索引
索引是帮助MySQL高效获取数据的排好序的数据结构(容易忽略的点:排好序)(形象点就是教科书的目录)
索引存储在文件里(也就是说有IO操作)
索引结构:
这里说说在几种数据结构中,mysql为什么选择hash,B+Tree
- 二叉树
- 红黑树
- hash
- BTree
首先,如果数据没有索引,那么我们读取数据是这样的
这里有一篇很好的硬盘存取原理文章,看完更容易理解: https://www.cnblogs.com/leezhxing/p/4420988.html
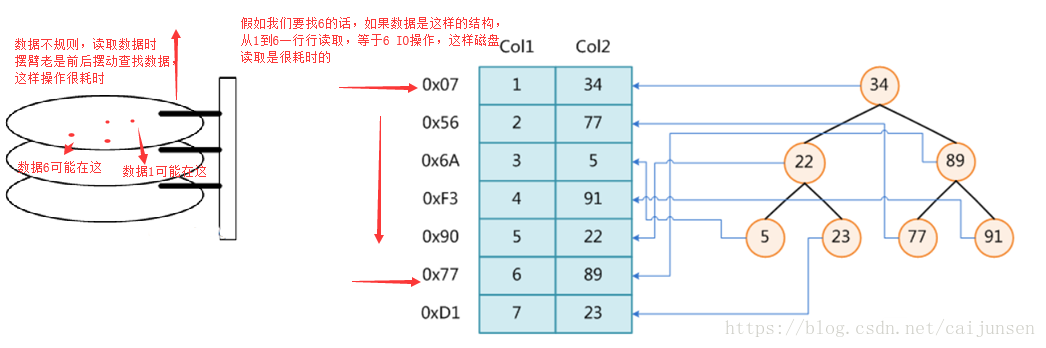
上面我们发现读取数据特别耗时,那有没有比较节时的数据结构,我们可以看看二叉树
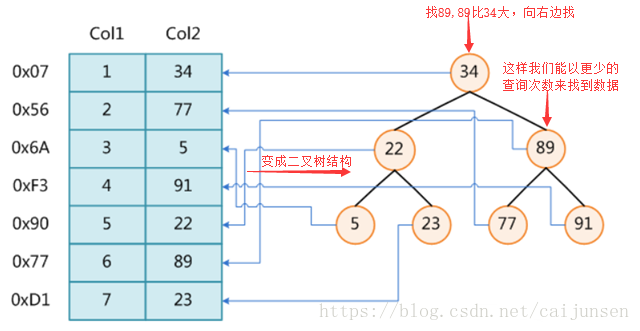
上面虽然优化了,但是mysql为什么选择 B+Tree
这里介绍一个动态演示数据结构的网址:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
二叉树与红黑树的比较
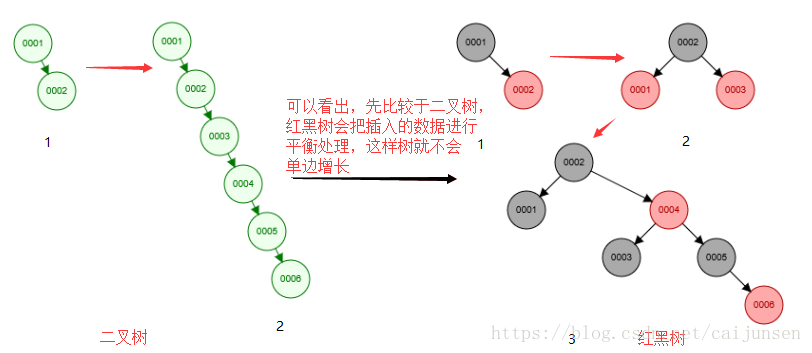
从上面我们发现,红黑树相比较于二叉树又进步了一些,但红黑树还是有些问题:那就是数据量大的话,红黑树的深度会很深,也就是说深度不可控,这样一来查找数据还是会很耗时
HASH

从上面我们发现,相比较于红黑树,hash可以固定“深度”,且映射到磁盘存储引用,这样查找数据直接告诉磁盘数据在哪,查找数据也挺快的,但是 hash 还是有些不足:那就是不能范围查找,比如我们查找Col1>1的数据,当然如果我们查询操作很少的话,我们也可以选择hash数据结构,因为它查找数据挺快的,这也是mysql的索引方法除了B+Tree还有hash
BTree
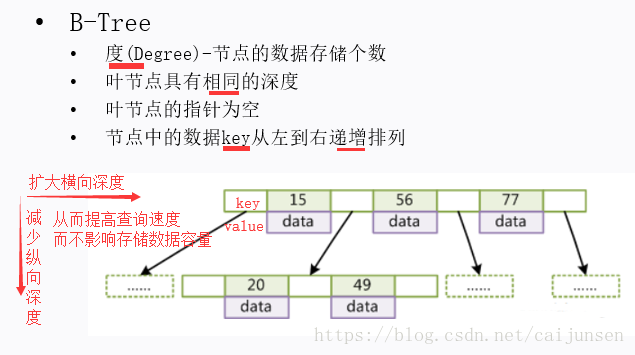
从上面看,我们发现BTree又进步了一些,查询速度提高,存储容量也没影响到。当然有人可能会这样想,那我们为什么不把数据全部都存在一个节点,这样深度不就是1了吗?
当然不行了!java拿取数据一般是这样的:java程序-->CPU--->内存---->硬盘,而内存与硬盘的交互是有大小限制的,是一页数据4k左右,所以不能把所有数据都放在一个节点来获取,一般来说节点会尽量预存4K容量。
看到这里,我们知道(4K=节点;节点=小节点*小节点的容量)一个节点是4K,而节点内有几个小节点,那么也就是说,只要我们每个的小节点的data容量越小,那么可以存的节点也就可以更多。
B+Tree
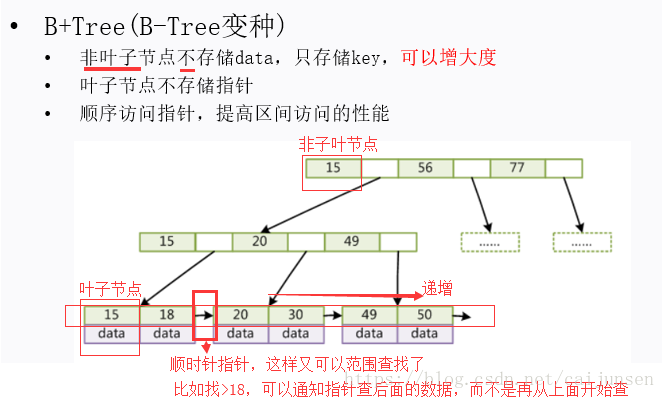
B+Tree通过把data不放在非叶子节点来增加度(小节点),一般会一百个以上使得深度是3~5,从而减少查询次数。并且,叶子节点之间会有指针,数据又是递增的,这使得我们范围查找可以通过指针连接查找,而不再从上面节点往下一个个找。
结论:B+Tree 既减少查询次数又提供了很好的范围查询
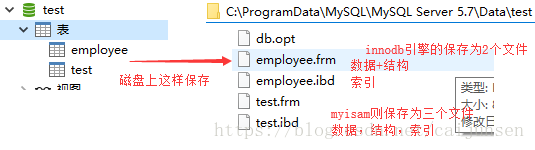
MyISAM索引实现(非聚集)
MyISAM索引文件和数据文件是分离的,文章一开始也介绍了,数据.MYD+结构.frm+索引.MYI三个文件
那myisam的索引是什么样的?
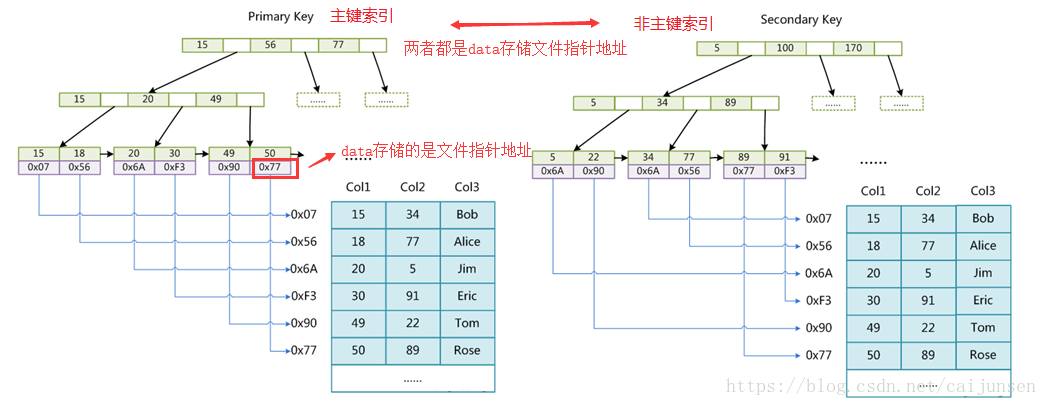
InnoDB索引实现(聚集)
- 数据文件本身就是索引文件
- 表数据文件本身就是按B+Tree组织的一个索引结构文件
- 聚集索引-叶节点包含了完整的数据记录
- 为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
- 为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
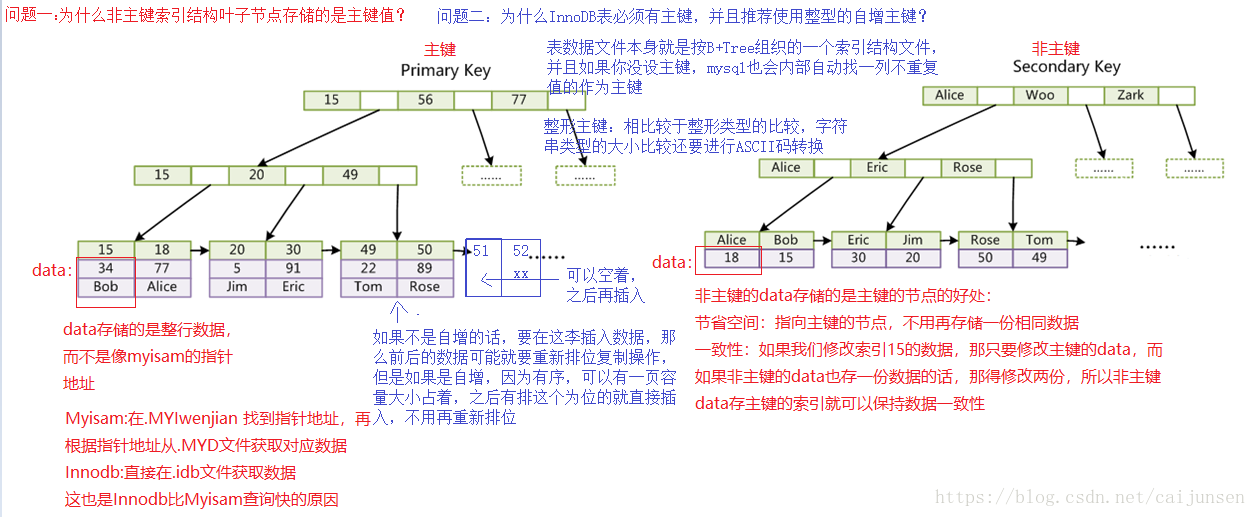
上面的问题对应字体颜色说明 (可能说的有些乱,可以参考这个的描述:https://baijiahao.baidu.com/s?id=1567647881305129&wfr=spider&for=pc)
联合索引的底层存储结构
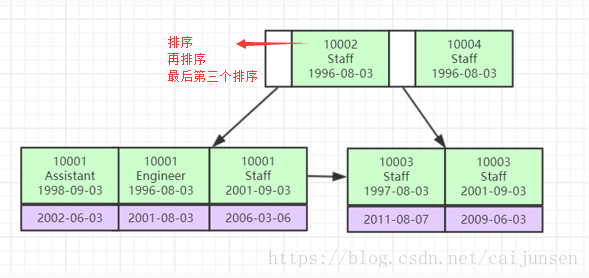
练习题
在employee表建联合索引 (emp_no,title,from_date)
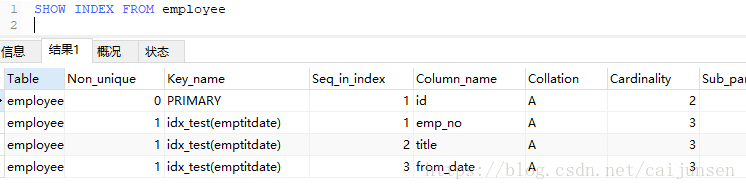
分析以下几条sql的索引使用情况
SELECT * from employee where emp_no = '10001' and title = 'xxx' and from_date = '2018-10-01 11:29:51'
SELECT * from employee where title = 'sss'
SELECT * from employee where emp_no > '10003'
SELECT * from employee where emp_no > '10003' and title = 'eeee'
SELECT * from employee where emp_no > '10003' ORDER BY title
#自己可以根据联合索引的数据结构猜猜看也可以用explain来查看