目录
mysql为什么要合理使用数据结构?
数据存储在mysql数据库磁盘位置是无序的,是不均匀分布的,为了解决持续的io流消耗问题,就必须使用合理的数据结构
索引是帮助mysql高效获取数据的排好序的数据结构
索引数据结构选型:
mysql默认使用B+Tree,5.5版本之前使用B-Tree
二叉树
定义:每个结点不超过2的有序树,是每个节点最多有两个子树的树结构。顶上的叫根结点,两边被称作“左子树”和“右子树”。
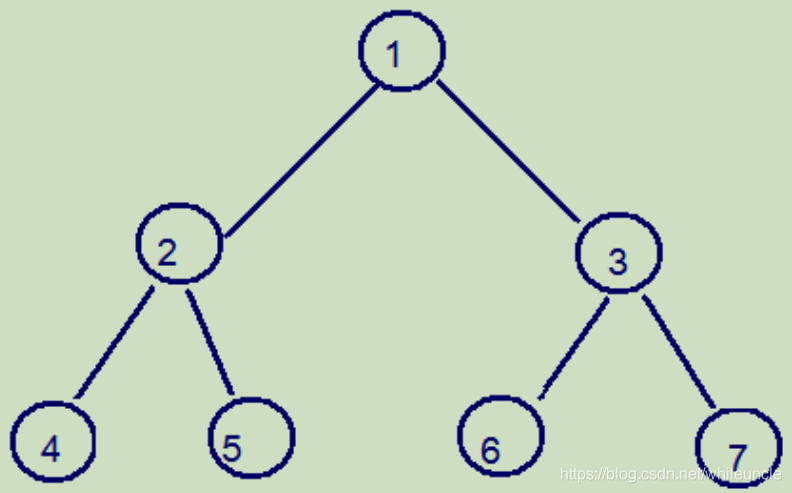
为什么mysql不使用二叉树?
像如上二叉树结构图,插入多条记录,右边会单边增加根节点,树的高度增加,查询减慢,不使用,比如主键
红黑树
定义:本身就是一种特殊的二叉树,每个节点上都有存储位表示节点的颜色,可以是red或black
约束:每个节点是黑色或者红色,根节点为黑色,叶子节点(特指空节点)是黑色,每个红色节点的子节点都是黑色的,任何一个节点到其每一个叶子节点的所有路径上黑色节点数相同
特点:速度特别快,趋近平衡树,查找叶子元素最少和最多次数不多余二倍
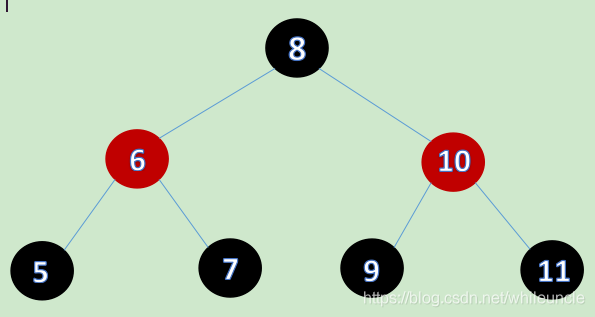
为什么mysql不使用红黑树?
当mysql数据量很大时,增加一条记录,数据需要平衡一次,非常消耗性能
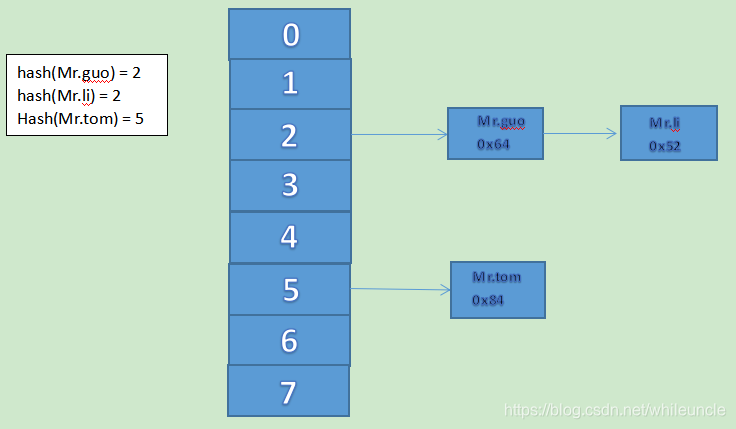
hash(mysql可选择此结构):
对于索引key进行一次hash计算就可以定位出数据存储的位置,有时候B+Tree索引更加高效,仅能满足 '=','in',不支持范围查询会出现hash冲突问题
hash值:是一个十进制的整数,有系统随机给出(对象的地址值,是一个逻辑地址,是模拟出来得到地址,不是数据实际存储的物理地址)
B-Tree:
叶节点的指针可以为空,所有索引元素不重复,节点中的数据索引从左到右递增排列
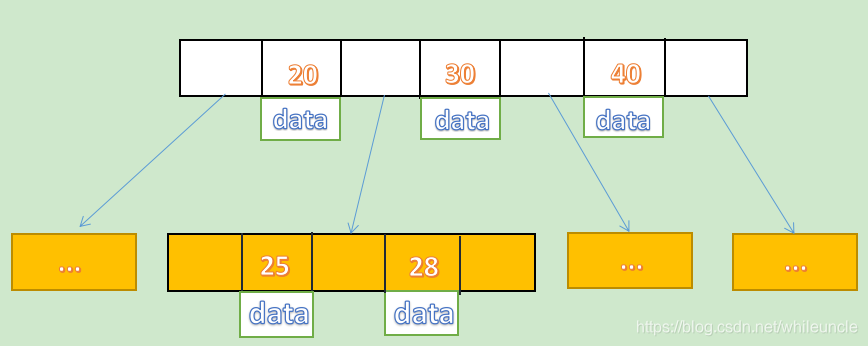
为什么mysql在5.5之后取消了B-Tree?
B树每个节点都存放了真实的数据,mysql一个根节点数据存储为16KB,会导致每一个节点存储的数据量变小,所以B树的高度会变高,维护的代价大,查询修改性能会越来越低
B+Tree(B-Tree变种,mysql默认):
B+Tree特点:非叶子节点不存储data,只存储索引(冗余),可有存放更多的节点,叶子节点包含了所有索引字段,所有的数据都存放在叶子节点上,叶子节点使用指针访问,提升区间访问性能,从左至右递增
mysql对B-Tree做了优化,叶子节点使用双向指针
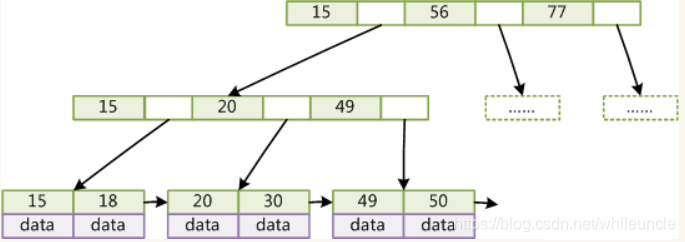
mysql使用b+树根节点存储大点的bigint数据则需要8个字节,以及地址mysql中需要6个字节,一个根节点数据存储16KB数据一个节点大概能存放16 *(8 + 6)= 1170个元素,叶子节点存放16KB数据,假设一个数据1KB,那么高度为3就可以存放1170 * 1170 * 16 = 21902400个数据
数据结构在线演示
在线演示连接:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
我们都知道mysql的数据存储引擎包含了myisam,innerdb,csv等,常用的是myisam,innerdb
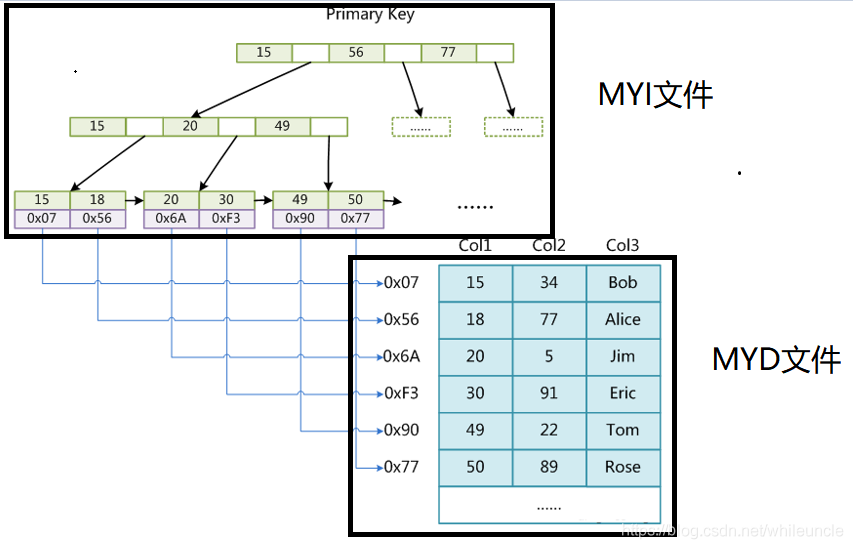
myisam的数据结构
主要特点,myISAM索引文件和数据文件是分离的(非聚集)
MyISAM 存储引擎的一个表有3个文件: *.frm 文件存储的表的结构; *.MYD 文件存储表的数据; *.MYI 文件存储表中的索引数据;
MYISAM 存储引擎的主键索引 和 非主键索引的存储是差不多的
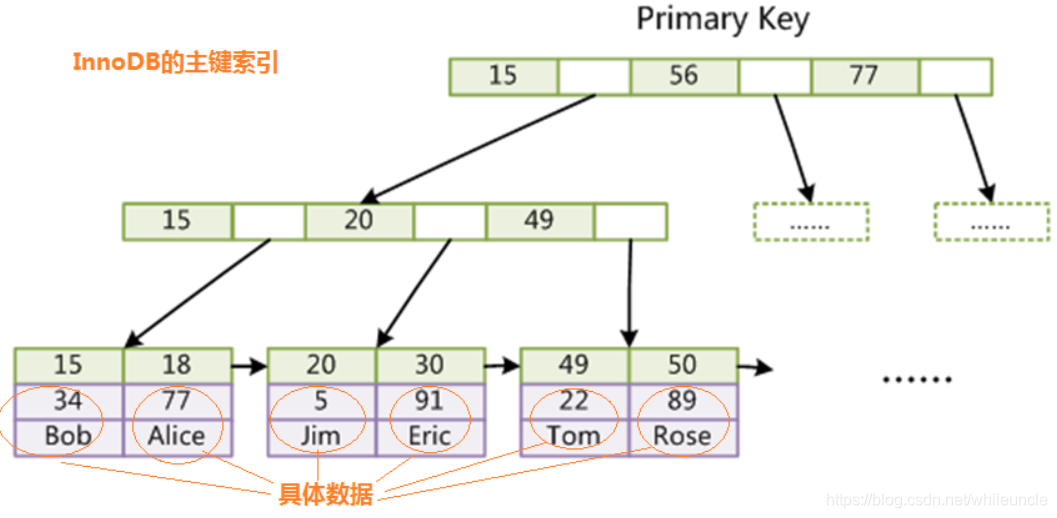
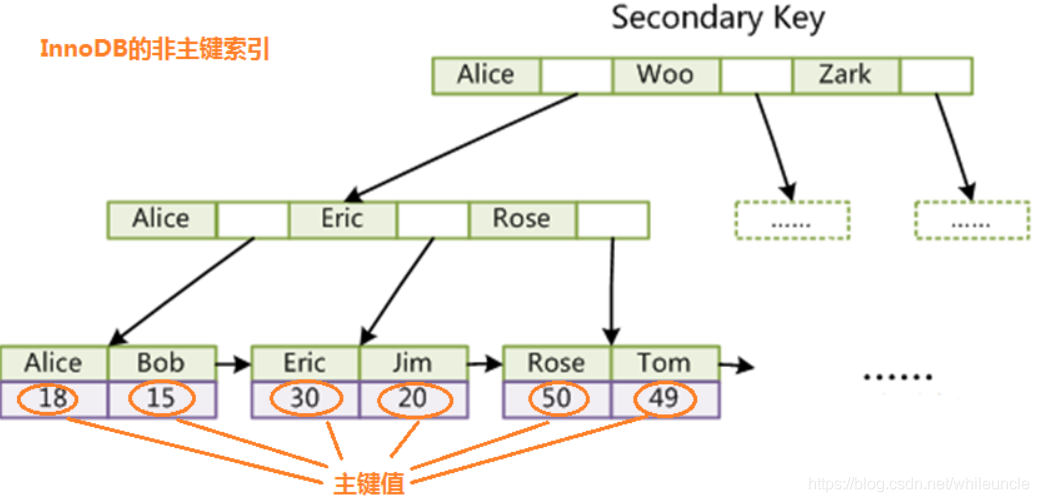
innerDB数据结构
innerDB主键索引叶节点包含了完整的数据记录,二级索引的叶子节点存储主键,对应主键索引的根节点
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
innerdb 如果一张表中没有主键,则会选择一列不是相等的一列作为主键,如果存在相等的一列,则会自己建立新的一列帮你维护整张表的数据,如果不建立主键,就会消耗资源
如果不是自增的,插入一个中间大小的数据,会将部分叶节点和根节点进行排序,如果是自增的,则会在最后叶节点插入数据。根节点改变的反而小
为什么非主键索引结构叶子节点存储的是主键值?
数据的一致性,节省存储空间
innerDB主键索引:
innerDB非主键索引:
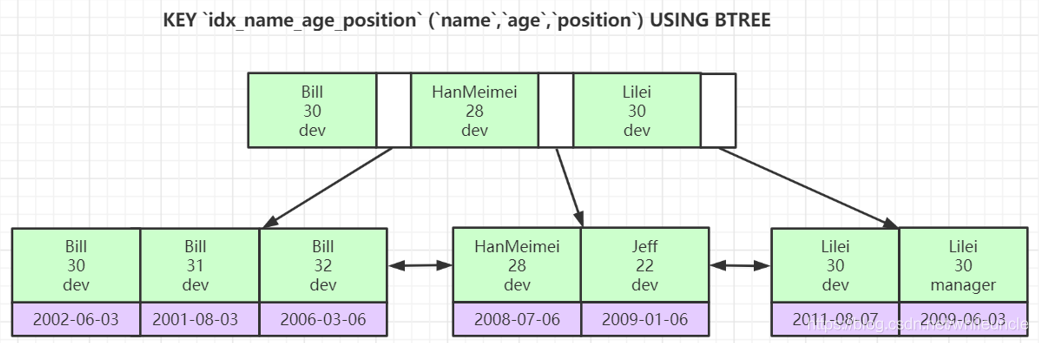
联合索引底层结构
联合索引根据建表的先后顺序先后建立索引排序顺序,比较相等时,先比较第一列的值,如果相等,再继续比较第二列,以此类推。
联合索引的索引字段中有一个值为null,则将其放在叶子节点的最前面;可以认为null值是最小的。
我之前面试被问到name,age,position建立了索引,单独使用会起作用吗?联想到MongoDB索引会,觉得会,就说会了,其实是只有name会使用到,其他的单独不会使用到索引
mysql联合索引的作用范围?
使用联合索引时,索引列的定义顺序将会影响到最终查询时索引的使用情况。例如联合索引(a,b,c),mysql会从最左边的列优先匹配,如果最左边的带头大哥没有使用到,在未使用覆盖索引的情况下,就只能全表扫描,如果遇到 > < between等这样的范围查询,那B+树中也就无法对下一列进行等值匹配了,注意字符串也必须使用单引号做判断,否则也无法作比较