data_dir)
paths = list(data_dir.glob('*'))
k = 0
gif_images = []
for path in paths:
# print(path)
k = k + 1
if k%2 == 1:
gif_images.append(imageio.imread(path))
imageio.mimsave("test.gif",gif_images,fps=4)
compose_gif()
结果:

后期比较清晰的图片:

